Federated Domain-Specific Knowledge Transfer on Large Language Models Using Synthetic Data

0
🔄
Sign in to get full access
Overview
- Large language models (LLMs) have demonstrated exceptional performance and versatility, leading to their widespread integration in various applications.
- In sensitive domains, such as those described in federated learning scenarios, directly using external LLMs on private data is prohibited due to strict data security and privacy regulations.
- Local clients seek to leverage LLMs to improve their domain-specific small language models (SLMs), which often have limited computational resources and domain-specific data.
- Existing methods focus on using public data or LLMs to generate more data and transfer knowledge from LLMs to SLMs, but these approaches struggle to yield substantial improvements due to the discrepancies between the generated data and the clients' domain-specific data.
Plain English Explanation
Large AI language models have become incredibly capable at understanding and generating human-like text. These models, known as large language models (LLMs), are now widely used in various applications. However, when it comes to sensitive domains, such as healthcare or finance, directly using external LLMs on private data is strictly prohibited due to strict data privacy and security regulations.
For local clients, such as individual businesses or organizations, the goal is to use these powerful LLMs to improve their own, more specialized language models, known as small language models (SLMs). SLMs often have limited computational resources and are trained on a smaller, domain-specific dataset. By leveraging the knowledge and capabilities of LLMs, clients hope to enhance the performance of their SLMs.
Previous approaches have tried to achieve this by using public data or the LLMs themselves to generate more training data, and then transferring this knowledge to the SLMs. However, these methods have struggled to yield significant improvements because the generated data doesn't always match the specific characteristics of the clients' domain-specific data.
Technical Explanation
To address this challenge, the researchers introduce a Federated Domain-specific Knowledge Transfer (FDKT) framework. The key insight of FDKT is to leverage LLMs to augment data based on domain-specific "few-shot demonstrations" – synthetic samples that are generated from the clients' private data using differential privacy techniques.
These synthetic samples share a similar data distribution with the clients' private data, allowing the server-side LLM to generate more relevant knowledge that can better improve the clients' SLMs. The extensive experimental results demonstrate that the proposed FDKT framework consistently and significantly improves the task performance of SLMs by around 5%, even with a privacy budget of less than 10.
Critical Analysis
The FDKT framework presents a novel approach to leveraging the power of LLMs while preserving client data privacy. By using differentially private synthetic samples, the method addresses the discrepancy between generated data and clients' domain-specific data that plagued previous approaches.
However, the paper does not provide a detailed analysis of the potential limitations of the FDKT framework. For example, it would be important to understand how the choice of privacy budget and the quality of the synthetic samples might impact the final performance of the SLMs. Additionally, the paper does not explore the scalability of the approach as the number of clients or the complexity of the domains increase.
Further research could also investigate the potential for public LLMs to help with private tasks and how to effectively fine-tune LLMs for domain-specific tasks while preserving privacy.
Conclusion
The FDKT framework presented in this paper offers a promising approach to leveraging the power of LLMs to improve domain-specific SLMs, while preserving the privacy of clients' sensitive data. By using differentially private synthetic samples to bridge the gap between LLMs and clients' data, the framework demonstrates significant improvements in SLM performance, with potential applications in a wide range of sensitive domains. As the field of supervised knowledge transfer to LLMs continues to evolve, the FDKT framework provides a valuable contribution to the ongoing effort to harness the capabilities of LLMs in a privacy-preserving manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Federated Domain-Specific Knowledge Transfer on Large Language Models Using Synthetic Data
Haoran Li, Xinyuan Zhao, Dadi Guo, Hanlin Gu, Ziqian Zeng, Yuxing Han, Yangqiu Song, Lixin Fan, Qiang Yang
As large language models (LLMs) demonstrate unparalleled performance and generalization ability, LLMs are widely used and integrated into various applications. When it comes to sensitive domains, as commonly described in federated learning scenarios, directly using external LLMs on private data is strictly prohibited by stringent data security and privacy regulations. For local clients, the utilization of LLMs to improve the domain-specific small language models (SLMs), characterized by limited computational resources and domain-specific data, has attracted considerable research attention. By observing that LLMs can empower domain-specific SLMs, existing methods predominantly concentrate on leveraging the public data or LLMs to generate more data to transfer knowledge from LLMs to SLMs. However, due to the discrepancies between LLMs' generated data and clients' domain-specific data, these methods cannot yield substantial improvements in the domain-specific tasks. In this paper, we introduce a Federated Domain-specific Knowledge Transfer (FDKT) framework, which enables domain-specific knowledge transfer from LLMs to SLMs while preserving clients' data privacy. The core insight is to leverage LLMs to augment data based on domain-specific few-shot demonstrations, which are synthesized from private domain data using differential privacy. Such synthetic samples share similar data distribution with clients' private data and allow the server LLM to generate particular knowledge to improve clients' SLMs. The extensive experimental results demonstrate that the proposed FDKT framework consistently and greatly improves SLMs' task performance by around 5% with a privacy budget of less than 10, compared to local training on private data.
