TC-LLaVA: Rethinking the Transfer from Image to Video Understanding with Temporal Considerations

0

Sign in to get full access
Overview
- TC-LLaVA: Rethinking the Transfer from Image to Video Understanding with Temporal Considerations
- Proposes a novel transformer-based model that leverages the temporal dynamics of video for improved video understanding
- Achieves state-of-the-art performance on several video understanding benchmarks
Plain English Explanation
The paper introduces TC-LLaVA, a new model for understanding video content. Traditional approaches to video understanding often rely on transferring knowledge from image-based models, which may not fully capture the dynamic nature of video.
TC-LLaVA aims to address this by explicitly incorporating temporal considerations into the model. It does this through a novel transformer-based architecture that can effectively learn and leverage the temporal patterns and dynamics present in video data.
The key innovations of TC-LLaVA include:
- Temporal-Aware Transformer: A transformer-based module that models the temporal relationships between video frames, rather than treating them independently.
- Cross-Modal Interaction: Mechanisms that allow the model to dynamically integrate information from both the visual and textual modalities, enabling richer video understanding.
- Lightweight Design: The model is designed to be computationally efficient, making it practical for real-world applications.
By incorporating these temporal and cross-modal elements, TC-LLaVA is able to outperform previous state-of-the-art models on several video understanding benchmarks, demonstrating the value of this approach.
Technical Explanation
The TC-LLaVA model is built upon a transformer-based architecture, which has proven effective for a wide range of natural language and vision tasks. However, the authors identify a key limitation of existing transformer-based models for video understanding - they often treat video frames independently, failing to fully capture the temporal dynamics that are crucial for understanding video content.
To address this, TC-LLaVA introduces a Temporal-Aware Transformer module that explicitly models the temporal relationships between video frames. This module leverages a specialized attention mechanism that considers both the spatial and temporal dimensions of the input video, enabling the model to learn and exploit the temporal patterns present in the data.
Additionally, TC-LLaVA incorporates a Cross-Modal Interaction component that allows the model to dynamically integrate information from both the visual and textual modalities. This enables the model to establish richer connections between the visual and semantic elements of the video, leading to more comprehensive video understanding.
The authors also design TC-LLaVA to be computationally efficient, making it practical for real-world applications. This is achieved through the use of lightweight transformer modules and careful architectural choices.
Critical Analysis
The authors of the paper have made a compelling case for the importance of incorporating temporal considerations into video understanding models. Their TC-LLaVA approach represents a significant advancement over previous methods that primarily relied on transferring knowledge from image-based models.
However, the paper does not extensively discuss the limitations or potential drawbacks of the proposed approach. For example, it would be valuable to understand the computational and memory requirements of TC-LLaVA compared to simpler video understanding models, as well as any potential trade-offs in terms of model complexity and performance.
Additionally, the authors could have provided more detailed analysis of the model's performance on specific video understanding tasks and subtasks, as well as a more comprehensive evaluation of its robustness and generalization capabilities across diverse video datasets.
Conclusion
The TC-LLaVA model presented in this paper represents an important step forward in video understanding by explicitly incorporating temporal considerations into a transformer-based architecture. The model's strong performance on several benchmarks suggests that this approach can lead to significant improvements in our ability to comprehend and reason about video content.
As the field of video understanding continues to evolve, the insights and techniques introduced in this paper could inspire further research into more sophisticated temporal modeling and cross-modal interaction mechanisms, ultimately driving progress towards more advanced and practical video understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TC-LLaVA: Rethinking the Transfer from Image to Video Understanding with Temporal Considerations
Mingze Gao, Jingyu Liu, Mingda Li, Jiangtao Xie, Qingbin Liu, Bo Zhao, Xi Chen, Hui Xiong
Multimodal Large Language Models (MLLMs) have significantly improved performance across various image-language applications. Recently, there has been a growing interest in adapting image pre-trained MLLMs for video-related tasks. However, most efforts concentrate on enhancing the vision encoder and projector components, while the core part, Large Language Models (LLMs), remains comparatively under-explored. In this paper, we propose two strategies to enhance the model's capability in video understanding tasks by improving inter-layer attention computation in LLMs. Specifically, the first approach focuses on the enhancement of Rotary Position Embedding (RoPE) with Temporal-Aware Dual RoPE, which introduces temporal position information to strengthen the MLLM's temporal modeling capabilities while preserving the relative position relationships of both visual and text tokens. The second approach involves enhancing the Attention Mask with the Frame-wise Block Causal Attention Mask, a simple yet effective method that broadens visual token interactions within and across video frames while maintaining the causal inference mechanism. Based on these proposed methods, we adapt LLaVA for video understanding tasks, naming it Temporal-Considered LLaVA (TC-LLaVA). Our TC-LLaVA achieves new state-of-the-art performance across various video understanding benchmarks with only supervised fine-tuning (SFT) on video-related datasets.
