Task-Driven Exploration: Decoupling and Inter-Task Feedback for Joint Moment Retrieval and Highlight Detection

0
Sign in to get full access
Overview
- This paper proposes a novel approach for jointly addressing two related tasks: moment retrieval and highlight detection in videos.
- The key ideas are to decouple the two tasks and introduce inter-task feedback to improve performance on both.
- The approach leverages UNIMD, IVPT, and Decoupling to achieve these goals.
Plain English Explanation
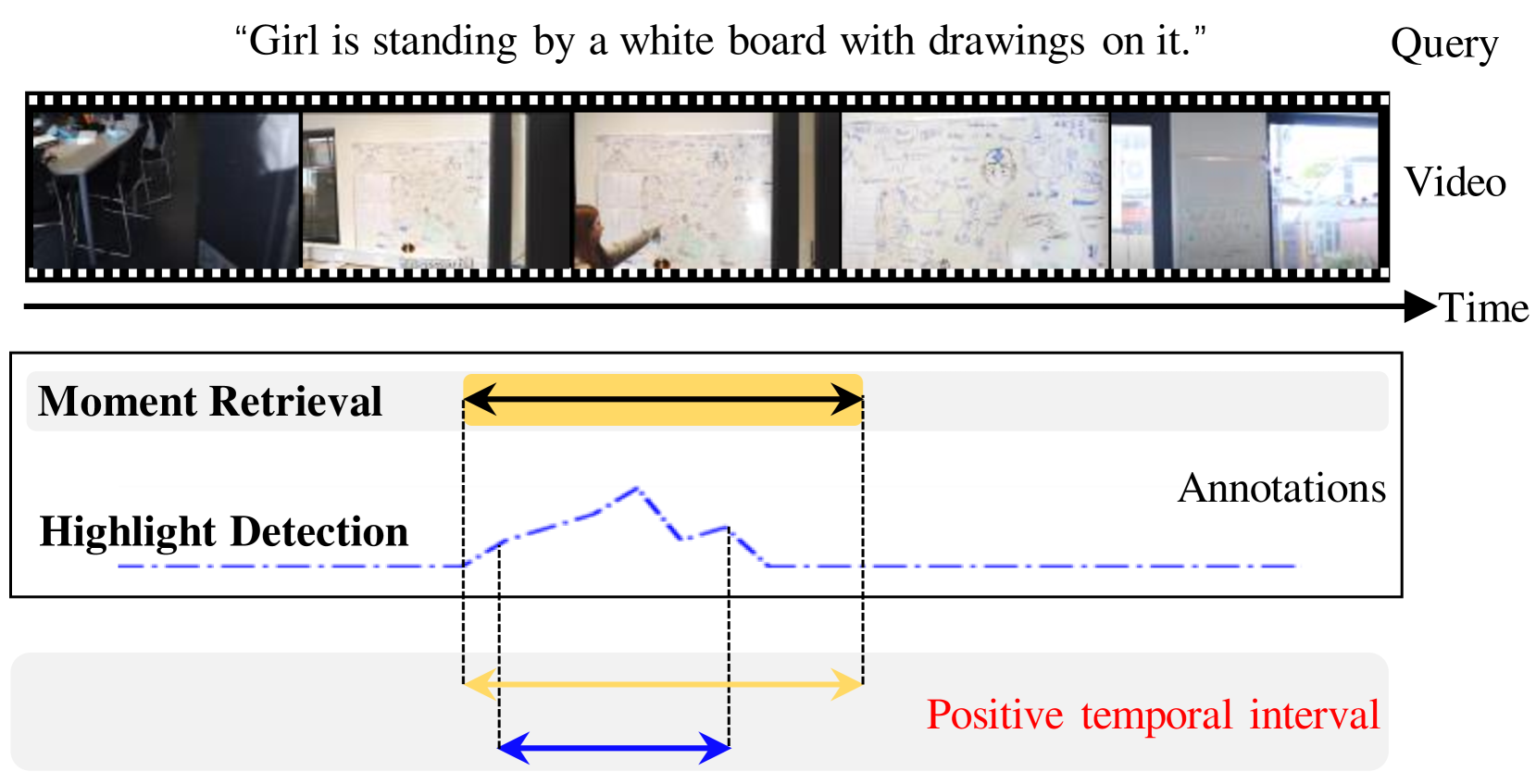
The paper focuses on two related tasks when working with videos: moment retrieval and highlight detection.
