Learning Distributional Demonstration Spaces for Task-Specific Cross-Pose Estimation

0

Sign in to get full access
Overview
- This paper introduces a novel approach for task-specific cross-pose estimation, which involves learning distributional demonstration spaces to enable robots to learn manipulation tasks from human demonstrations across varying body poses.
- The key idea is to learn a latent space that captures the task-relevant features of the demonstrations, while being invariant to the specific poses of the demonstrator.
- This allows the robot to generalize the learned task to new poses and situations, improving its ability to perform the task accurately.
Plain English Explanation
The paper discusses a new way for robots to learn how to do specific tasks by watching people demonstrate those tasks. Often, when people show a robot how to do something, they might be in different positions or poses. This can make it hard for the robot to understand the task and apply it in new situations.
The researchers developed a system that can learn the important aspects of a task from the demonstrations, while ignoring the specific body positions of the person doing the demo. This allows the robot to learn the task in a more general way, so it can perform the task accurately even when the person is in a different pose.
The key is that the system learns a "latent space" - a mathematical representation of the task that captures the essential features, but is independent of the person's pose. This latent space helps the robot learn to localize objects and reason about spatial relationships, which are important for many manipulation tasks.
By learning this distributional demonstration space, the robot can generalize the task to new situations and body positions, making it more flexible and capable of precise placement and task-specific cross-pose estimation.
Technical Explanation
The paper proposes a novel approach for learning distributional demonstration spaces to enable task-specific cross-pose estimation. The key idea is to learn a latent representation of the task that is invariant to the specific body poses of the demonstrator.
The authors develop a neural network architecture that takes as input the demonstrator's pose and the task-relevant scene information, and outputs a latent code representing the task. This latent code captures the essential features of the task, while being invariant to the demonstrator's pose.
The network is trained using a contrastive loss function, which encourages the latent codes from similar demonstrations to be close together, and the latent codes from different demonstrations to be far apart. This allows the network to learn a distributional demonstration space that generalizes across different poses.
The authors evaluate their approach on several manipulation tasks, including block stacking and tool use. They show that their method outperforms baseline approaches that do not explicitly model the pose invariance, demonstrating the importance of learning a task-specific latent space for cross-pose estimation.
Critical Analysis
The paper presents a compelling approach for enabling robots to learn manipulation tasks from human demonstrations, even when the demonstrator's body poses vary. The authors' focus on learning a pose-invariant latent representation of the task is a promising direction, as it allows the robot to generalize the learned skills to new situations.
However, the paper does not address some potential limitations of the approach. For example, the experiments are limited to relatively simple manipulation tasks in controlled environments. It's unclear how well the method would scale to more complex, real-world tasks with greater variability in the demonstrations and the environment.
Additionally, the paper does not explore the robustness of the learned latent space to factors like occlusions, sensor noise, or changes in the scene. These are important considerations for deploying such systems in practical applications.
Further research could also investigate the interpretability of the learned latent space, and whether it aligns with human intuitions about the task-relevant features. This could help improve the transparency and trustworthiness of the system.
Conclusion
The proposed approach for learning distributional demonstration spaces represents an important step forward in enabling robots to learn manipulation skills from human demonstrations. By learning a pose-invariant latent representation of the task, the system can generalize the learned skills to new situations, improving the robot's flexibility and accuracy.
While the paper demonstrates promising results on some benchmark tasks, further research is needed to address the scalability and robustness of the approach in more complex, real-world settings. Nonetheless, this work contributes to the broader goal of developing more capable and adaptable robotic systems that can learn from human guidance and interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Distributional Demonstration Spaces for Task-Specific Cross-Pose Estimation
Jenny Wang, Octavian Donca, David Held
Relative placement tasks are an important category of tasks in which one object needs to be placed in a desired pose relative to another object. Previous work has shown success in learning relative placement tasks from just a small number of demonstrations when using relational reasoning networks with geometric inductive biases. However, such methods cannot flexibly represent multimodal tasks, like a mug hanging on any of n racks. We propose a method that incorporates additional properties that enable learning multimodal relative placement solutions, while retaining the provably translation-invariant and relational properties of prior work. We show that our method is able to learn precise relative placement tasks with only 10-20 multimodal demonstrations with no human annotations across a diverse set of objects within a category.
