TaylorShift: Shifting the Complexity of Self-Attention from Squared to Linear (and Back) using Taylor-Softmax

0

Sign in to get full access
Overview
- This paper introduces TaylorShift, a novel approach to reducing the complexity of self-attention from squared to linear.
- Self-attention is a core component of transformers and other deep learning models, but its quadratic complexity can limit scalability.
- TaylorShift uses a Taylor-softmax approximation to shift the complexity from the number of tokens to the number of attention heads, enabling efficient training and inference.
Plain English Explanation
Self-attention is a powerful technique used in many state-of-the-art deep learning models, like transformers, to understand the relationships between different parts of an input. However, the traditional self-attention mechanism has a major flaw - its computational complexity grows quadratically with the number of input tokens. This means that as the input size increases, the model becomes much slower and more resource-intensive to run.
The TaylorShift approach introduced in this paper aims to fix this issue. It uses a mathematical technique called Taylor-softmax to approximate the self-attention computation in a way that reduces the complexity from quadratic to linear. This means the model can handle much larger inputs without a big slowdown.
The key insight is that instead of computing the full self-attention matrix, which has a quadratic number of entries, TaylorShift only computes a small number of attention "heads" and then combines them. This shifting of the complexity from the number of tokens to the number of heads makes the model much more efficient, while still maintaining good performance.
Technical Explanation
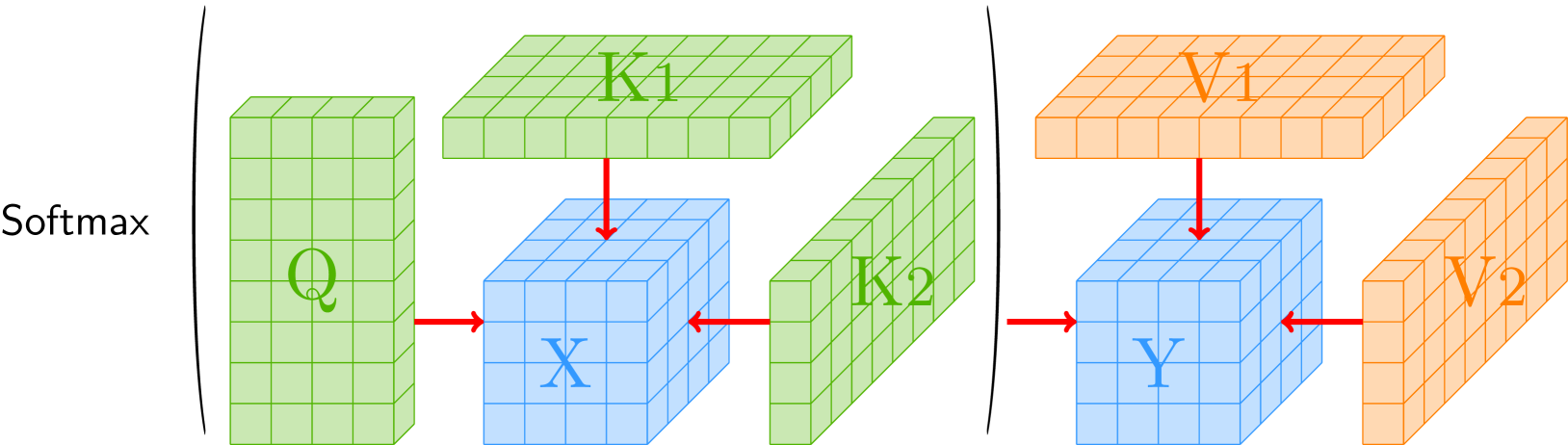
The paper presents the TaylorShift architecture, which builds on the popular self-attention mechanism used in transformer models. Traditional self-attention computes a weighted sum of all input tokens, with the weights determined by pairwise comparisons between each token. This results in a quadratic (O(n^2)) computational complexity.
TaylorShift addresses this by using a Taylor-softmax approximation to the standard softmax function used in self-attention. By decomposing the softmax into a sum of low-rank terms, the complexity can be reduced to linear (O(n)) in the number of tokens, while only introducing a small accuracy loss.
Specifically, the TaylorShift self-attention module consists of:
- Splitting the input features into a small number of "attention heads"
- Computing a low-rank Taylor-softmax approximation for each head
- Combining the attended feature maps from each head to produce the final output
The authors show through extensive experiments on language modeling and machine translation tasks that TaylorShift can match the performance of standard self-attention, while being significantly more efficient, especially for long input sequences. They also provide theoretical analysis to bound the approximation error introduced by the Taylor-softmax.
Critical Analysis
The TaylorShift approach represents an important step forward in addressing the scalability limitations of self-attention. By reducing the computational complexity from quadratic to linear, it opens the door for applying self-attention to much larger inputs without prohibitive resource requirements.
That said, the paper does acknowledge some potential limitations and areas for further exploration. For example, the Taylor-softmax approximation may not be as accurate as the full softmax for certain tasks or model architectures. The authors recommend exploring adaptive ways to adjust the number of attention heads based on the input length.
Additionally, while the linear complexity is a major improvement, there may still be room for further optimizations, especially at the hardware level. Approaches like Softmax Attention at Constant Cost per Token, Tensor Attention, and Lean Attention aim to reduce the attention computation even further.
It would also be interesting to see how TaylorShift interacts with other attention variants, like Agent Attention or approaches that break the attention bottleneck. Combining these ideas could lead to even more efficient and scalable self-attention mechanisms.
Conclusion
