VideoLLaMB: Long-context Video Understanding with Recurrent Memory Bridges

0

Sign in to get full access
Overview
- VideoLLaMB is a new model for understanding long-context videos using recurrent memory bridges.
- It aims to capture relationships and dependencies across long video sequences to improve video understanding.
- The paper presents the VideoLLaMB architecture and experimental results on various video understanding tasks.
Plain English Explanation
VideoLLaMB is a machine learning model designed to better understand long videos. Traditional video understanding models often struggle to capture the relationships and dependencies that exist across long video sequences. VideoLLaMB introduces a novel "recurrent memory bridge" mechanism to address this challenge.
The recurrent memory bridge allows the model to maintain and update a persistent memory representation as it processes a video frame-by-frame. This enables the model to retain important contextual information and make connections between events that may be separated by a long time in the video. By incorporating this long-term memory, VideoLLaMB can gain a more holistic understanding of the video content and perform tasks like video captioning, action recognition, and video question answering more effectively.
The paper demonstrates the benefits of VideoLLaMB's long-context understanding through experiments on several video understanding benchmarks. The results show that VideoLLaMB outperforms traditional video models, particularly on tasks that require reasoning about long-term relationships and dependencies in the video.
Technical Explanation
The VideoLLaMB architecture consists of a video encoder, a recurrent memory bridge, and task-specific output heads. The video encoder processes the input video frames and generates contextualized representations. The recurrent memory bridge then maintains and updates a persistent memory representation as the video is processed sequentially.
This memory bridge is implemented using a recurrent neural network, which allows the model to store and carry forward relevant information from previous frames. The task-specific output heads then use the enhanced video representations, combined with the recurrent memory, to perform various video understanding tasks.
The experiments evaluate VideoLLaMB on a range of video understanding benchmarks, including video captioning, action recognition, and video question answering. The results demonstrate that VideoLLaMB's long-context understanding leads to significant performance improvements compared to baseline models that do not have the recurrent memory bridge.
Critical Analysis
The paper acknowledges that VideoLLaMB is a complex model with a large number of parameters, which may limit its efficiency and applicability in certain real-world scenarios. The authors suggest that future work should explore ways to make the model more compact and efficient, perhaps through techniques like model compression or knowledge distillation.
Additionally, the experiments in the paper are conducted on a limited set of video understanding tasks and datasets. It would be valuable to see the model's performance evaluated on a wider range of video understanding benchmarks, particularly those that involve more diverse and challenging video content.
Overall, the VideoLLaMB model represents an interesting and promising approach to addressing the long-context challenge in video understanding. The recurrent memory bridge mechanism is a clever innovation that could inspire further research in this area.
