Video-CCAM: Enhancing Video-Language Understanding with Causal Cross-Attention Masks for Short and Long Videos

0
Sign in to get full access
Overview
- The paper introduces Video-CCAM, a model for enhancing video-language understanding with causal cross-attention masks for both short and long videos.
- It proposes a novel cross-attention mechanism to capture long-range dependencies in video and language data.
- The model is evaluated on multiple video-language tasks, including video question answering and video captioning.
Plain English Explanation
The paper presents a new AI model called Video-CCAM that is designed to better understand the relationship between video and language. This is an important task for applications like video question answering and video captioning.
The key innovation of Video-CCAM is a "causal cross-attention mask" that helps the model capture long-range dependencies between the video and language data. This allows the model to better understand the context and meaning, even in longer videos.
The researchers evaluate Video-CCAM on several benchmark tasks and show that it outperforms previous state-of-the-art models, especially for longer videos. This suggests the causal cross-attention masks are an effective way to enhance video-language understanding.
Technical Explanation
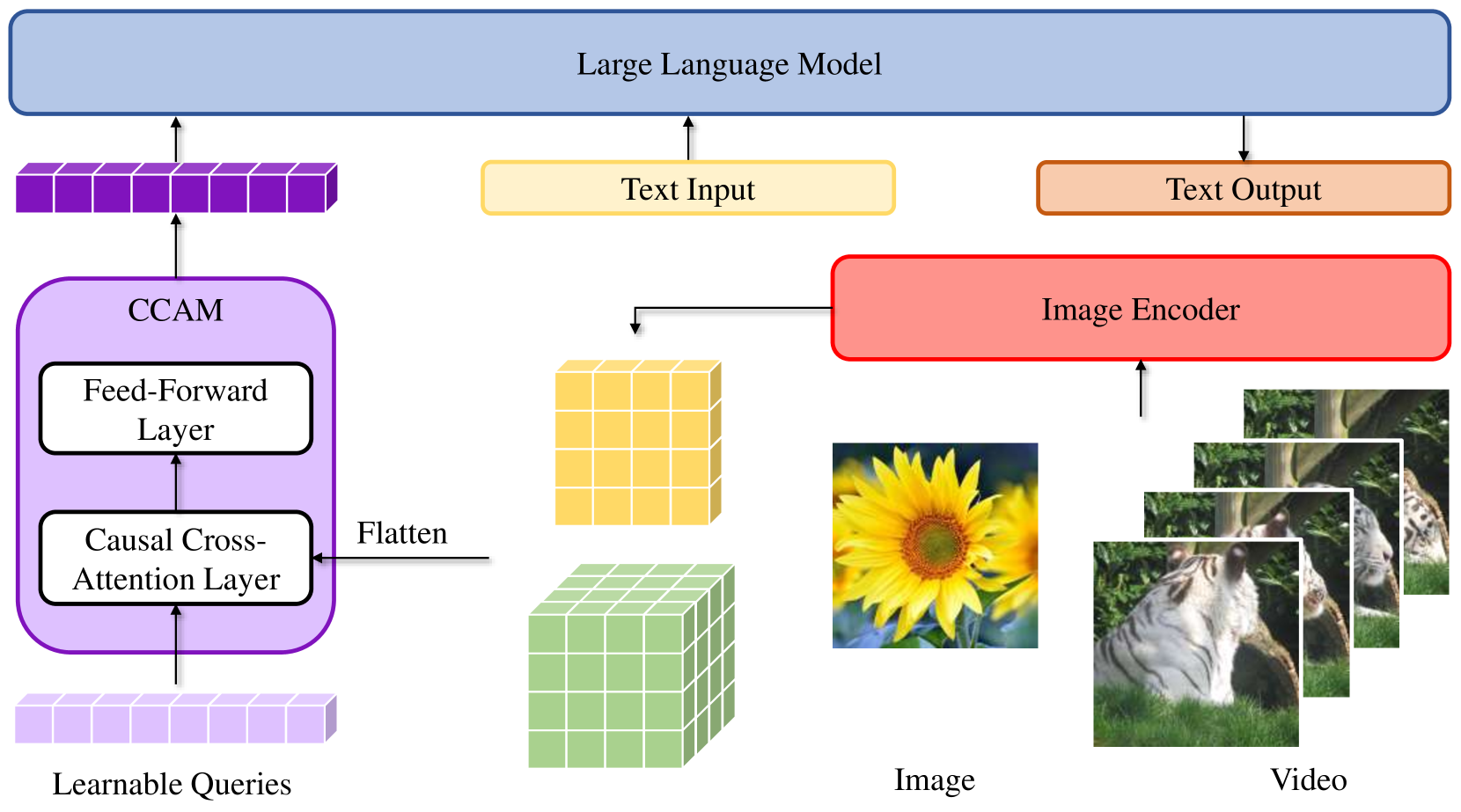
The Video-CCAM model uses a transformer-based architecture to process video and language data. A key component is the causal cross-attention mask, which is applied to the cross-attention layers.
This mask constrains the attention to only attend to relevant parts of the video and language sequences, capturing long-range dependencies that are important for understanding the context. The researchers argue this is crucial for tasks involving longer videos.
The model is evaluated on several video-language benchmarks, including video question answering and video captioning. The results show significant improvements over previous state-of-the-art models, particularly for longer videos.
Critical Analysis
The paper provides a novel approach to enhancing video-language understanding, but there are a few potential limitations:
-
The paper does not extensively explore the interpretability of the causal cross-attention masks - it would be interesting to understand what specific long-range relationships the model is learning.
-
The experiments are conducted on standard benchmark datasets, but it's unclear how the model would perform on more real-world, noisy video-language data.
-
While the model shows strong performance compared to prior work, there may be opportunities to further improve efficiency or generalize to even longer videos.
Conclusion
Overall, the Video-CCAM model presents a promising approach to enhancing video-language understanding, particularly for longer videos. The causal cross-attention masks appear to be an effective technique for capturing relevant long-range dependencies. Further research could explore the model's interpretability and real-world applicability to drive continued progress in this important area of multimodal AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Video-CCAM: Enhancing Video-Language Understanding with Causal Cross-Attention Masks for Short and Long Videos
Jiajun Fei, Dian Li, Zhidong Deng, Zekun Wang, Gang Liu, Hui Wang
Multi-modal large language models (MLLMs) have demonstrated considerable potential across various downstream tasks that require cross-domain knowledge. MLLMs capable of processing videos, known as Video-MLLMs, have attracted broad interest in video-language understanding. However, videos, especially long videos, contain more visual tokens than images, making them difficult for LLMs to process. Existing works either downsample visual features or extend the LLM context size, risking the loss of high-resolution information or slowing down inference speed. To address these limitations, we apply cross-attention layers in the intermediate projector between the visual encoder and the large language model (LLM). As the naive cross-attention mechanism is insensitive to temporal order, we further introduce causal cross-attention masks (CCAMs) within the cross-attention layers. This Video-MLLM, named Video-CCAM, is trained in a straightforward two-stage fashion: feature alignment and visual instruction tuning. We develop several Video-CCAM models based on LLMs of different sizes (4B, 9B, and 14B). Video-CCAM proves to be a robust Video-MLLM and shows outstanding performance from short videos to long ones. Among standard video benchmarks like MVBench and VideoChatGPT-QA, Video-CCAM shows outstanding performances (1st/2nd/3rd in MVBench and TGIF-QA, 2nd/3rd/4th in MSVD-QA, MSRVTT-QA, and ActivityNet-QA). In benchmarks encompassing long videos, Video-CCAM models can be directly adapted to long video understanding and still achieve exceptional scores despite being trained solely with images and 16-frame videos. Using 96 frames (6$times$ the training number of frames), Video-CCAM models rank 1st/2nd/3rd in VideoVista and 1st/2nd/4th in MLVU among all open-source Video-MLLMs, respectively. The code is publicly available in url{https://github.com/QQ-MM/Video-CCAM}.
Read more8/27/2024