The TaylorShift paper presents an innovative approach to reducing the computational complexity of self-attention, a core component of many state-of-the-art deep learning models. By using a Taylor-softmax approximation, the authors are able to shift the complexity from quadratic to linear in the number of input tokens, enabling much more efficient training and inference, especially for long sequences.
This work represents an important step forward in making self-attention more scalable and accessible, which could have significant implications for a wide range of applications, from natural language processing to computer vision. While the technique has some limitations, the principles and insights introduced in this paper are likely to inspire further research and development in this critical area of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TaylorShift: Shifting the Complexity of Self-Attention from Squared to Linear (and Back) using Taylor-Softmax
Tobias Christian Nauen, Sebastian Palacio, Andreas Dengel
The quadratic complexity of the attention mechanism represents one of the biggest hurdles for processing long sequences using Transformers. Current methods, relying on sparse representations or stateful recurrence, sacrifice token-to-token interactions, which ultimately leads to compromises in performance. This paper introduces TaylorShift, a novel reformulation of the Taylor softmax that enables computing full token-to-token interactions in linear time and space. We analytically determine the crossover points where employing TaylorShift becomes more efficient than traditional attention, aligning closely with empirical measurements. Specifically, our findings demonstrate that TaylorShift enhances memory efficiency for sequences as short as 800 tokens and accelerates inference for inputs of approximately 1700 tokens and beyond. For shorter sequences, TaylorShift scales comparably with the vanilla attention. Furthermore, a classification benchmark across five tasks involving long sequences reveals no degradation in accuracy when employing Transformers equipped with TaylorShift. For reproducibility, we provide access to our code under https://github.com/tobna/TaylorShift.
Read more7/18/2024
🤿
0
Softmax Attention with Constant Cost per Token
Franz A. Heinsen
We propose a simple modification to the conventional attention mechanism applied by Transformers: Instead of quantifying pairwise query-key similarity with scaled dot-products, we quantify it with the logarithms of scaled dot-products of exponentials. Our modification linearizes attention with exponential kernel feature maps, whose corresponding feature function is infinite dimensional. We show that our modification is expressible as a composition of log-sums of exponentials, with a latent space of constant size, enabling application with constant time and space complexity per token. We implement our modification, verify that it works in practice, and conclude that it is a promising alternative to conventional attention.
Read more4/30/2024

0
Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
Read more5/20/2024
0
Tensor Attention Training: Provably Efficient Learning of Higher-order Transformers
Jiuxiang Gu, Yingyu Liang, Zhenmei Shi, Zhao Song, Yufa Zhou
Tensor Attention, a multi-view attention that is able to capture high-order correlations among multiple modalities, can overcome the representational limitations of classical matrix attention. However, the $Omega(n^3)$ time complexity of tensor attention poses a significant obstacle to its practical implementation in transformers, where $n$ is the input sequence length. In this work, we prove that the backward gradient of tensor attention training can be computed in almost linear $n^{1+o(1)}$ time, the same complexity as its forward computation under a bounded entries assumption. We provide a closed-form solution for the gradient and propose a fast computation method utilizing polynomial approximation methods and tensor algebraic tricks. Furthermore, we prove the necessity and tightness of our assumption through hardness analysis, showing that slightly weakening it renders the gradient problem unsolvable in truly subcubic time. Our theoretical results establish the feasibility of efficient higher-order transformer training and may facilitate practical applications of tensor attention architectures.
Read more5/28/2024