Agent Attention: On the Integration of Softmax and Linear Attention

1
Sign in to get full access
Overview
- The paper explores the integration of softmax and linear attention mechanisms in transformer models, aiming to improve performance and efficiency.
- It introduces a novel attention module called Agent Attention, which combines the strengths of softmax and linear attention.
- The authors evaluate Agent Attention on various tasks, including image recognition, object detection, and language modeling, demonstrating its advantages over traditional attention mechanisms.
Plain English Explanation
Attention mechanisms are a crucial component of transformer models, which have revolutionized many areas of artificial intelligence, from natural language processing to computer vision. Transformer models use attention to focus on the most relevant parts of their input when generating output.
The paper explores a new way of doing attention called "Agent Attention," which combines two common attention approaches: softmax attention and linear attention. Softmax attention assigns importance to each input element based on its similarity to the current output, while linear attention assigns importance based on a linear transformation of the input.
The key insight of Agent Attention is that by integrating these two approaches, the model can capture both local and global dependencies in the data, leading to improved performance and efficiency. This is particularly useful for tasks like image recognition and object detection, where Mansformer has shown the benefits of hardware-aware attention mechanisms.
By carefully balancing the softmax and linear attention components, the authors demonstrate that Agent Attention can outperform traditional attention mechanisms on a variety of tasks, making it a promising approach for advancing the state of the art in transformer models.
Technical Explanation
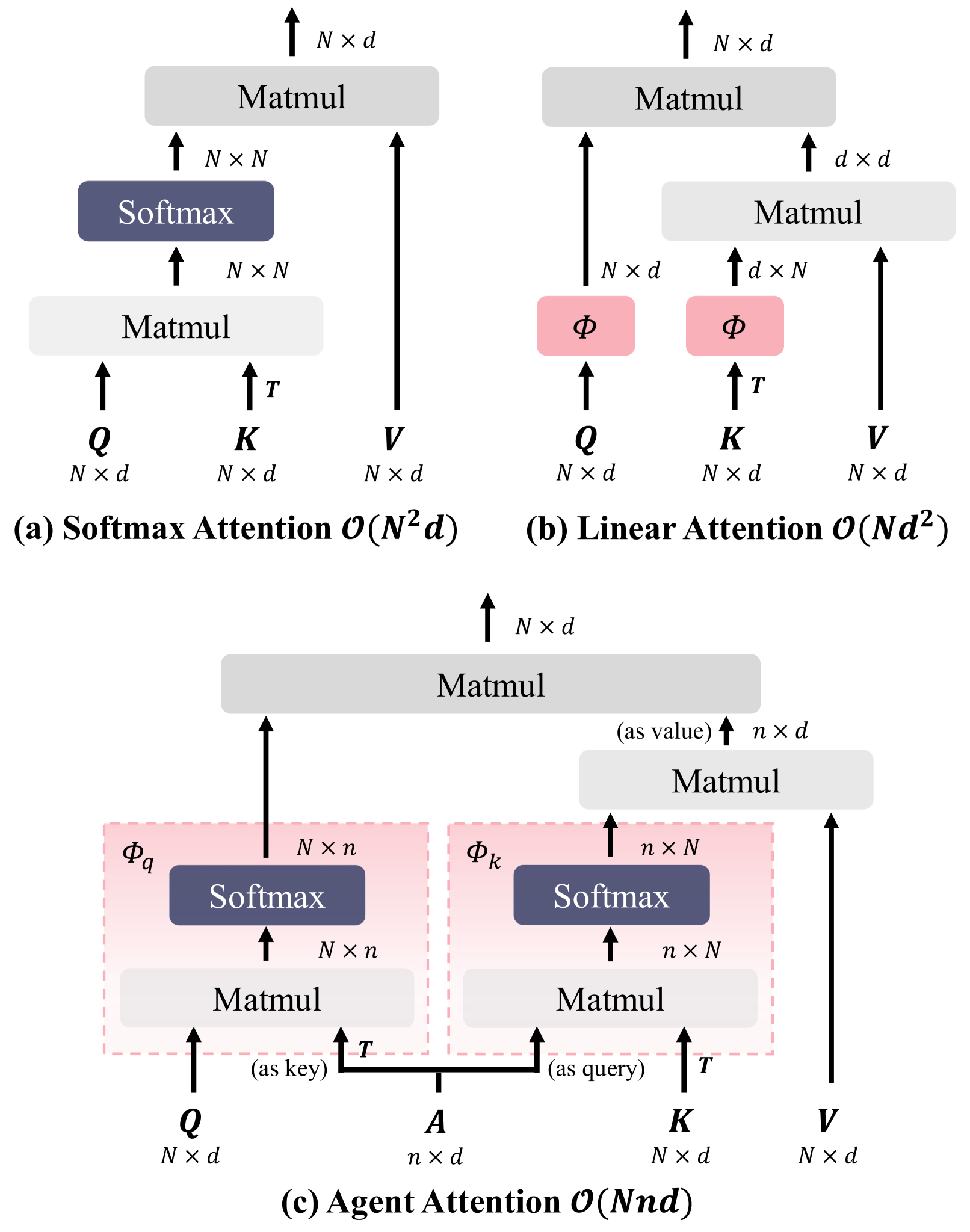
The paper introduces a novel attention module called Agent Attention, which combines softmax and linear attention in a principled way. Softmax attention assigns importance to each input element based on its similarity to the current output, while linear attention assigns importance based on a linear transformation of the input.
The key innovation of Agent Attention is the way it integrates these two attention mechanisms. Instead of using them in isolation, the model learns a set of "agents" that can dynamically switch between softmax and linear attention, depending on the input and the task at hand. This allows the model to capture both local and global dependencies in the data, leading to improved performance and efficiency.
