TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation

0
⚙️
Sign in to get full access
Overview
- This paper proposes a novel approach to imbue robots with the ability to efficiently manipulate unseen objects and transfer relevant skills based on demonstrations.
- The key idea is to focus on the task-specific pose relationship between relevant parts of interacting objects, known as "cross-pose," rather than relying on end-to-end learning methods that often fail to generalize to novel objects or unseen configurations.
- The authors present a vision-based system that learns to estimate the cross-pose between two objects for a given manipulation task using learned cross-object correspondences, which is then used to guide a downstream motion planner.
Plain English Explanation
The paper explores a way to teach robots how to manipulate objects they've never seen before, by focusing on the specific relationships between the parts of objects involved in a task. For example, the way a pan is positioned relative to an oven when placing it, or how a mug sits on a mug rack.
The researchers call this the "cross-pose" relationship, and they've developed a system that can learn these relationships from just a few real-world demonstrations. Their vision-based approach identifies corresponding points between objects, which allows it to estimate the crucial cross-pose information. This is then used to guide the robot's movements and help it manipulate new objects in the same way.
The key advantage of this approach is that it can generalize to novel objects, rather than relying on end-to-end learning which often struggles with unseen configurations. The authors show their system works well in both simulated and real-world experiments across various tasks, outperforming the state-of-the-art.
Technical Explanation
The paper proposes a novel vision-based system that learns to estimate the "cross-pose" relationship between two objects involved in a manipulation task. This cross-pose is a task-specific pose relationship, such as the position of a pan relative to an oven, that the authors conjecture is a generalizable notion of the manipulation task.
The system learns cross-object correspondences, which allow it to estimate the cross-pose, even for new objects in the same category. This cross-pose information is then used to guide a downstream motion planner to manipulate the objects into the desired pose relationship.
The authors demonstrate their method's capability to generalize to unseen objects, in some cases after training on just 10 real-world demonstrations. The results show the system achieves state-of-the-art performance in both simulated and real-world experiments across a variety of tasks.
Critical Analysis
The paper presents a compelling approach to addressing the generalization challenge in robotic manipulation, which is a key limitation of many end-to-end learning methods. By focusing on the task-specific cross-pose relationship, the authors introduce a novel and potentially more transferable representation of manipulation skills.
However, the paper does not delve deeply into the potential limitations or failure modes of the cross-pose-based approach. For example, it's unclear how well the system would scale to more complex, multi-step tasks or handle significant variations in object geometry within the same category.
Additionally, the paper could have provided more insight into the trade-offs between the cross-pose estimation and the downstream motion planning components of the system. It would be interesting to understand how errors or uncertainties in the cross-pose estimation might impact the overall manipulation performance.
Overall, the research represents an important step forward in robotic manipulation, and the proposed cross-pose concept is a promising direction for further exploration and refinement. Readers are encouraged to think critically about the broader implications and potential issues that were not fully addressed in the paper.
Conclusion
This paper presents a novel approach to imbue robots with the ability to efficiently manipulate unseen objects by focusing on the task-specific pose relationship, or "cross-pose," between relevant parts of interacting objects. The authors demonstrate a vision-based system that can learn these cross-pose relationships from just a few real-world demonstrations and use them to guide a motion planner to manipulate new objects in the same category.
The key innovation of this work is its potential to generalize to novel objects, overcoming a common limitation of end-to-end learning methods. The results show the system achieves state-of-the-art performance in both simulated and real-world experiments, suggesting this cross-pose-based approach could be a valuable tool for advancing robotic manipulation capabilities and enabling more versatile and adaptable robot systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation
Chuer Pan, Brian Okorn, Harry Zhang, Ben Eisner, David Held
How do we imbue robots with the ability to efficiently manipulate unseen objects and transfer relevant skills based on demonstrations? End-to-end learning methods often fail to generalize to novel objects or unseen configurations. Instead, we focus on the task-specific pose relationship between relevant parts of interacting objects. We conjecture that this relationship is a generalizable notion of a manipulation task that can transfer to new objects in the same category; examples include the relationship between the pose of a pan relative to an oven or the pose of a mug relative to a mug rack. We call this task-specific pose relationship cross-pose and provide a mathematical definition of this concept. We propose a vision-based system that learns to estimate the cross-pose between two objects for a given manipulation task using learned cross-object correspondences. The estimated cross-pose is then used to guide a downstream motion planner to manipulate the objects into the desired pose relationship (placing a pan into the oven or the mug onto the mug rack). We demonstrate our method's capability to generalize to unseen objects, in some cases after training on only 10 demonstrations in the real world. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments across a number of tasks. Supplementary information and videos can be found at https://sites.google.com/view/tax-pose/home.
Read more5/3/2024

