Finetuning CLIP to Reason about Pairwise Differences

0
Sign in to get full access
Overview
- This paper explores finetuning the CLIP model to reason about pairwise differences between images.
- CLIP is a large language-vision model that can perform various image-text tasks.
- The researchers aim to enhance CLIP's ability to understand and describe the differences between pairs of images.
Plain English Explanation
The researchers in this paper wanted to see if they could improve the CLIP model's ability to understand the differences between pairs of images. CLIP is a powerful model that can do many tasks involving both images and text, like describing what's in an image or finding related images for a given text. But the researchers thought CLIP could be even better at noticing the specific ways that two images differ from each other.
To do this, they "finetuned" CLIP - they took the already-trained CLIP model and did some extra training on a dataset focused on pairwise image differences. This allowed CLIP to learn more about how to identify and describe the differences between similar images.
The researchers tested CLIP's new pairwise difference skills on some benchmark datasets, and found that the finetuned CLIP model outperformed the original CLIP at tasks like describing how two images differ and picking out the key differences between them. This suggests that finetuning CLIP in this way can make it better at this specific type of visual reasoning.
Overall, this work shows how large language-vision models like CLIP can be adapted and improved to tackle more nuanced tasks beyond just general image classification or description. By focusing the training on a specific capability, the researchers were able to enhance CLIP's skills in an important area.
Technical Explanation
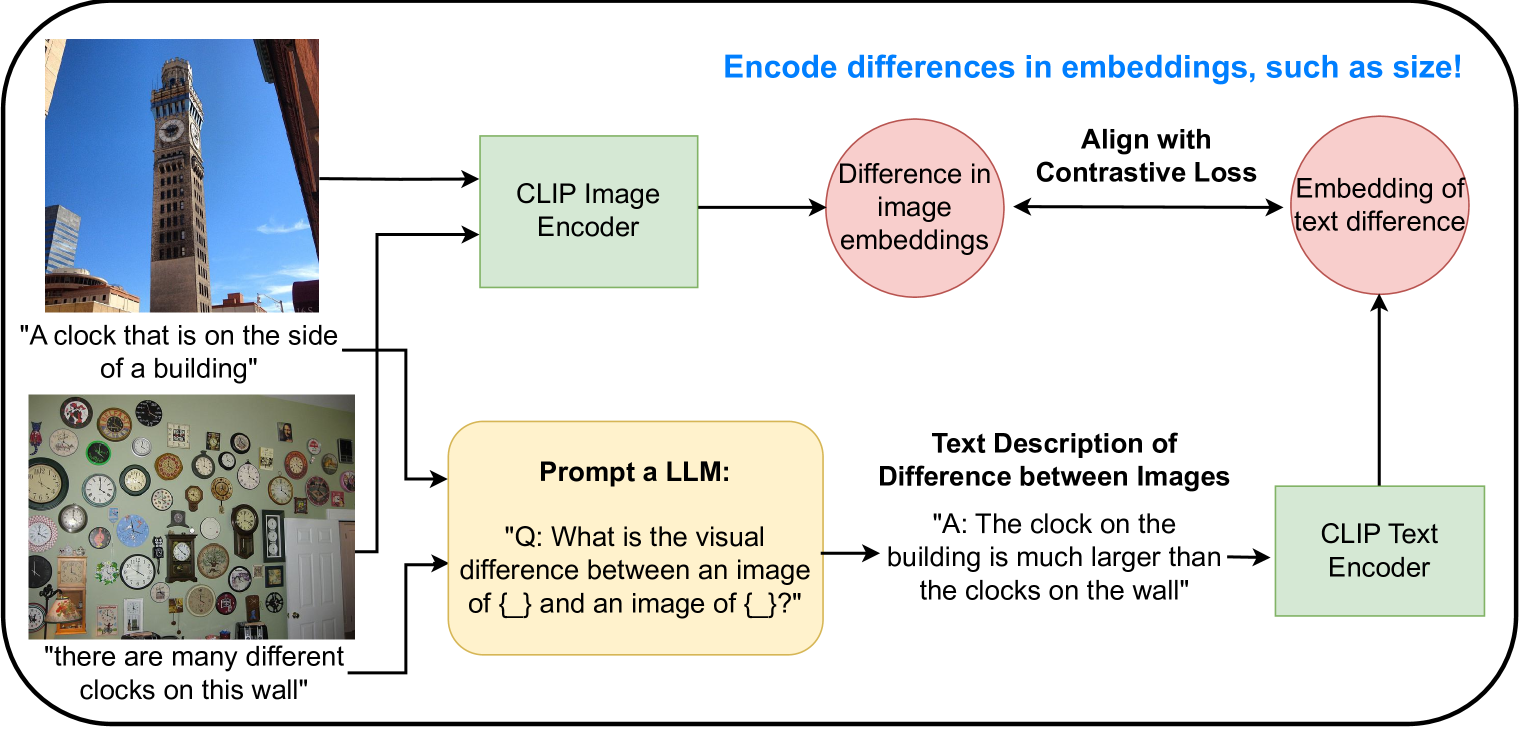
The paper introduces a method for finetuning the CLIP model to reason about pairwise differences between images. CLIP is a large-scale pre-trained language-vision model that can perform a variety of image-text tasks.
The researchers hypothesized that CLIP's pre-training on broad image-text data may not fully capture its ability to reason about the specific differences between pairs of visually-similar images. To address this, they introduce a finetuning procedure that trains CLIP on a dataset focused on pairwise image differences.
The finetuning dataset consists of image pairs along with annotations describing their key differences. During training, the model learns to predict the difference text given the two input images. The researchers also experiment with contrastive and ranking-based losses to further enhance CLIP's ability to reason about pairwise differences.
Experiments on standard pairwise difference benchmarks show that the finetuned CLIP model significantly outperforms the original CLIP on tasks like difference captioning and difference attribute prediction. This demonstrates that the finetuning approach can effectively specialize CLIP's capabilities to the domain of pairwise visual reasoning.
Critical Analysis
The paper provides a compelling approach to improving CLIP's ability to reason about pairwise image differences, an important capability for many real-world applications. The finetuning strategy and use of specialized datasets and loss functions seem well-motivated and effectively implemented.
One potential limitation is the reliance on fairly constrained benchmark datasets for evaluation. While these provide standardized tests, it would be valuable to also assess the finetuned model's performance on more diverse or real-world pairwise difference tasks. The paper acknowledges this as an area for future work.
Additionally, the paper does not deeply explore the interpretability or explainability of the finetuned model's pairwise difference reasoning. Understanding the specific visual cues and linguistic patterns the model learns could yield further insights.
Overall, this work represents a thoughtful and impactful contribution to enhancing the capabilities of large language-vision models like CLIP. The finetuning approach offers a general strategy for tailoring these powerful models to specialized tasks, with broader implications for the field of multimodal AI.
Conclusion
This paper demonstrates an effective method for finetuning the CLIP model to reason more effectively about pairwise differences between images. By training CLIP on a specialized dataset focused on describing image differences, the researchers were able to significantly improve its performance on benchmark tasks like difference captioning and attribute prediction.
This work highlights the adaptability of large language-vision models like CLIP, and shows how their capabilities can be enhanced through targeted finetuning. The ability to reason about visual differences is an important skill for many real-world applications, from product comparison to medical image analysis.
Overall, this research contributes valuable insights into how we can continue to push the boundaries of what multimodal AI models can achieve, moving beyond generic image classification or description towards more nuanced and contextual visual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Finetuning CLIP to Reason about Pairwise Differences
Dylan Sam, Devin Willmott, Joao D. Semedo, J. Zico Kolter
Vision-language models (VLMs) such as CLIP are trained via contrastive learning between text and image pairs, resulting in aligned image and text embeddings that are useful for many downstream tasks. A notable drawback of CLIP, however, is that the resulting embedding space seems to lack some of the structure of their purely text-based alternatives. For instance, while text embeddings have been long noted to satisfy emph{analogies} in embedding space using vector arithmetic, CLIP has no such property. In this paper, we propose an approach to natively train CLIP in a contrastive manner to reason about differences in embedding space. We finetune CLIP so that the differences in image embedding space correspond to emph{text descriptions of the image differences}, which we synthetically generate with large language models on image-caption paired datasets. We first demonstrate that our approach yields significantly improved capabilities in ranking images by a certain attribute (e.g., elephants are larger than cats), which is useful in retrieval or constructing attribute-based classifiers, and improved zeroshot classification performance on many downstream image classification tasks. In addition, our approach enables a new mechanism for inference that we refer to as comparative prompting, where we leverage prior knowledge of text descriptions of differences between classes of interest, achieving even larger performance gains in classification. Finally, we illustrate that the resulting embeddings obey a larger degree of geometric properties in embedding space, such as in text-to-image generation.
Read more9/17/2024