Moment retrieval is the process of finding specific moments or events within a video that are relevant to a given query. For example, if you asked "When did the main character win the race?", moment retrieval would try to identify the exact timestamp in the video where that happened.
Highlight detection, on the other hand, is about identifying the most interesting or important parts of a video, regardless of any specific query. Highlights could be dramatic moments, funny scenes, or other compelling content that viewers are likely to want to watch.
The key insight of this paper is that these two tasks are related - the moments that are retrieved are often the same as the highlights that are detected. The authors propose a new approach that decouples the two tasks, allowing them to be solved independently, but also introduces inter-task feedback to improve the performance of both.
This approach draws on ideas from several previous papers, including UNIMD, IVPT, and Decoupling. The key innovation is combining these techniques in a novel way to tackle the joint problem of moment retrieval and highlight detection.
Technical Explanation
The paper proposes a Task-Driven Exploration (TDE) framework that decouples moment retrieval and highlight detection into two separate tasks, but allows them to interact and provide feedback to each other.
The moment retrieval task is formulated as a joint multimodal transformer model that combines visual and text information to identify relevant moments in a video. The highlight detection task is framed as a partially-labeled multi-task learning problem, where the model learns to predict highlight scores for different video segments.
The inter-task feedback mechanism allows the two tasks to share information and insights, improving the performance of both. For example, the moment retrieval model can provide guidance to the highlight detection model about which segments are most likely to be relevant, and the highlight detection model can in turn provide feedback to refine the moment retrieval.
The authors evaluate their approach on several benchmark datasets for moment retrieval and highlight detection, demonstrating significant improvements over existing state-of-the-art methods. They also provide detailed ablation studies to analyze the contributions of the different components of their framework.
Critical Analysis
The paper presents a well-designed and carefully evaluated approach to the joint problem of moment retrieval and highlight detection. The authors make a compelling case for the benefits of decoupling the tasks while enabling inter-task feedback, drawing on relevant prior work to construct their framework.
One potential limitation is the reliance on the availability of partially-labeled data for the highlight detection task. In real-world scenarios, obtaining such labels may be challenging. The authors acknowledge this and suggest exploring unsupervised or weakly-supervised alternatives as an area for future research.
Additionally, the paper focuses on a specific video understanding context and does not explore the broader applicability of the TDE framework. It would be interesting to see how the approach could be extended to other related tasks, such as joint task regularization or joint multimodal transformer for emotion recognition.
Overall, the research presented in this paper represents a valuable contribution to the field of video understanding, with the potential for further refinement and expansion in future work.
Conclusion
This paper introduces a novel approach called Task-Driven Exploration that jointly addresses the problems of moment retrieval and highlight detection in videos. By decoupling the two tasks but allowing them to provide inter-task feedback, the authors demonstrate significant improvements over existing methods.
The key ideas draw on several related works, including UNIMD, IVPT, and Decoupling, showcasing the power of combining and building upon previous research.
This work has the potential to enhance various video-based applications, from video summarization and indexing to personalized content recommendation. As the authors suggest, exploring alternative approaches to the partially-labeled data requirement and expanding the framework to other related tasks could be fruitful areas for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Task-Driven Exploration: Decoupling and Inter-Task Feedback for Joint Moment Retrieval and Highlight Detection
Jin Yang, Ping Wei, Huan Li, Ziyang Ren
Video moment retrieval and highlight detection are two highly valuable tasks in video understanding, but until recently they have been jointly studied. Although existing studies have made impressive advancement recently, they predominantly follow the data-driven bottom-up paradigm. Such paradigm overlooks task-specific and inter-task effects, resulting in poor model performance. In this paper, we propose a novel task-driven top-down framework TaskWeave for joint moment retrieval and highlight detection. The framework introduces a task-decoupled unit to capture task-specific and common representations. To investigate the interplay between the two tasks, we propose an inter-task feedback mechanism, which transforms the results of one task as guiding masks to assist the other task. Different from existing methods, we present a task-dependent joint loss function to optimize the model. Comprehensive experiments and in-depth ablation studies on QVHighlights, TVSum, and Charades-STA datasets corroborate the effectiveness and flexibility of the proposed framework. Codes are available at https://github.com/EdenGabriel/TaskWeave.