The authors evaluate Agent Attention on a range of tasks, including image recognition, object detection, and language modeling. They show that Agent Attention outperforms traditional attention mechanisms on these tasks, demonstrating its versatility and effectiveness.
One of the strengths of Agent Attention is its ability to adapt to different hardware constraints, as shown in the Mansformer and Lean Attention papers. By balancing the softmax and linear attention components, the authors are able to create a more hardware-aware attention mechanism that can be efficiently deployed on a variety of devices.
Critical Analysis
The paper presents a compelling approach to attention mechanisms, but it's important to consider some potential limitations and areas for further research.
One potential concern is the complexity of the Agent Attention module, which may make it more challenging to optimize and deploy at scale. The authors address this to some extent by showing the module's efficiency on various hardware platforms, but further research may be needed to fully understand its scalability and practical implications.
Additionally, the paper focuses on a relatively narrow set of tasks, and it would be interesting to see how Agent Attention performs on a broader range of applications, such as more complex language understanding or multi-modal tasks. Exploring the generalizability of the approach could help demonstrate its true potential.
Finally, the paper does not delve deeply into the interpretability and explainability of the Agent Attention module. Understanding the inner workings of the attention mechanism and how it makes decisions could be valuable for gaining deeper insights into the model's behavior and for building trust in its use.
Despite these potential areas for further research, the paper makes a significant contribution to the field of attention mechanisms, and the Agent Attention module represents an exciting step forward in the quest to create more powerful and efficient transformer models.
Conclusion
The paper introduces a novel attention mechanism called Agent Attention, which integrates softmax and linear attention in a principled way. By dynamically balancing these two attention approaches, Agent Attention is able to capture both local and global dependencies in the data, leading to improved performance and efficiency on a variety of tasks.
The authors' evaluation of Agent Attention on image recognition, object detection, and language modeling tasks demonstrates its versatility and potential to advance the state of the art in transformer models. The module's hardware-aware design, as shown in the Mansformer and Lean Attention papers, also suggests that it could be effectively deployed on a wide range of devices.
