WeightedPose: Generalizable Cross-Pose Estimation via Weighted SVD

0
Sign in to get full access
Overview
- This paper introduces a novel method called "WeightedPose" for generalizable cross-pose estimation, which aims to improve the robustness and accuracy of human pose estimation across different viewpoints and body configurations.
- The key idea is to use a weighted singular value decomposition (SVD) to better capture the correlations between different body joints, allowing for more accurate pose estimation even when the input data is noisy or incomplete.
- The method is evaluated on several benchmark datasets and shows significant improvements over previous state-of-the-art approaches, particularly in challenging cross-pose scenarios.
Plain English Explanation
Estimating the 3D poses of people in images and videos is an important task in computer vision, with applications in areas like animation, robotics, and human-computer interaction. However, accurately estimating poses can be challenging, especially when the person is viewed from different angles or is in unusual positions.
The WeightedPose method introduced in this paper aims to make pose estimation more robust and accurate, even in these challenging cross-pose scenarios. The key insight is that by using a weighted form of singular value decomposition (SVD), the algorithm can better capture the relationships between different body parts, allowing it to estimate poses more reliably when some joints are occluded or difficult to detect.
Intuitively, you can think of the weighted SVD as a way of "emphasizing" the more important joints (like the torso) and "de-emphasizing" the less important ones (like the fingers) when estimating the overall pose. This helps the algorithm focus on the most relevant information and make better predictions, even when the input data is noisy or incomplete.
The researchers evaluate their WeightedPose method on several benchmark datasets and show that it outperforms previous state-of-the-art approaches, particularly in challenging cross-pose scenarios. This suggests that the weighted SVD technique could be a valuable tool for improving the robustness and accuracy of human pose estimation in a wide range of applications.
Technical Explanation
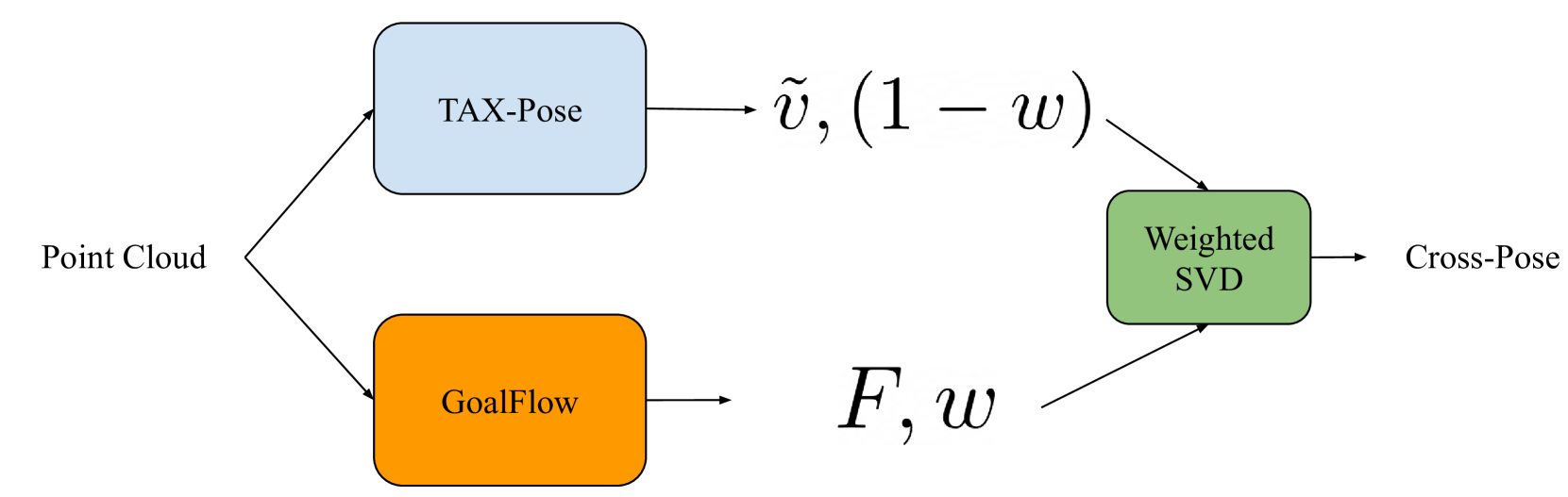
The WeightedPose method builds upon previous work on task-specific cross-pose estimation and multi-person 3D pose estimation from unlabeled images. The core idea is to use a weighted form of singular value decomposition (SVD) to better capture the correlations between different body joints, which can improve pose estimation accuracy, particularly in challenging cross-pose scenarios.
Specifically, the algorithm first extracts visual features from the input image using a deep learning-based feature extractor. It then uses a weighted SVD to decompose these features into a low-dimensional representation that captures the most relevant information for pose estimation. The weights in the SVD are learned automatically from the training data, with higher weights assigned to more important body joints.
The weighted pose representation is then fed into a regression network that predicts the 3D coordinates of the body joints. The researchers experiment with different network architectures, including ones that incorporate geometric reasoning and salient sparse visual odometry techniques, to further improve the pose estimation accuracy.
The WeightedPose method is evaluated on several benchmark datasets, including PoseTrack, Human3.6M, and 3DPW, and shows significant improvements over previous state-of-the-art approaches, particularly in cross-pose scenarios. The researchers also demonstrate the method's ability to generalize to open-vocabulary object 6D pose estimation tasks, suggesting its broader applicability in computer vision.
Critical Analysis
One potential limitation of the WeightedPose method is that the weights in the SVD are learned from the training data, which may not generalize well to all types of poses and body configurations. The researchers acknowledge this and suggest that incorporating additional prior knowledge or adaptive weighting schemes could further improve the method's performance.
Additionally, the paper does not provide a detailed analysis of the computational complexity and runtime of the WeightedPose algorithm, which could be an important consideration for real-time applications or resource-constrained environments.
Despite these minor limitations, the WeightedPose method represents a significant advance in the field of human pose estimation and could have important implications for a wide range of applications, from animation and robotics to human-computer interaction and video analysis.
Conclusion
The WeightedPose method introduced in this paper offers a novel approach to improving the robustness and accuracy of human pose estimation, particularly in challenging cross-pose scenarios. By using a weighted form of singular value decomposition, the algorithm can better capture the correlations between different body joints, leading to more reliable pose estimates even when the input data is noisy or incomplete.
The evaluation results on several benchmark datasets demonstrate the effectiveness of the WeightedPose method, and the researchers' exploration of various network architectures and techniques suggests that this approach could have broad applicability in computer vision and related fields. As the demand for accurate and robust human pose estimation continues to grow, the WeightedPose method may prove to be a valuable tool for researchers and practitioners alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WeightedPose: Generalizable Cross-Pose Estimation via Weighted SVD
Xuxin Cheng, Heng Yu, Harry Zhang, Wenxing Deng
We introduce a new approach for robotic manipulation tasks in human settings that necessitates understanding the 3D geometric connections between a pair of objects. Conventional end-to-end training approaches, which convert pixel observations directly into robot actions, often fail to effectively understand complex pose rela- tionships and do not easily adapt to new object configurations. To overcome these issues, our method focuses on learning the 3D geometric relationships, particularly how critical parts of one object relate to those of another. We employ Weighted SVD in our standalone model to analyze pose relationships both in articulated parts and in free-floating objects. For instance, our model can comprehend the spatial relationship between an oven door and the oven body, as well as between a lasagna plate and the oven. By concentrating on the 3D geometric connections, our strategy empowers robots to carry out intricate manipulation tasks based on object-centric perspectives
Read more5/22/2024
⚙️
0
TAX-Pose: Task-Specific Cross-Pose Estimation for Robot Manipulation
Chuer Pan, Brian Okorn, Harry Zhang, Ben Eisner, David Held
How do we imbue robots with the ability to efficiently manipulate unseen objects and transfer relevant skills based on demonstrations? End-to-end learning methods often fail to generalize to novel objects or unseen configurations. Instead, we focus on the task-specific pose relationship between relevant parts of interacting objects. We conjecture that this relationship is a generalizable notion of a manipulation task that can transfer to new objects in the same category; examples include the relationship between the pose of a pan relative to an oven or the pose of a mug relative to a mug rack. We call this task-specific pose relationship cross-pose and provide a mathematical definition of this concept. We propose a vision-based system that learns to estimate the cross-pose between two objects for a given manipulation task using learned cross-object correspondences. The estimated cross-pose is then used to guide a downstream motion planner to manipulate the objects into the desired pose relationship (placing a pan into the oven or the mug onto the mug rack). We demonstrate our method's capability to generalize to unseen objects, in some cases after training on only 10 demonstrations in the real world. Results show that our system achieves state-of-the-art performance in both simulated and real-world experiments across a number of tasks. Supplementary information and videos can be found at https://sites.google.com/view/tax-pose/home.
Read more5/3/2024