Read more9/6/2024

0
PiTe: Pixel-Temporal Alignment for Large Video-Language Model
Yang Liu, Pengxiang Ding, Siteng Huang, Min Zhang, Han Zhao, Donglin Wang
Fueled by the Large Language Models (LLMs) wave, Large Visual-Language Models (LVLMs) have emerged as a pivotal advancement, bridging the gap between image and text. However, video making it challenging for LVLMs to perform adequately due to the complexity of the relationship between language and spatial-temporal data structure. Recent Large Video-Language Models (LVidLMs) align feature of static visual data like image into latent space of language feature, by general multi-modal tasks to leverage abilities of LLMs sufficiently. In this paper, we explore fine-grained alignment approach via object trajectory for different modalities across both spatial and temporal dimensions simultaneously. Thus, we propose a novel LVidLM by trajectory-guided Pixel-Temporal Alignment, dubbed PiTe, that exhibits promising applicable model property. To achieve fine-grained video-language alignment, we curate a multi-modal pre-training dataset PiTe-143k, the dataset provision of moving trajectories in pixel level for all individual objects, that appear and mention in the video and caption both, by our automatic annotation pipeline. Meanwhile, PiTe demonstrates astounding capabilities on myriad video-related multi-modal tasks through beat the state-of-the-art methods by a large margin.
Read more9/12/2024
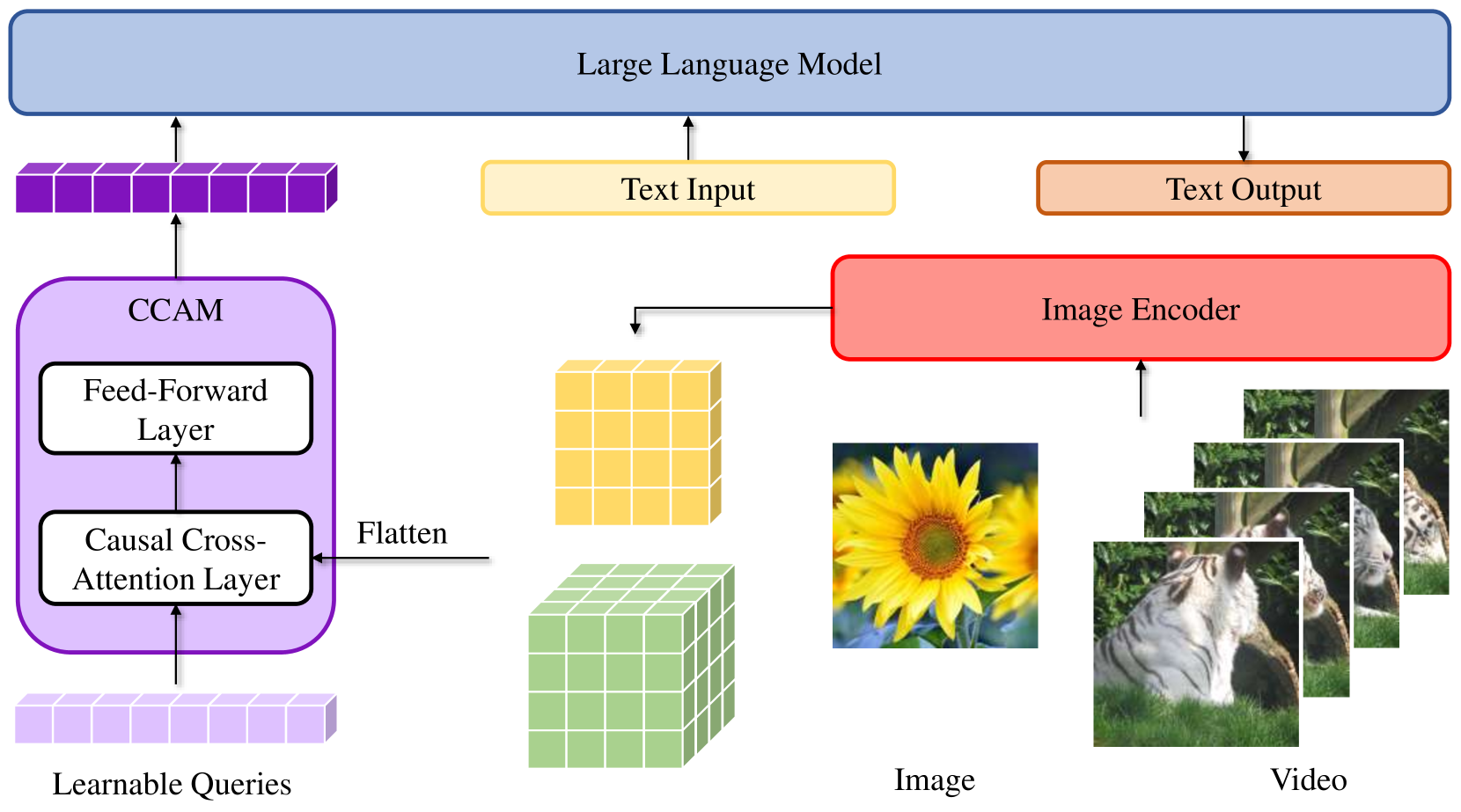
0
Video-CCAM: Enhancing Video-Language Understanding with Causal Cross-Attention Masks for Short and Long Videos
Jiajun Fei, Dian Li, Zhidong Deng, Zekun Wang, Gang Liu, Hui Wang
Multi-modal large language models (MLLMs) have demonstrated considerable potential across various downstream tasks that require cross-domain knowledge. MLLMs capable of processing videos, known as Video-MLLMs, have attracted broad interest in video-language understanding. However, videos, especially long videos, contain more visual tokens than images, making them difficult for LLMs to process. Existing works either downsample visual features or extend the LLM context size, risking the loss of high-resolution information or slowing down inference speed. To address these limitations, we apply cross-attention layers in the intermediate projector between the visual encoder and the large language model (LLM). As the naive cross-attention mechanism is insensitive to temporal order, we further introduce causal cross-attention masks (CCAMs) within the cross-attention layers. This Video-MLLM, named Video-CCAM, is trained in a straightforward two-stage fashion: feature alignment and visual instruction tuning. We develop several Video-CCAM models based on LLMs of different sizes (4B, 9B, and 