While the paper raises some questions about the complexity and interpretability of the Agent Attention module, its core contribution of integrating softmax and linear attention in a novel way is a significant step forward in the ongoing quest to create more powerful and efficient transformer models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
Agent Attention: On the Integration of Softmax and Linear Attention
Dongchen Han, Tianzhu Ye, Yizeng Han, Zhuofan Xia, Siyuan Pan, Pengfei Wan, Shiji Song, Gao Huang
The attention module is the key component in Transformers. While the global attention mechanism offers high expressiveness, its excessive computational cost restricts its applicability in various scenarios. In this paper, we propose a novel attention paradigm, Agent Attention, to strike a favorable balance between computational efficiency and representation power. Specifically, the Agent Attention, denoted as a quadruple $(Q, A, K, V)$, introduces an additional set of agent tokens $A$ into the conventional attention module. The agent tokens first act as the agent for the query tokens $Q$ to aggregate information from $K$ and $V$, and then broadcast the information back to $Q$. Given the number of agent tokens can be designed to be much smaller than the number of query tokens, the agent attention is significantly more efficient than the widely adopted Softmax attention, while preserving global context modelling capability. Interestingly, we show that the proposed agent attention is equivalent to a generalized form of linear attention. Therefore, agent attention seamlessly integrates the powerful Softmax attention and the highly efficient linear attention. Extensive experiments demonstrate the effectiveness of agent attention with various vision Transformers and across diverse vision tasks, including image classification, object detection, semantic segmentation and image generation. Notably, agent attention has shown remarkable performance in high-resolution scenarios, owning to its linear attention nature. For instance, when applied to Stable Diffusion, our agent attention accelerates generation and substantially enhances image generation quality without any additional training. Code is available at https://github.com/LeapLabTHU/Agent-Attention.
Read more7/16/2024
✅
1
Attention as an RNN
Leo Feng, Frederick Tung, Hossein Hajimirsadeghi, Mohamed Osama Ahmed, Yoshua Bengio, Greg Mori
The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
Read more5/29/2024

0
TaylorShift: Shifting the Complexity of Self-Attention from Squared to Linear (and Back) using Taylor-Softmax
Tobias Christian Nauen, Sebastian Palacio, Andreas Dengel
The quadratic complexity of the attention mechanism represents one of the biggest hurdles for processing long sequences using Transformers. Current methods, relying on sparse representations or stateful recurrence, sacrifice token-to-token interactions, which ultimately leads to compromises in performance. This paper introduces TaylorShift, a novel reformulation of the Taylor softmax that enables computing full token-to-token interactions in linear time and space. We analytically determine the crossover points where employing TaylorShift becomes more efficient than traditional attention, aligning closely with empirical measurements. Specifically, our findings demonstrate that TaylorShift enhances memory efficiency for sequences as short as 800 tokens and accelerates inference for inputs of approximately 1700 tokens and beyond. For shorter sequences, TaylorShift scales comparably with the vanilla attention. Furthermore, a classification benchmark across five tasks involving long sequences reveals no degradation in accuracy when employing Transformers equipped with TaylorShift. For reproducibility, we provide access to our code under https://github.com/tobna/TaylorShift.
Read more7/18/2024
🤿
0
Softmax Attention with Constant Cost per Token
Franz A. Heinsen
We propose a simple modification to the conventional attention mechanism applied by Transformers: Instead of quantifying pairwise query-key similarity with scaled dot-products, we quantify it with the logarithms of scaled dot-products of exponentials. Our modification linearizes attention with exponential kernel feature maps, whose corresponding feature function is infinite dimensional. We show that our modification is expressible as a composition of log-sums of exponentials, with a latent space of constant size, enabling application with constant time and space complexity per token. We implement our modification, verify that it works in practice, and conclude that it is a promising alternative to conventional attention.
Read more4/30/2024