Read more5/24/2024

0
FedMKT: Federated Mutual Knowledge Transfer for Large and Small Language Models
Tao Fan, Guoqiang Ma, Yan Kang, Hanlin Gu, Yuanfeng Song, Lixin Fan, Kai Chen, Qiang Yang
Recent research in federated large language models (LLMs) has primarily focused on enabling clients to fine-tune their locally deployed homogeneous LLMs collaboratively or on transferring knowledge from server-based LLMs to small language models (SLMs) at downstream clients. However, a significant gap remains in the simultaneous mutual enhancement of both the server's LLM and clients' SLMs. To bridge this gap, we propose FedMKT, a parameter-efficient federated mutual knowledge transfer framework for large and small language models. This framework is designed to adaptively transfer knowledge from the server's LLM to clients' SLMs while concurrently enriching the LLM with clients' unique domain insights. We facilitate token alignment using minimum edit distance (MinED) and then selective mutual knowledge transfer between client-side SLMs and a server-side LLM, aiming to collectively enhance their performance. Through extensive experiments across three distinct scenarios, we evaluate the effectiveness of FedMKT using various public LLMs and SLMs on a range of NLP text generation tasks. Empirical results demonstrate that FedMKT simultaneously boosts the performance of both LLMs and SLMs.
Read more6/19/2024

0
Safely Learning with Private Data: A Federated Learning Framework for Large Language Model
JiaYing Zheng, HaiNan Zhang, LingXiang Wang, WangJie Qiu, HongWei Zheng, ZhiMing Zheng
Private data, being larger and quality-higher than public data, can greatly improve large language models (LLM). However, due to privacy concerns, this data is often dispersed in multiple silos, making its secure utilization for LLM training a challenge. Federated learning (FL) is an ideal solution for training models with distributed private data, but traditional frameworks like FedAvg are unsuitable for LLM due to their high computational demands on clients. An alternative, split learning, offloads most training parameters to the server while training embedding and output layers locally, making it more suitable for LLM. Nonetheless, it faces significant challenges in security and efficiency. Firstly, the gradients of embeddings are prone to attacks, leading to potential reverse engineering of private data. Furthermore, the server's limitation of handle only one client's training request at a time hinders parallel training, severely impacting training efficiency. In this paper, we propose a Federated Learning framework for LLM, named FL-GLM, which prevents data leakage caused by both server-side and peer-client attacks while improving training efficiency. Specifically, we first place the input block and output block on local client to prevent embedding gradient attacks from server. Secondly, we employ key-encryption during client-server communication to prevent reverse engineering attacks from peer-clients. Lastly, we employ optimization methods like client-batching or server-hierarchical, adopting different acceleration methods based on the actual computational capabilities of the server. Experimental results on NLU and generation tasks demonstrate that FL-GLM achieves comparable metrics to centralized chatGLM model, validating the effectiveness of our federated learning framework.
