Teaching Large Language Models to Express Knowledge Boundary from Their Own Signals
2406.10881
0
0

Abstract
Large language models (LLMs) have achieved great success, but their occasional content fabrication, or hallucination, limits their practical application. Hallucination arises because LLMs struggle to admit ignorance due to inadequate training on knowledge boundaries. We call it a limitation of LLMs that they can not accurately express their knowledge boundary, answering questions they know while admitting ignorance to questions they do not know. In this paper, we aim to teach LLMs to recognize and express their knowledge boundary, so they can reduce hallucinations caused by fabricating when they do not know. We propose CoKE, which first probes LLMs' knowledge boundary via internal confidence given a set of questions, and then leverages the probing results to elicit the expression of the knowledge boundary. Extensive experiments show CoKE helps LLMs express knowledge boundaries, answering known questions while declining unknown ones, significantly improving in-domain and out-of-domain performance.
Create account to get full access
Overview
- The paper explores techniques for teaching large language models (LLMs) to express the boundaries of their own knowledge and capabilities, which is crucial for their safe and reliable deployment.
- It examines methods to help LLMs recognize when they lack the necessary knowledge or understanding to provide a reliable response, rather than hallucinating or guessing.
- The research investigates approaches to improve the knowledge verification and rejection capabilities of LLMs, with the goal of enhancing their reliability and trustworthiness.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, a key challenge with these models is that they can sometimes produce responses that seem plausible but are actually incorrect or based on incomplete knowledge. This is known as "hallucination," where the model makes up information instead of acknowledging the limitations of its knowledge.
To address this issue, the researchers in this paper explored ways to teach LLMs to be more self-aware about the boundaries of their knowledge. They investigated methods to help the models recognize when they lack the necessary information to provide a reliable answer, and instead express uncertainty or explicitly state that they don't know.
The goal is to improve the knowledge verification and rejection capabilities of LLMs, making them more reliable and trustworthy in real-world applications. This could involve training the models to identify when they are unsure or when their responses are not well-grounded in their training data.
By developing these self-awareness and knowledge expression capabilities, the researchers aim to create LLMs that are better equipped to acknowledge the limits of their understanding and avoid providing potentially harmful or misleading information. This is a crucial step towards making these powerful AI systems more safe and reliable for use in a wide range of domains.
Technical Explanation
The paper explores techniques for teaching large language models (LLMs) to express the boundaries of their own knowledge and capabilities. This is motivated by the problem of "hallucination," where LLMs can generate plausible-sounding but incorrect responses due to gaps in their knowledge or understanding.
The researchers investigate methods to improve the knowledge verification and rejection capabilities of LLMs, with the goal of enhancing their reliability and trustworthiness. This includes exploring approaches to help LLMs recognize when they lack the necessary knowledge to provide a reliable response, and training them to refuse to answer questions outside the scope of their capabilities.
The paper also discusses techniques for benchmarking the knowledge boundaries of different LLMs and understanding how LLMs' perceptions of their own knowledge and capabilities can differ from their actual abilities.
Overall, the research aims to develop LLMs that are more self-aware and capable of expressing the limits of their knowledge, which is crucial for their safe and reliable deployment in real-world applications.
Critical Analysis
The paper presents a valuable approach to addressing the hallucination problem in large language models, but there are a few caveats and areas for further research that could be explored:
-
The proposed methods for improving knowledge verification and rejection capabilities have been tested on a limited set of LLMs and datasets. Further research is needed to evaluate the effectiveness of these techniques across a wider range of models and use cases.
-
The paper does not fully address the challenge of quantifying the uncertainty or confidence of LLM responses, which is essential for users to understand the reliability of the information being provided.
-
The researchers acknowledge that their approach of training LLMs to refuse questions outside their knowledge boundaries could potentially limit the models' overall capabilities and usefulness. Balancing knowledge expression with maintaining broad functionality is an area that requires further investigation.
-
The paper focuses on improving the self-awareness of individual LLMs, but there may also be value in exploring ways to leverage the collective knowledge and capabilities of ensembles or networks of LLMs to enhance overall reliability and trustworthiness.
Despite these areas for further research, the core ideas presented in the paper represent an important step towards developing more reliable and trustworthy large language models that can better understand and express the boundaries of their own knowledge and capabilities.
Conclusion
This paper explores techniques for teaching large language models (LLMs) to express the boundaries of their own knowledge and capabilities, a crucial step for ensuring the safe and reliable deployment of these powerful AI systems.