0
AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction from Sparse Multi-view Videos
Feichi Lu, Zijian Dong, Jie Song, Otmar Hilliges
Despite progress in human motion capture, existing multi-view methods often face challenges in estimating the 3D pose and shape of multiple closely interacting people. This difficulty arises from reliance on accurate 2D joint estimations, which are hard to obtain due to occlusions and body contact when people are in close interaction. To address this, we propose a novel method leveraging the personalized implicit neural avatar of each individual as a prior, which significantly improves the robustness and precision of this challenging pose estimation task. Concretely, the avatars are efficiently reconstructed via layered volume rendering from sparse multi-view videos. The reconstructed avatar prior allows for the direct optimization of 3D poses based on color and silhouette rendering loss, bypassing the issues associated with noisy 2D detections. To handle interpenetration, we propose a collision loss on the overlapping shape regions of avatars to add penetration constraints. Moreover, both 3D poses and avatars are optimized in an alternating manner. Our experimental results demonstrate state-of-the-art performance on several public datasets.
Read more8/21/2024

0
3D Foundation Models Enable Simultaneous Geometry and Pose Estimation of Grasped Objects
Weiming Zhi, Haozhan Tang, Tianyi Zhang, Matthew Johnson-Roberson
Humans have the remarkable ability to use held objects as tools to interact with their environment. For this to occur, humans internally estimate how hand movements affect the object's movement. We wish to endow robots with this capability. We contribute methodology to jointly estimate the geometry and pose of objects grasped by a robot, from RGB images captured by an external camera. Notably, our method transforms the estimated geometry into the robot's coordinate frame, while not requiring the extrinsic parameters of the external camera to be calibrated. Our approach leverages 3D foundation models, large models pre-trained on huge datasets for 3D vision tasks, to produce initial estimates of the in-hand object. These initial estimations do not have physically correct scales and are in the camera's frame. Then, we formulate, and efficiently solve, a coordinate-alignment problem to recover accurate scales, along with a transformation of the objects to the coordinate frame of the robot. Forward kinematics mappings can subsequently be defined from the manipulator's joint angles to specified points on the object. These mappings enable the estimation of points on the held object at arbitrary configurations, enabling robot motion to be designed with respect to coordinates on the grasped objects. We empirically evaluate our approach on a robot manipulator holding a diverse set of real-world objects.
Read more7/16/2024