14B). Video-CCAM proves to be a robust Video-MLLM and shows outstanding performance from short videos to long ones. Among standard video benchmarks like MVBench and VideoChatGPT-QA, Video-CCAM shows outstanding performances (1st/2nd/3rd in MVBench and TGIF-QA, 2nd/3rd/4th in MSVD-QA, MSRVTT-QA, and ActivityNet-QA). In benchmarks encompassing long videos, Video-CCAM models can be directly adapted to long video understanding and still achieve exceptional scores despite being trained solely with images and 16-frame videos. Using 96 frames (6$times$ the training number of frames), Video-CCAM models rank 1st/2nd/3rd in VideoVista and 1st/2nd/4th in MLVU among all open-source Video-MLLMs, respectively. The code is publicly available in url{https://github.com/QQ-MM/Video-CCAM}.
Read more8/27/2024

0
VideoLLaMB: Long-context Video Understanding with Recurrent Memory Bridges
Yuxuan Wang, Cihang Xie, Yang Liu, Zilong Zheng
Recent advancements in large-scale video-language models have shown significant potential for real-time planning and detailed interactions. However, their high computational demands and the scarcity of annotated datasets limit their practicality for academic researchers. In this work, we introduce VideoLLaMB, a novel framework that utilizes temporal memory tokens within bridge layers to allow for the encoding of entire video sequences alongside historical visual data, effectively preserving semantic continuity and enhancing model performance across various tasks. This approach includes recurrent memory tokens and a SceneTilling algorithm, which segments videos into independent semantic units to preserve semantic integrity. Empirically, VideoLLaMB significantly outstrips existing video-language models, demonstrating a 5.5 points improvement over its competitors across three VideoQA benchmarks, and 2.06 points on egocentric planning. Comprehensive results on the MVBench show that VideoLLaMB-7B achieves markedly better results than previous 7B models of same LLM. Remarkably, it maintains robust performance as PLLaVA even as video length increases up to 8 times. Besides, the frame retrieval results on our specialized Needle in a Video Haystack (NIAVH) benchmark, further validate VideoLLaMB's prowess in accurately identifying specific frames within lengthy videos. Our SceneTilling algorithm also enables the generation of streaming video captions directly, without necessitating additional training. In terms of efficiency, VideoLLaMB, trained on 16 frames, supports up to 320 frames on a single Nvidia A100 GPU with linear GPU memory scaling, ensuring both high performance and cost-effectiveness, thereby setting a new foundation for long-form video-language models in both academic and practical applications.
Read more9/4/2024