The researchers investigate methods to improve LLMs' knowledge verification and rejection capabilities, enabling them to recognize when they lack the necessary information to provide a reliable response and express uncertainty or refuse to answer, rather than hallucinating or guessing.
By developing these self-awareness and knowledge expression capabilities, the researchers aim to create LLMs that are more trustworthy and better equipped to acknowledge the limits of their understanding, avoiding the potential harms of providing incorrect or misleading information.
While further research is needed to fully address the challenges of quantifying uncertainty and balancing knowledge expression with maintaining broad functionality, the core ideas presented in this paper represent an important contribution towards realizing the full potential of large language models in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Perception of Knowledge Boundary for Large Language Models through Semi-open-ended Question Answering
Zhihua Wen, Zhiliang Tian, Zexin Jian, Zhen Huang, Pei Ke, Yifu Gao, Minlie Huang, Dongsheng Li
0
0
Large Language Models (LLMs) are widely used for knowledge-seeking yet suffer from hallucinations. The knowledge boundary (KB) of an LLM limits its factual understanding, beyond which it may begin to hallucinate. Investigating the perception of LLMs' KB is crucial for detecting hallucinations and LLMs' reliable generation. Current studies perceive LLMs' KB on questions with a concrete answer (close-ended questions) while paying limited attention to semi-open-ended questions (SoeQ) that correspond to many potential answers. Some researchers achieve it by judging whether the question is answerable or not. However, this paradigm is unsuitable for SoeQ, which are usually partially answerable, containing both answerable and ambiguous (unanswerable) answers. Ambiguous answers are essential for knowledge-seeking, but they may go beyond the KB of LLMs. In this paper, we perceive the LLMs' KB with SoeQ by discovering more ambiguous answers. First, we apply an LLM-based approach to construct SoeQ and obtain answers from a target LLM. Unfortunately, the output probabilities of mainstream black-box LLMs are inaccessible to sample for low-probability ambiguous answers. Therefore, we apply an open-sourced auxiliary model to explore ambiguous answers for the target LLM. We calculate the nearest semantic representation for existing answers to estimate their probabilities, with which we reduce the generation probability of high-probability answers to achieve a more effective generation. Finally, we compare the results from the RAG-based evaluation and LLM self-evaluation to categorize four types of ambiguous answers that are beyond the KB of the target LLM. Following our method, we construct a dataset to perceive the KB for GPT-4. We find that GPT-4 performs poorly on SoeQ and is often unaware of its KB. Besides, our auxiliary model, LLaMA-2-13B, is effective in discovering more ambiguous answers.