Read more4/16/2024

0
RAG-based Crowdsourcing Task Decomposition via Masked Contrastive Learning with Prompts
Jing Yang, Xiao Wang, Yu Zhao, Yuhang Liu, Fei-Yue Wang
Crowdsourcing is a critical technology in social manufacturing, which leverages an extensive and boundless reservoir of human resources to handle a wide array of complex tasks. The successful execution of these complex tasks relies on task decomposition (TD) and allocation, with the former being a prerequisite for the latter. Recently, pre-trained language models (PLMs)-based methods have garnered significant attention. However, they are constrained to handling straightforward common-sense tasks due to their inherent restrictions involving limited and difficult-to-update knowledge as well as the presence of hallucinations. To address these issues, we propose a retrieval-augmented generation-based crowdsourcing framework that reimagines TD as event detection from the perspective of natural language understanding. However, the existing detection methods fail to distinguish differences between event types and always depend on heuristic rules and external semantic analyzing tools. Therefore, we present a Prompt-Based Contrastive learning framework for TD (PBCT), which incorporates a prompt-based trigger detector to overcome dependence. Additionally, trigger-attentive sentinel and masked contrastive learning are introduced to provide varying attention to trigger and contextual features according to different event types. Experiment results demonstrate the competitiveness of our method in both supervised and zero-shot detection. A case study on printed circuit board manufacturing is showcased to validate its adaptability to unknown professional domains.
Read more6/12/2024
⛏️
0
A Decoupling and Aggregating Framework for Joint Extraction of Entities and Relations
Yao Wang, Xin Liu, Weikun Kong, Hai-Tao Yu, Teeradaj Racharak, Kyoung-Sook Kim, Minh Le Nguyen
Named Entity Recognition and Relation Extraction are two crucial and challenging subtasks in the field of Information Extraction. Despite the successes achieved by the traditional approaches, fundamental research questions remain open. First, most recent studies use parameter sharing for a single subtask or shared features for both two subtasks, ignoring their semantic differences. Second, information interaction mainly focuses on the two subtasks, leaving the fine-grained informtion interaction among the subtask-specific features of encoding subjects, relations, and objects unexplored. Motivated by the aforementioned limitations, we propose a novel model to jointly extract entities and relations. The main novelties are as follows: (1) We propose to decouple the feature encoding process into three parts, namely encoding subjects, encoding objects, and encoding relations. Thanks to this, we are able to use fine-grained subtask-specific features. (2) We propose novel inter-aggregation and intra-aggregation strategies to enhance the information interaction and construct individual fine-grained subtask-specific features, respectively. The experimental results demonstrate that our model outperforms several previous state-of-the-art models. Extensive additional experiments further confirm the effectiveness of our model.
Read more5/15/2024
🔍
0
Task Presentation and Human Perception in Interactive Video Retrieval
Nina Willis, Abraham Bernstein, Luca Rossetto
Interactive video retrieval is a cooperative process between humans and retrieval systems. Large-scale evaluation campaigns, however, often overlook human factors, such as the effects of perception, attention, and memory, when assessing media retrieval systems. Consequently, their setups fall short of emulating realistic retrieval scenarios. In this paper, we design novel task presentation modes based on concepts in media memorability, implement the pipelines necessary for processing target video segments, and build a custom experimental platform for the final evaluation. In order to study the effects of different task representation schemes, we conduct a large crowdsourced experiment. Our findings demonstrate that the way in which the target of a video retrieval task is presented has a substantial influence on the difficulty of the retrieval task and that individuals can successfully retrieve a target video segment despite reducing or even altering the provided hints, opening up a discussion around future evaluation protocols in the domain of interactive media retrieval.
Read more5/8/2024