Teach CLIP to Develop a Number Sense for Ordinal Regression

0

Sign in to get full access
Overview
- Teaches CLIP, a popular vision-language model, to develop a "number sense" for ordinal regression tasks
- Ordinal regression is the task of predicting an ordered categorical variable, like a rating or ranking
- The paper proposes novel training methods to help CLIP learn this skill without extensive fine-tuning
Plain English Explanation
This paper tackles the challenge of teaching CLIP, a powerful vision-language model, to perform ordinal regression tasks. Ordinal regression involves predicting ordered categories, like rating a product on a scale of 1-5 stars.
The key insight is that CLIP, while great at tasks like image classification, does not inherently have a "number sense" needed for ordinal regression. The researchers developed new training methods to imbue CLIP with this capability, without the need for extensive fine-tuning on specialized datasets.
Their approach involves exposing CLIP to images annotated with ordered labels during pre-training. This helps the model learn to associate visual cues with the relative ordering of categories. They also introduce a novel contrastive loss function to reinforce this ordinal understanding.
The result is a CLIP model that can perform ordinal regression tasks, like predicting movie ratings or product rankings, with high accuracy. This is an important advancement, as it allows CLIP to be applied to a wider range of real-world problems that involve graded or ranked outputs.
Technical Explanation
The paper proposes two key innovations to teach CLIP a "number sense" for ordinal regression:
-
Ordinal-aware Pre-training: The researchers augment CLIP's pre-training dataset with images annotated with ordered labels (e.g., 1-5 star ratings). This exposure to ordinal information during pre-training helps the model develop an innate understanding of relative magnitudes.
-
Ordinal Contrastive Loss: In addition to the standard contrastive loss used to train CLIP, the authors introduce a novel loss function that specifically encourages the model to preserve the ordinal relationships between different label categories. This reinforces the model's grasp of ordinal semantics.
Through these techniques, the modified CLIP model is able to perform ordinal regression tasks, like predicting movie ratings or product rankings, with high accuracy. The paper demonstrates the effectiveness of this approach on several benchmark datasets.
Critical Analysis
The paper presents a novel and compelling approach to enhancing CLIP's capabilities for ordinal regression tasks. By incorporating ordinal information during pre-training and fine-tuning, the researchers have successfully imbued the model with a "number sense" that allows it to effectively handle graded prediction problems.
One potential limitation is the reliance on specific pre-training and loss function modifications. While these techniques prove effective, it's unclear how generalizable they are to other vision-language models or ordinal regression tasks. Further research may be needed to understand the broader applicability of this approach.
Additionally, the paper does not address potential biases or fairness concerns that could arise when deploying such a model in real-world applications. It would be valuable for future work to explore these important considerations.
Conclusion
This paper presents a novel approach to teaching CLIP, a powerful vision-language model, to perform ordinal regression tasks. By incorporating ordinal information during pre-training and fine-tuning, the researchers have successfully enhanced CLIP's "number sense" and its ability to handle graded prediction problems.
This advancement is significant, as it expands the range of real-world applications where CLIP can be effectively deployed, from product ratings to movie reviews. The techniques demonstrated in this paper could inspire similar efforts to refine and specialize other prominent vision-language models for diverse tasks.
As AI systems become increasingly integrated into our daily lives, it's crucial that they develop robust and nuanced capabilities, like the ordinal understanding showcased in this research. This paper represents an important step towards building more refined and capable AI systems that can better serve the needs of users and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Teach CLIP to Develop a Number Sense for Ordinal Regression
Yao Du, Qiang Zhai, Weihang Dai, Xiaomeng Li
Ordinal regression is a fundamental problem within the field of computer vision, with customised well-trained models on specific tasks. While pre-trained vision-language models (VLMs) have exhibited impressive performance on various vision tasks, their potential for ordinal regression has received less exploration. In this study, we first investigate CLIP's potential for ordinal regression, from which we expect the model could generalise to different ordinal regression tasks and scenarios. Unfortunately, vanilla CLIP fails on this task, since current VLMs have a well-documented limitation of encapsulating compositional concepts such as number sense. We propose a simple yet effective method called NumCLIP to improve the quantitative understanding of VLMs. We disassemble the exact image to number-specific text matching problem into coarse classification and fine prediction stages. We discretize and phrase each numerical bin with common language concept to better leverage the available pre-trained alignment in CLIP. To consider the inherent continuous property of ordinal regression, we propose a novel fine-grained cross-modal ranking-based regularisation loss specifically designed to keep both semantic and ordinal alignment in CLIP's feature space. Experimental results on three general ordinal regression tasks demonstrate the effectiveness of NumCLIP, with 10% and 3.83% accuracy improvement on historical image dating and image aesthetics assessment task, respectively. Code is publicly available at https://github.com/xmed-lab/NumCLIP.
Read more8/9/2024
❗
0
CountCLIP -- [Re] Teaching CLIP to Count to Ten
Harshvardhan Mestha, Tejas Agrawal, Karan Bania, Shreyas V, Yash Bhisikar
Large vision-language models (VLMs) are shown to learn rich joint image-text representations enabling high performances in relevant downstream tasks. However, they fail to showcase their quantitative understanding of objects, and they lack good counting-aware representation. This paper conducts a reproducibility study of 'Teaching CLIP to Count to Ten' (Paiss et al., 2023), which presents a method to finetune a CLIP model (Radford et al., 2021) to improve zero-shot counting accuracy in an image while maintaining the performance for zero-shot classification by introducing a counting-contrastive loss term. We improve the model's performance on a smaller subset of their training data with lower computational resources. We verify these claims by reproducing their study with our own code. The implementation can be found at https://github.com/SforAiDl/CountCLIP.
Read more6/11/2024