5/24/2024
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
0
0
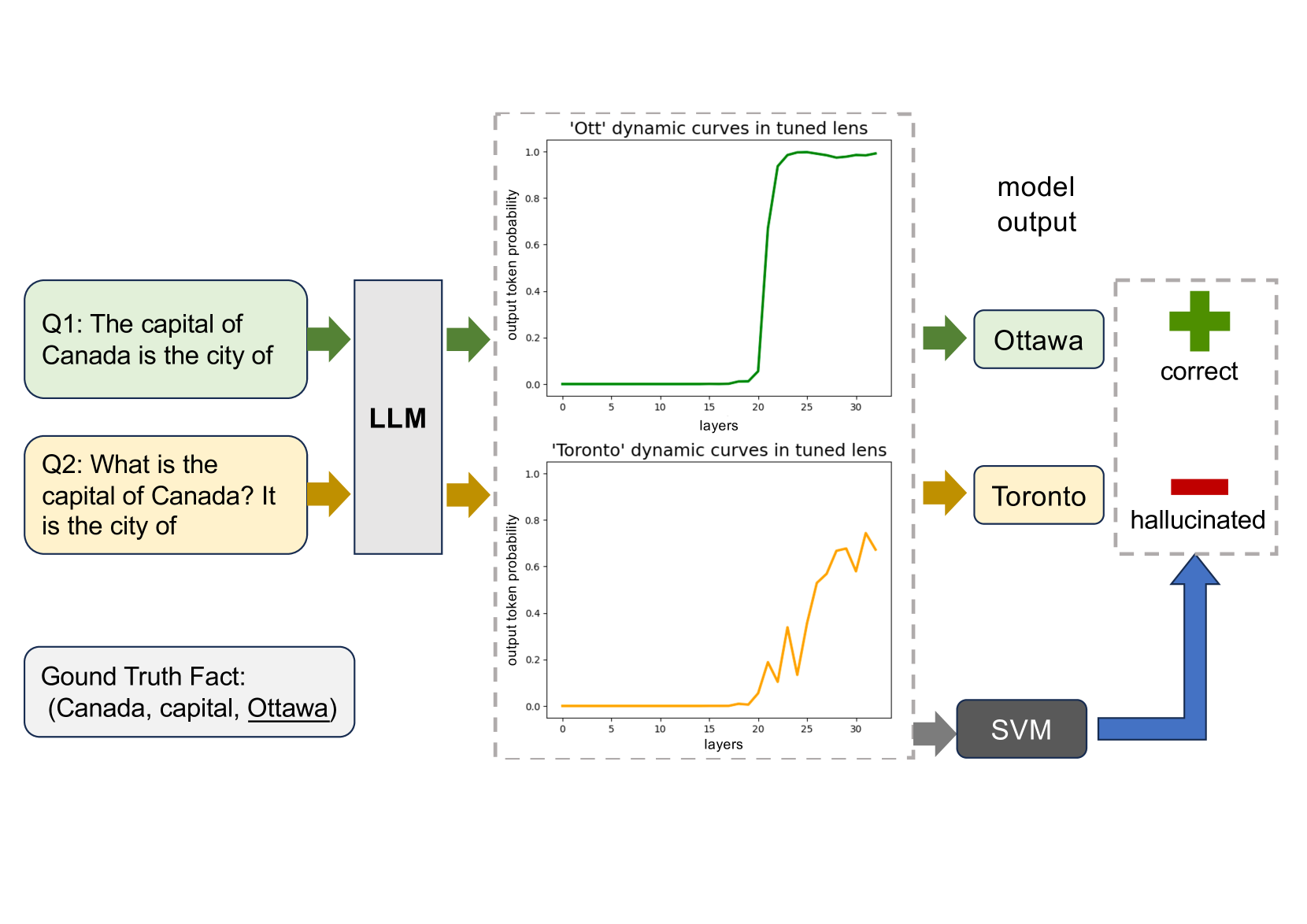
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
4/1/2024

New!Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration
Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, Yulia Tsvetkov
0
0
Despite efforts to expand the knowledge of large language models (LLMs), knowledge gaps -- missing or outdated information in LLMs -- might always persist given the evolving nature of knowledge. In this work, we study approaches to identify LLM knowledge gaps and abstain from answering questions when knowledge gaps are present. We first adapt existing approaches to model calibration or adaptation through fine-tuning/prompting and analyze their ability to abstain from generating low-confidence outputs. Motivated by their failures in self-reflection and over-reliance on held-out sets, we propose two novel approaches that are based on model collaboration, i.e., LLMs probing other LLMs for knowledge gaps, either cooperatively or competitively. Extensive experiments with three LLMs on four QA tasks featuring diverse knowledge domains demonstrate that both cooperative and competitive approaches to unveiling LLM knowledge gaps achieve up to 19.3% improvements on abstain accuracy against the strongest baseline. Further analysis reveals that our proposed mechanisms could help identify failure cases in retrieval augmentation and pinpoint knowledge gaps in multi-hop reasoning.
7/2/2024
Rejection Improves Reliability: Training LLMs to Refuse Unknown Questions Using RL from Knowledge Feedback
Hongshen Xu, Zichen Zhu, Situo Zhang, Da Ma, Shuai Fan, Lu Chen, Kai Yu
0
0
Large Language Models (LLMs) often generate erroneous outputs, known as hallucinations, due to their limitations in discerning questions beyond their knowledge scope. While addressing hallucination has been a focal point in research, previous efforts primarily concentrate on enhancing correctness without giving due consideration to the significance of rejection mechanisms. In this paper, we conduct a comprehensive examination of the role of rejection, introducing the notion of model reliability along with corresponding metrics. These metrics measure the model's ability to provide accurate responses while adeptly rejecting questions exceeding its knowledge boundaries, thereby minimizing hallucinations. To improve the inherent reliability of LLMs, we present a novel alignment framework called Reinforcement Learning from Knowledge Feedback (RLKF). RLKF leverages knowledge feedback to dynamically determine the model's knowledge boundary and trains a reliable reward model to encourage the refusal of out-of-knowledge questions. Experimental results on mathematical questions affirm the substantial efficacy of RLKF in significantly enhancing LLM reliability.
4/9/2024