Task Presentation and Human Perception in Interactive Video Retrieval

0
🔍
Sign in to get full access
Overview
- This paper investigates how the way a video retrieval task is presented to users can impact the difficulty of the task.
- The researchers designed novel task presentation modes, built the necessary processing pipelines, and created a custom experimental platform to study these effects.
- They conducted a large crowdsourced experiment and found that the way the target video segment is presented has a substantial influence on the retrieval task difficulty.
- The study also found that people can successfully retrieve a target video segment even when the provided hints are reduced or altered, opening up discussions around future evaluation protocols in interactive media retrieval.
Plain English Explanation
When people use video search systems, it's a back-and-forth process between the user and the retrieval system. However, large-scale evaluations of these systems often don't consider how human factors like perception, attention, and memory can affect the search process.
In this study, the researchers designed new ways to present video retrieval tasks to users, based on ideas about what makes videos memorable. They built the necessary systems to process the target video segments and created a custom platform to run the experiments.
They then conducted a large crowdsourced study to see how the different task presentation modes affected how difficult the retrieval tasks were. The key finding was that the way the target video was shown to users had a big impact on how hard it was for them to find it.
Interestingly, the researchers also found that people could still successfully retrieve the target video even if some of the helpful hints were reduced or changed. This opens up discussions about how we should evaluate these video search systems in the future, to better reflect real-world usage.
Technical Explanation
The researchers designed novel task presentation modes for video retrieval based on concepts in media memorability. They implemented the necessary processing pipelines and built a custom experimental platform to study the effects of these different task representation schemes.
In the crowdsourced experiment, participants were asked to retrieve target video segments using various task presentation modes. The researchers found that the way the target was presented had a substantial influence on the difficulty of the retrieval task.
Specifically, they observed that participants could successfully retrieve the target video even when the provided hints were reduced or altered. This suggests that users are able to leverage their own perception, attention, and memory to overcome limitations in the task representation.
These findings have implications for the design of future evaluation protocols in the domain of interactive media retrieval. The researchers argue that existing setups may not accurately reflect realistic retrieval scenarios, and that incorporating human factors is crucial for developing more effective and user-friendly video search systems.
Critical Analysis
The paper provides valuable insights into how task presentation can impact the difficulty of video retrieval tasks. By considering human factors like perception, attention, and memory, the researchers have highlighted important limitations in existing evaluation protocols for media retrieval systems.
One potential caveat is that the crowdsourced experiment was conducted in a controlled laboratory setting, which may not fully capture the complexities of real-world video search scenarios. Further research is needed to understand how these findings translate to more ecologically valid settings.
Additionally, the paper does not delve deeply into the specific cognitive mechanisms underlying the participants' ability to retrieve the target video despite reduced or altered hints. Future studies could investigate these cognitive processes in more detail to provide a richer understanding of the phenomenon.
Overall, this research represents an important step towards developing more user-centric and realistic evaluation frameworks for interactive video retrieval systems. By considering the human factors involved, the researchers have opened up new avenues for improving the design and assessment of these technologies.
Conclusion
This paper explores how the presentation of video retrieval tasks can significantly influence the difficulty experienced by users. By designing novel task representation modes and conducting a large-scale crowdsourced experiment, the researchers found that the way the target video segment is shown to users has a substantial impact on the retrieval process.
Importantly, the study also revealed that people can successfully retrieve the target video even when the provided hints are reduced or altered, suggesting that users can leverage their own cognitive abilities to overcome limitations in the task representation. These findings have important implications for the development of more user-centric and realistic evaluation protocols in the domain of interactive media retrieval.