0
TC-LLaVA: Rethinking the Transfer from Image to Video Understanding with Temporal Considerations
Mingze Gao, Jingyu Liu, Mingda Li, Jiangtao Xie, Qingbin Liu, Bo Zhao, Xi Chen, Hui Xiong
Multimodal Large Language Models (MLLMs) have significantly improved performance across various image-language applications. Recently, there has been a growing interest in adapting image pre-trained MLLMs for video-related tasks. However, most efforts concentrate on enhancing the vision encoder and projector components, while the core part, Large Language Models (LLMs), remains comparatively under-explored. In this paper, we propose two strategies to enhance the model's capability in video understanding tasks by improving inter-layer attention computation in LLMs. Specifically, the first approach focuses on the enhancement of Rotary Position Embedding (RoPE) with Temporal-Aware Dual RoPE, which introduces temporal position information to strengthen the MLLM's temporal modeling capabilities while preserving the relative position relationships of both visual and text tokens. The second approach involves enhancing the Attention Mask with the Frame-wise Block Causal Attention Mask, a simple yet effective method that broadens visual token interactions within and across video frames while maintaining the causal inference mechanism. Based on these proposed methods, we adapt LLaVA for video understanding tasks, naming it Temporal-Considered LLaVA (TC-LLaVA). Our TC-LLaVA achieves new state-of-the-art performance across various video understanding benchmarks with only supervised fine-tuning (SFT) on video-related datasets.
Read more9/6/2024

0
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, Ziwei Liu
Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.
Read more7/2/2024
0
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
Empowered by Large Language Models (LLMs), recent advancements in Video-based LLMs (VideoLLMs) have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a simple yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples show that our model produces more precise responses for long video understanding. Code is available at https://github.com/ziplab/LongVLM.
Read more7/23/2024