0
Optimizing CLIP Models for Image Retrieval with Maintained Joint-Embedding Alignment
Konstantin Schall, Kai Uwe Barthel, Nico Hezel, Klaus Jung
Contrastive Language and Image Pairing (CLIP), a transformative method in multimedia retrieval, typically trains two neural networks concurrently to generate joint embeddings for text and image pairs. However, when applied directly, these models often struggle to differentiate between visually distinct images that have similar captions, resulting in suboptimal performance for image-based similarity searches. This paper addresses the challenge of optimizing CLIP models for various image-based similarity search scenarios, while maintaining their effectiveness in text-based search tasks such as text-to-image retrieval and zero-shot classification. We propose and evaluate two novel methods aimed at refining the retrieval capabilities of CLIP without compromising the alignment between text and image embeddings. The first method involves a sequential fine-tuning process: initially optimizing the image encoder for more precise image retrieval and subsequently realigning the text encoder to these optimized image embeddings. The second approach integrates pseudo-captions during the retrieval-optimization phase to foster direct alignment within the embedding space. Through comprehensive experiments, we demonstrate that these methods enhance CLIP's performance on various benchmarks, including image retrieval, k-NN classification, and zero-shot text-based classification, while maintaining robustness in text-to-image retrieval. Our optimized models permit maintaining a single embedding per image, significantly simplifying the infrastructure needed for large-scale multi-modal similarity search systems.
Read more9/4/2024
0
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
Read more5/15/2024

0
RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
Read more6/21/2024