As video search systems become increasingly prevalent, incorporating a deeper understanding of human factors, such as perception, attention, and memory, will be crucial for designing more effective and user-friendly technologies. This research represents an important step in that direction, paving the way for future advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Task Presentation and Human Perception in Interactive Video Retrieval
Nina Willis, Abraham Bernstein, Luca Rossetto
Interactive video retrieval is a cooperative process between humans and retrieval systems. Large-scale evaluation campaigns, however, often overlook human factors, such as the effects of perception, attention, and memory, when assessing media retrieval systems. Consequently, their setups fall short of emulating realistic retrieval scenarios. In this paper, we design novel task presentation modes based on concepts in media memorability, implement the pipelines necessary for processing target video segments, and build a custom experimental platform for the final evaluation. In order to study the effects of different task representation schemes, we conduct a large crowdsourced experiment. Our findings demonstrate that the way in which the target of a video retrieval task is presented has a substantial influence on the difficulty of the retrieval task and that individuals can successfully retrieve a target video segment despite reducing or even altering the provided hints, opening up a discussion around future evaluation protocols in the domain of interactive media retrieval.
Read more5/8/2024
🏋️
0
Multimedia and Immersive Training Materials Influence Impressions of Learning But Not Learning Outcomes
Benjamin A. Clegg, Alex Karduna, Ethan Holen, Jason Garcia, Matthew G. Rhodes, Francisco R. Ortega
Although the use of technologies like multimedia and virtual reality (VR) in training offer the promise of improved learning, these richer and potentially more engaging materials do not consistently produce superior learning outcomes. Default approaches to such training may inadvertently mimic concepts like naive realism in display design, and desirable difficulties in the science of learning - fostering an impression of greater learning dissociated from actual gains in memory. This research examined the influence of format of instructions in learning to assemble items from components. Participants in two experiments were trained on the steps to assemble a series of bars, that resembled Meccano pieces, into eight different shapes. After training on pairs of shapes, participants rated the likelihood they would remember the shapes and then were administered a recognition test. Relative to viewing a static diagram, viewing videos of shapes being constructed in a VR environment (Experiment 1) or viewing within an immersive VR system (Experiment 2) elevated participants' assessments of their learning but without enhancing learning outcomes. Overall, these findings illustrate how future workers might mistakenly come to believe that technologically advanced support improves learning and prefer instructional designs that integrate similarly complex cues into training.