Read more6/27/2024
0
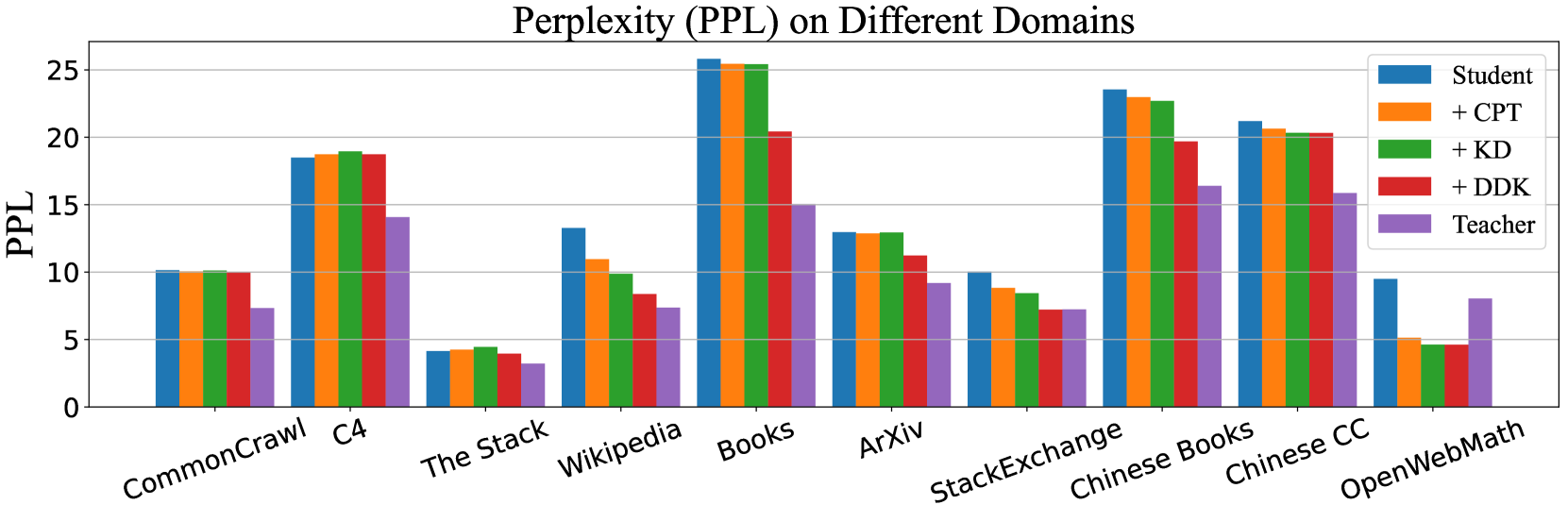
DDK: Distilling Domain Knowledge for Efficient Large Language Models
Jiaheng Liu, Chenchen Zhang, Jinyang Guo, Yuanxing Zhang, Haoran Que, Ken Deng, Zhiqi Bai, Jie Liu, Ge Zhang, Jiakai Wang, Yanan Wu, Congnan Liu, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng
Despite the advanced intelligence abilities of large language models (LLMs) in various applications, they still face significant computational and storage demands. Knowledge Distillation (KD) has emerged as an effective strategy to improve the performance of a smaller LLM (i.e., the student model) by transferring knowledge from a high-performing LLM (i.e., the teacher model). Prevailing techniques in LLM distillation typically use a black-box model API to generate high-quality pretrained and aligned datasets, or utilize white-box distillation by altering the loss function to better transfer knowledge from the teacher LLM. However, these methods ignore the knowledge differences between the student and teacher LLMs across domains. This results in excessive focus on domains with minimal performance gaps and insufficient attention to domains with large gaps, reducing overall performance. In this paper, we introduce a new LLM distillation framework called DDK, which dynamically adjusts the composition of the distillation dataset in a smooth manner according to the domain performance differences between the teacher and student models, making the distillation process more stable and effective. Extensive evaluations show that DDK significantly improves the performance of student models, outperforming both continuously pretrained baselines and existing knowledge distillation methods by a large margin.
Read more7/24/2024