Read more5/9/2024

0
Deep SE(3)-Equivariant Geometric Reasoning for Precise Placement Tasks
Ben Eisner, Yi Yang, Todor Davchev, Mel Vecerik, Jonathan Scholz, David Held
Many robot manipulation tasks can be framed as geometric reasoning tasks, where an agent must be able to precisely manipulate an object into a position that satisfies the task from a set of initial conditions. Often, task success is defined based on the relationship between two objects - for instance, hanging a mug on a rack. In such cases, the solution should be equivariant to the initial position of the objects as well as the agent, and invariant to the pose of the camera. This poses a challenge for learning systems which attempt to solve this task by learning directly from high-dimensional demonstrations: the agent must learn to be both equivariant as well as precise, which can be challenging without any inductive biases about the problem. In this work, we propose a method for precise relative pose prediction which is provably SE(3)-equivariant, can be learned from only a few demonstrations, and can generalize across variations in a class of objects. We accomplish this by factoring the problem into learning an SE(3) invariant task-specific representation of the scene and then interpreting this representation with novel geometric reasoning layers which are provably SE(3) equivariant. We demonstrate that our method can yield substantially more precise placement predictions in simulated placement tasks than previous methods trained with the same amount of data, and can accurately represent relative placement relationships data collected from real-world demonstrations. Supplementary information and videos can be found at https://sites.google.com/view/reldist-iclr-2023.
Read more4/23/2024
⚙️
0
TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation
Chuer Pan, Brian Okorn, Harry Zhang, Ben Eisner, David Held
How do we imbue robots with the ability to efficiently manipulate unseen objects and transfer relevant skills based on demonstrations? End-to-end learning methods often fail to generalize to novel objects or unseen configurations. Instead, we focus on the task-specific pose relationship between relevant parts of interacting objects. We conjecture that this relationship is a generalizable notion of a manipulation task that can transfer to new objects in the same category; examples include the relationship between the pose of a pan relative to an oven or the pose of a mug relative to a mug rack. We call this task-specific pose relationship cross-pose and provide a mathematical definition of this concept. We propose a vision-based system that learns to estimate the cross-pose between two objects for a given manipulation task using learned cross-object correspondences. The estimated cross-pose is then used to guide a downstream motion planner to manipulate the objects into the desired pose relationship (placing a pan into the oven or the mug onto the mug rack). We demonstrate our method's capability to generalize to unseen objects, in some cases after training on only 10 demonstrations in the real world. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments across a number of tasks. Supplementary information and videos can be found at https://sites.google.com/view/tax-pose/home.
Read more5/3/2024
0
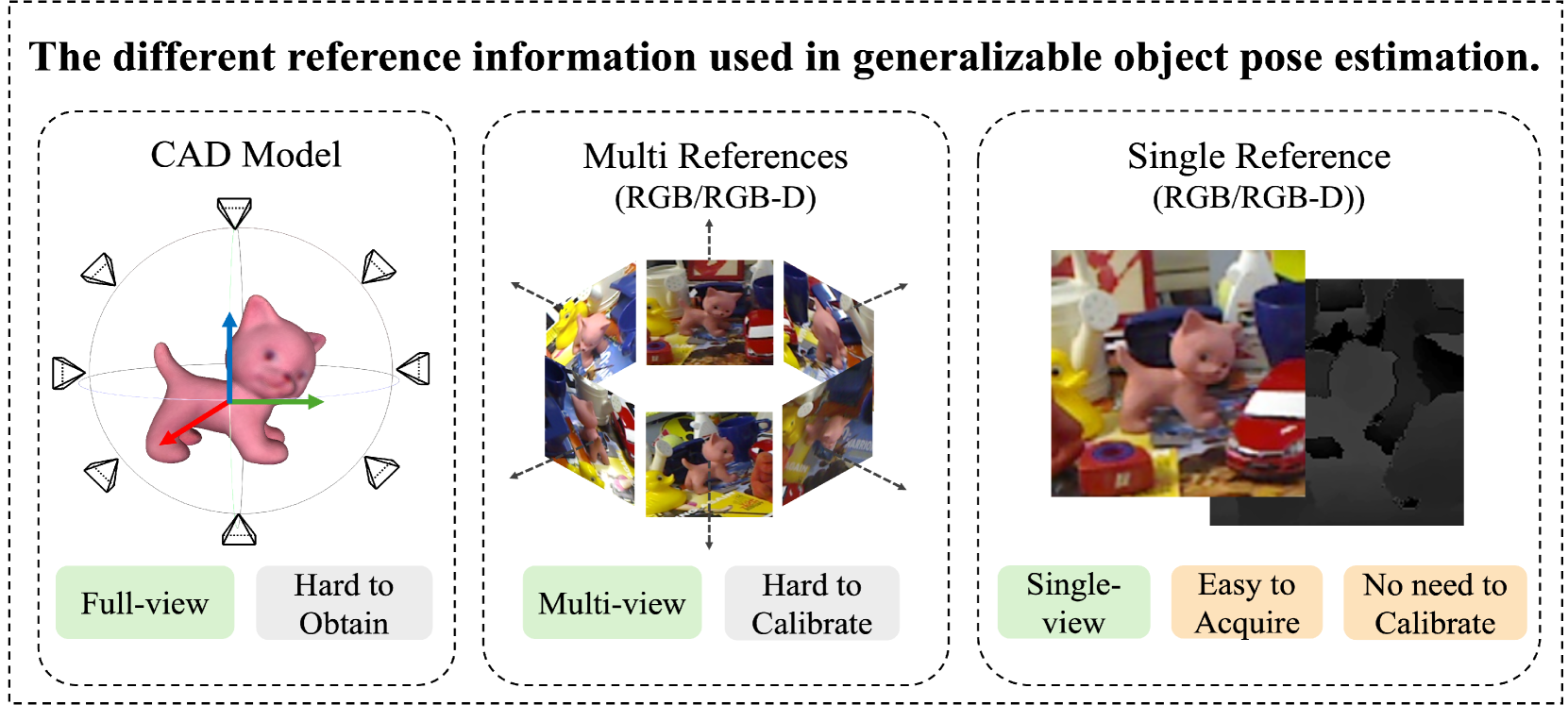
Towards Human-Level 3D Relative Pose Estimation: Generalizable, Training-Free, with Single Reference
Yuan Gao, Yajing Luo, Junhong Wang, Kui Jia, Gui-Song Xia
Humans can easily deduce the relative pose of an unseen object, without label/training, given only a single query-reference image pair. This is arguably achieved by incorporating (i) 3D/2.5D shape perception from a single image, (ii) render-and-compare simulation, and (iii) rich semantic cue awareness to furnish (coarse) reference-query correspondence. Existing methods implement (i) by a 3D CAD model or well-calibrated multiple images and (ii) by training a network on specific objects, which necessitate laborious ground-truth labeling and tedious training, potentially leading to challenges in generalization. Moreover, (iii) was less exploited in the paradigm of (ii), despite that the coarse correspondence from (iii) enhances the compare process by filtering out non-overlapped parts under substantial pose differences/occlusions. Motivated by this, we propose a novel 3D generalizable relative pose estimation method by elaborating (i) with a 2.5D shape from an RGB-D reference, (ii) with an off-the-shelf differentiable renderer, and (iii) with semantic cues from a pretrained model like DINOv2. Specifically, our differentiable renderer takes the 2.5D rotatable mesh textured by the RGB and the semantic maps (obtained by DINOv2 from the RGB input), then renders new RGB and semantic maps (with back-surface culling) under a novel rotated view. The refinement loss comes from comparing the rendered RGB and semantic maps with the query ones, back-propagating the gradients through the differentiable renderer to refine the 3D relative pose. As a result, our method can be readily applied to unseen objects, given only a single RGB-D reference, without label/training. Extensive experiments on LineMOD, LM-O, and YCB-V show that our training-free method significantly outperforms the SOTA supervised methods, especially under the rigorous Acc@5/10/15{deg} metrics and the challenging cross-dataset settings.
Read more6/27/2024