Read more7/9/2024
0
Task-Driven Exploration: Decoupling and Inter-Task Feedback for Joint Moment Retrieval and Highlight Detection
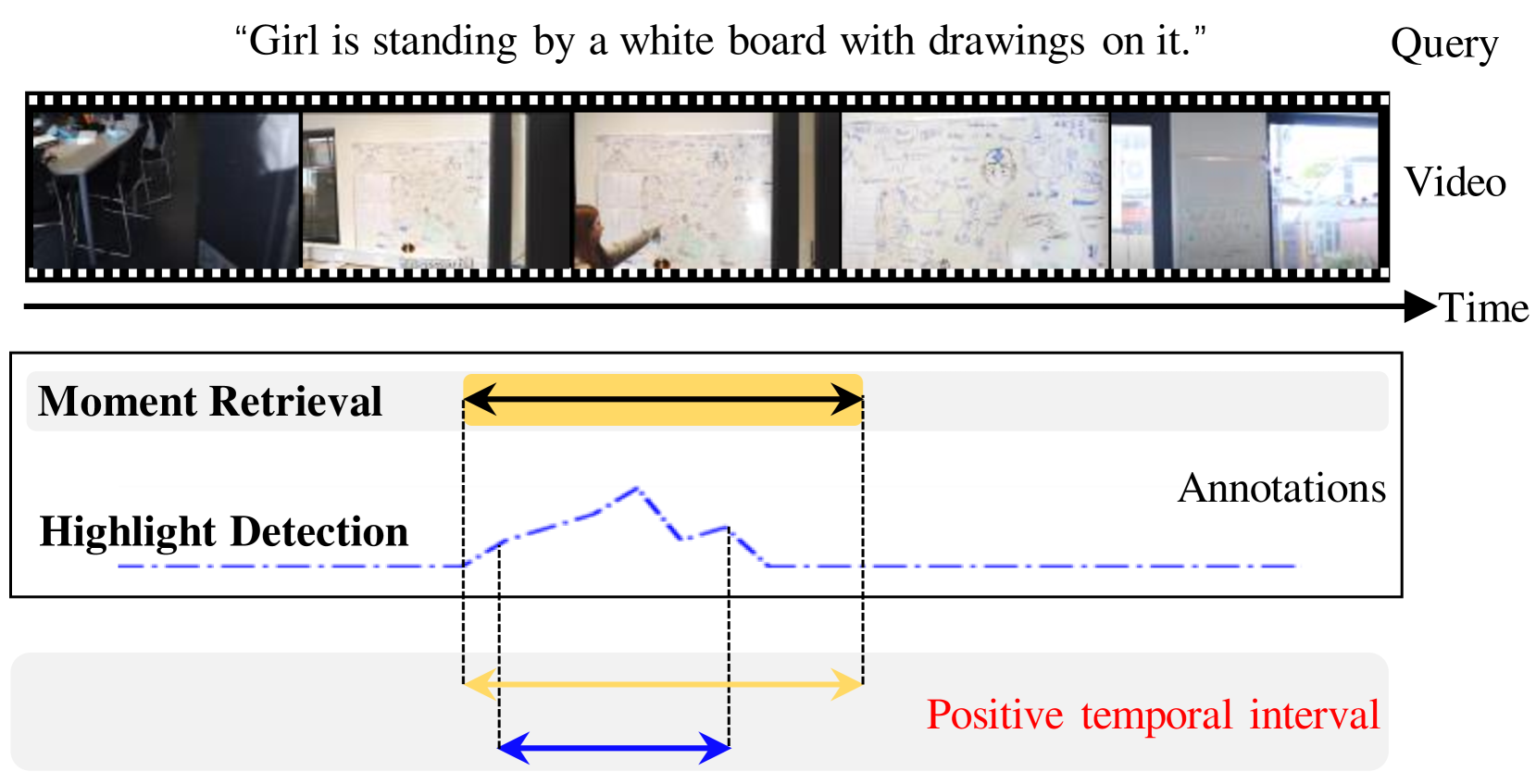
Jin Yang, Ping Wei, Huan Li, Ziyang Ren
Video moment retrieval and highlight detection are two highly valuable tasks in video understanding, but until recently they have been jointly studied. Although existing studies have made impressive advancement recently, they predominantly follow the data-driven bottom-up paradigm. Such paradigm overlooks task-specific and inter-task effects, resulting in poor model performance. In this paper, we propose a novel task-driven top-down framework TaskWeave for joint moment retrieval and highlight detection. The framework introduces a task-decoupled unit to capture task-specific and common representations. To investigate the interplay between the two tasks, we propose an inter-task feedback mechanism, which transforms the results of one task as guiding masks to assist the other task. Different from existing methods, we present a task-dependent joint loss function to optimize the model. Comprehensive experiments and in-depth ablation studies on QVHighlights, TVSum, and Charades-STA datasets corroborate the effectiveness and flexibility of the proposed framework. Codes are available at https://github.com/EdenGabriel/TaskWeave.
Read more4/16/2024

0
Do You Remember? Dense Video Captioning with Cross-Modal Memory Retrieval
Minkuk Kim, Hyeon Bae Kim, Jinyoung Moon, Jinwoo Choi, Seong Tae Kim
There has been significant attention to the research on dense video captioning, which aims to automatically localize and caption all events within untrimmed video. Several studies introduce methods by designing dense video captioning as a multitasking problem of event localization and event captioning to consider inter-task relations. However, addressing both tasks using only visual input is challenging due to the lack of semantic content. In this study, we address this by proposing a novel framework inspired by the cognitive information processing of humans. Our model utilizes external memory to incorporate prior knowledge. The memory retrieval method is proposed with cross-modal video-to-text matching. To effectively incorporate retrieved text features, the versatile encoder and the decoder with visual and textual cross-attention modules are designed. Comparative experiments have been conducted to show the effectiveness of the proposed method on ActivityNet Captions and YouCook2 datasets. Experimental results show promising performance of our model without extensive pretraining from a large video dataset.
Read more4/12/2024