0
RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
Read more6/21/2024
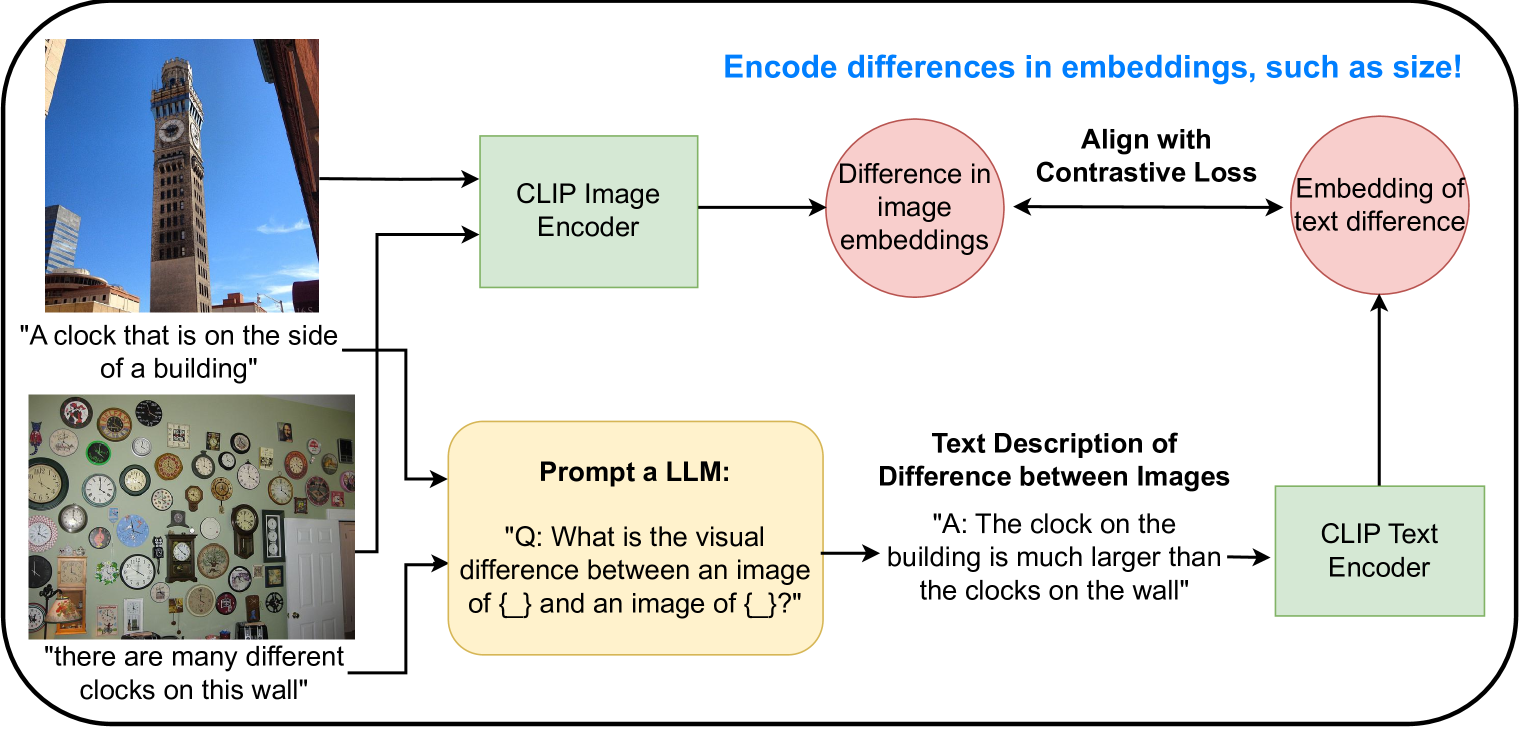
0
New!Finetuning CLIP to Reason about Pairwise Differences
Dylan Sam, Devin Willmott, Joao D. Semedo, J. Zico Kolter
Vision-language models (VLMs) such as CLIP are trained via contrastive learning between text and image pairs, resulting in aligned image and text embeddings that are useful for many downstream tasks. A notable drawback of CLIP, however, is that the resulting embedding space seems to lack some of the structure of their purely text-based alternatives. For instance, while text embeddings have been long noted to satisfy emph{analogies} in embedding space using vector arithmetic, CLIP has no such property. In this paper, we propose an approach to natively train CLIP in a contrastive manner to reason about differences in embedding space. We finetune CLIP so that the differences in image embedding space correspond to emph{text descriptions of the image differences}, which we synthetically generate with large language models on image-caption paired datasets. We first demonstrate that our approach yields significantly improved capabilities in ranking images by a certain attribute (e.g., elephants are larger than cats), which is useful in retrieval or constructing attribute-based classifiers, and improved zeroshot classification performance on many downstream image classification tasks. In addition, our approach enables a new mechanism for inference that we refer to as comparative prompting, where we leverage prior knowledge of text descriptions of differences between classes of interest, achieving even larger performance gains in classification. Finally, we illustrate that the resulting embeddings obey a larger degree of geometric properties in embedding space, such as in text-to-image generation.
Read more9/17/2024