0
Learning Distributional Demonstration Spaces for Task-Specific Cross-Pose Estimation
Jenny Wang, Octavian Donca, David Held
Relative placement tasks are an important category of tasks in which one object needs to be placed in a desired pose relative to another object. Previous work has shown success in learning relative placement tasks from just a small number of demonstrations when using relational reasoning networks with geometric inductive biases. However, such methods cannot flexibly represent multimodal tasks, like a mug hanging on any of n racks. We propose a method that incorporates additional properties that enable learning multimodal relative placement solutions, while retaining the provably translation-invariant and relational properties of prior work. We show that our method is able to learn precise relative placement tasks with only 10-20 multimodal demonstrations with no human annotations across a diverse set of objects within a category.
Read more5/9/2024
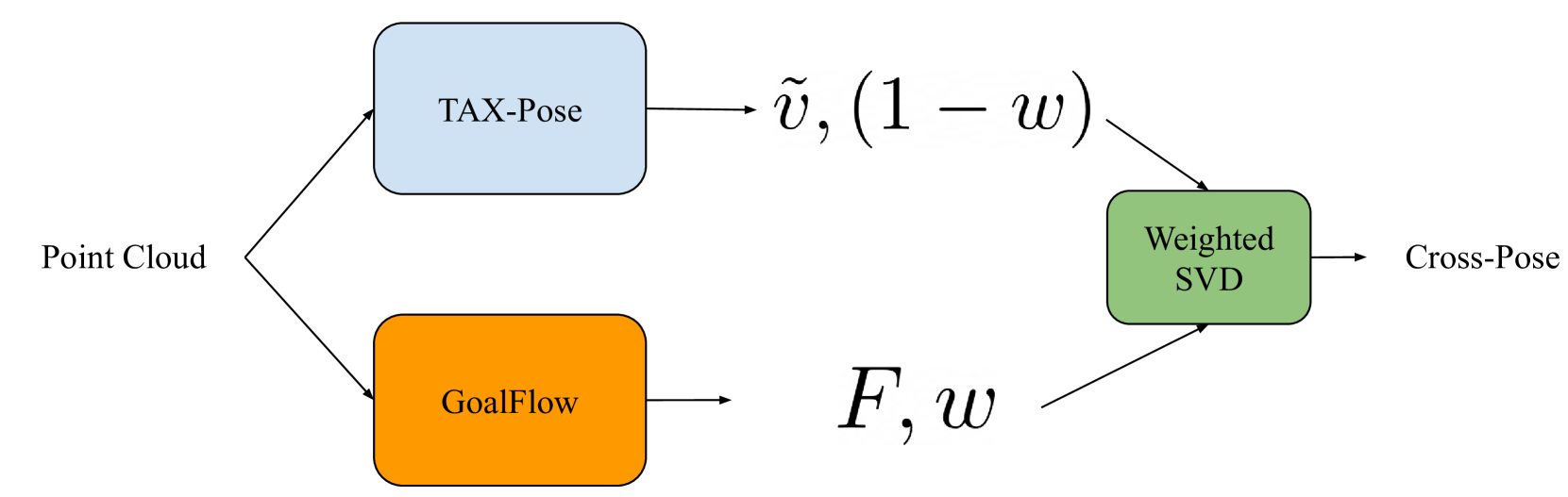
0
WeightedPose: Generalizable Cross-Pose Estimation via Weighted SVD
Xuxin Cheng, Heng Yu, Harry Zhang, Wenxing Deng
We introduce a new approach for robotic manipulation tasks in human settings that necessitates understanding the 3D geometric connections between a pair of objects. Conventional end-to-end training approaches, which convert pixel observations directly into robot actions, often fail to effectively understand complex pose rela- tionships and do not easily adapt to new object configurations. To overcome these issues, our method focuses on learning the 3D geometric relationships, particularly how critical parts of one object relate to those of another. We employ Weighted SVD in our standalone model to analyze pose relationships both in articulated parts and in free-floating objects. For instance, our model can comprehend the spatial relationship between an oven door and the oven body, as well as between a lasagna plate and the oven. By concentrating on the 3D geometric connections, our strategy empowers robots to carry out intricate manipulation tasks based on object-centric perspectives
Read more5/22/2024

0
CtRNet-X: Camera-to-Robot Pose Estimation in Real-world Conditions Using a Single Camera
Jingpei Lu, Zekai Liang, Tristin Xie, Florian Ritcher, Shan Lin, Sainan Liu, Michael C. Yip
Camera-to-robot calibration is crucial for vision-based robot control and requires effort to make it accurate. Recent advancements in markerless pose estimation methods have eliminated the need for time-consuming physical setups for camera-to-robot calibration. While the existing markerless pose estimation methods have demonstrated impressive accuracy without the need for cumbersome setups, they rely on the assumption that all the robot joints are visible within the camera's field of view. However, in practice, robots usually move in and out of view, and some portion of the robot may stay out-of-frame during the whole manipulation task due to real-world constraints, leading to a lack of sufficient visual features and subsequent failure of these approaches. To address this challenge and enhance the applicability to vision-based robot control, we propose a novel framework capable of estimating the robot pose with partially visible robot manipulators. Our approach leverages the Vision-Language Models for fine-grained robot components detection, and integrates it into a keypoint-based pose estimation network, which enables more robust performance in varied operational conditions. The framework is evaluated on both public robot datasets and self-collected partial-view datasets to demonstrate our robustness and generalizability. As a result, this method is effective for robot pose estimation in a wider range of real-world manipulation scenarios.
Read more9/17/2024