Conclusion
The VideoLLaMB paper presents a new model for video understanding that leverages a recurrent memory bridge to capture long-term relationships and dependencies in video sequences. The results demonstrate the benefits of this approach, particularly on tasks that require reasoning about long-term context.
While the model has some complexity and efficiency considerations, the core ideas behind VideoLLaMB could have significant implications for the field of video understanding. By enabling models to better learn and retain the meaningful connections across long video sequences, VideoLLaMB and similar approaches could lead to substantial improvements in a wide range of video-based applications, from video captioning and action recognition to video question answering and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VideoLLaMB: Long-context Video Understanding with Recurrent Memory Bridges
Yuxuan Wang, Cihang Xie, Yang Liu, Zilong Zheng
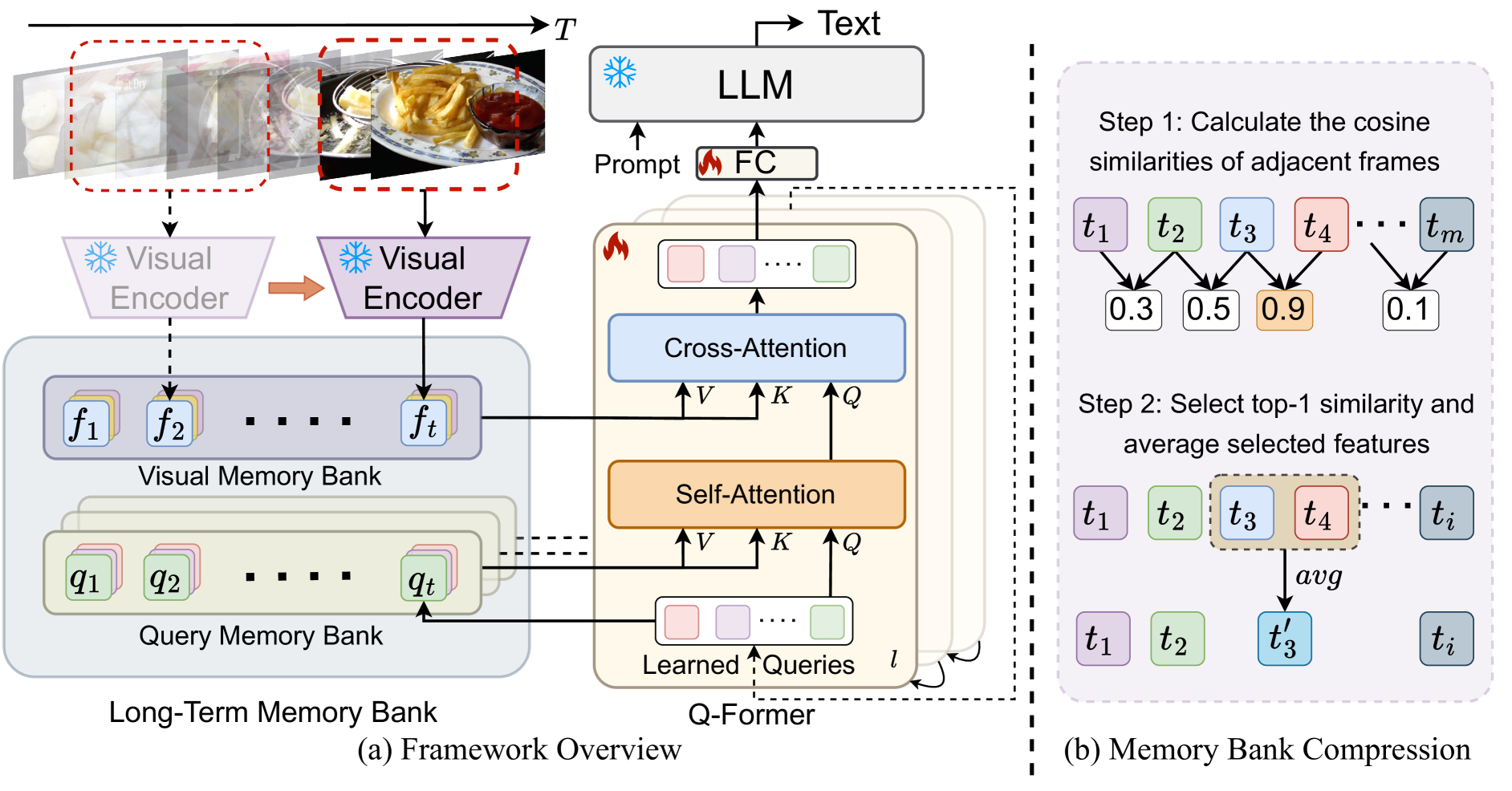
Recent advancements in large-scale video-language models have shown significant potential for real-time planning and detailed interactions. However, their high computational demands and the scarcity of annotated datasets limit their practicality for academic researchers. In this work, we introduce VideoLLaMB, a novel framework that utilizes temporal memory tokens within bridge layers to allow for the encoding of entire video sequences alongside historical visual data, effectively preserving semantic continuity and enhancing model performance across various tasks. This approach includes recurrent memory tokens and a SceneTilling algorithm, which segments videos into independent semantic units to preserve semantic integrity. Empirically, VideoLLaMB significantly outstrips existing video-language models, demonstrating a 5.5 points improvement over its competitors across three VideoQA benchmarks, and 2.06 points on egocentric planning. Comprehensive results on the MVBench show that VideoLLaMB-7B achieves markedly better results than previous 7B models of same LLM. Remarkably, it maintains robust performance as PLLaVA even as video length increases up to 8 times. Besides, the frame retrieval results on our specialized Needle in a Video Haystack (NIAVH) benchmark, further validate VideoLLaMB's prowess in accurately identifying specific frames within lengthy videos. Our SceneTilling algorithm also enables the generation of streaming video captions directly, without necessitating additional training. In terms of efficiency, VideoLLaMB, trained on 16 frames, supports up to 320 frames on a single Nvidia A100 GPU with linear GPU memory scaling, ensuring both high performance and cost-effectiveness, thereby setting a new foundation for long-form video-language models in both academic and practical applications.
Read more9/4/2024
0
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, Ser-Nam Lim
With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
Read more4/9/2024
0
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
Empowered by Large Language Models (LLMs), recent advancements in Video-based LLMs (VideoLLMs) have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a simple yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples show that our model produces more precise responses for long video understanding. Code is available at https://github.com/ziplab/LongVLM.
Read more7/23/2024

0
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, Ziwei Liu
Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.
Read more7/2/2024