Perception of Knowledge Boundary for Large Language Models through Semi-open-ended Question Answering
2405.14383
0
0
💬
Abstract
Large Language Models (LLMs) are widely used for knowledge-seeking yet suffer from hallucinations. The knowledge boundary (KB) of an LLM limits its factual understanding, beyond which it may begin to hallucinate. Investigating the perception of LLMs' KB is crucial for detecting hallucinations and LLMs' reliable generation. Current studies perceive LLMs' KB on questions with a concrete answer (close-ended questions) while paying limited attention to semi-open-ended questions (SoeQ) that correspond to many potential answers. Some researchers achieve it by judging whether the question is answerable or not. However, this paradigm is unsuitable for SoeQ, which are usually partially answerable, containing both answerable and ambiguous (unanswerable) answers. Ambiguous answers are essential for knowledge-seeking, but they may go beyond the KB of LLMs. In this paper, we perceive the LLMs' KB with SoeQ by discovering more ambiguous answers. First, we apply an LLM-based approach to construct SoeQ and obtain answers from a target LLM. Unfortunately, the output probabilities of mainstream black-box LLMs are inaccessible to sample for low-probability ambiguous answers. Therefore, we apply an open-sourced auxiliary model to explore ambiguous answers for the target LLM. We calculate the nearest semantic representation for existing answers to estimate their probabilities, with which we reduce the generation probability of high-probability answers to achieve a more effective generation. Finally, we compare the results from the RAG-based evaluation and LLM self-evaluation to categorize four types of ambiguous answers that are beyond the KB of the target LLM. Following our method, we construct a dataset to perceive the KB for GPT-4. We find that GPT-4 performs poorly on SoeQ and is often unaware of its KB. Besides, our auxiliary model, LLaMA-2-13B, is effective in discovering more ambiguous answers.
Create account to get full access
Overview
- Large Language Models (LLMs) are widely used for knowledge-seeking, but they can suffer from hallucinations - generating information that is not factually accurate.
- The knowledge boundary (KB) of an LLM limits its factual understanding, and when it goes beyond that KB, it may start hallucinating.
- Investigating how LLMs perceive their own KB is crucial for detecting hallucinations and ensuring the reliable generation of information.
- Current studies focus on close-ended questions with concrete answers, but pay limited attention to semi-open-ended questions (SoeQ) that have many potential answers.
- Ambiguous answers are essential for knowledge-seeking, but they may go beyond the KB of LLMs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can be used to search for and generate information. However, these models can sometimes produce information that is not accurate or factual. This is known as "hallucination." The reason for this is that LLMs have a limited understanding of the world, known as their "knowledge boundary" (KB). When they try to generate information that goes beyond their KB, they can start to hallucinate.
Researchers have been studying how to detect when LLMs are hallucinating and how to ensure they generate reliable information. So far, most of this research has focused on questions with clear, concrete answers. But there are also many questions that have multiple possible answers, known as "semi-open-ended questions" (SoeQs). These types of questions are important for knowledge-seeking, but they can also be challenging for LLMs, as the ambiguous answers may go beyond the model's KB.
In this paper, the researchers propose a new way to investigate how LLMs perceive their own KB, especially when it comes to SoeQs. They use a machine learning approach to generate SoeQs and then get answers from a target LLM. Unfortunately, the inner workings of many LLMs are not accessible, making it difficult to sample the low-probability "ambiguous" answers that may be beyond the model's KB. To overcome this, the researchers use an auxiliary model to help explore these ambiguous answers.
By comparing the results from this approach to the LLM's own self-evaluation, the researchers were able to identify four types of ambiguous answers that were beyond the KB of the target LLM, in this case, GPT-4. They found that GPT-4 often struggles with SoeQs and is not always aware of the limits of its own knowledge.
Technical Explanation
The researchers in this paper investigated the perception of Large Language Models' (LLMs) knowledge boundaries (KB) when it comes to semi-open-ended questions (SoeQ). SoeQs are questions that can have multiple potential answers, in contrast to close-ended questions with a single concrete answer.
The researchers first used an LLM-based approach to construct SoeQs and obtain answers from a target LLM, in this case GPT-4. However, they found that the output probabilities of mainstream black-box LLMs are not accessible, making it difficult to sample the low-probability "ambiguous" answers that may be beyond the model's KB.
To overcome this, the researchers applied an open-sourced auxiliary model, LLaMA-2-13B, to explore the ambiguous answers for the target LLM. They calculated the nearest semantic representation for existing answers to estimate their probabilities, and then reduced the generation probability of high-probability answers to discover more ambiguous answers.
By comparing the results from this approach to the LLM's own self-evaluation, the researchers were able to categorize four types of ambiguous answers that were beyond the KB of GPT-4:
- Answerable with missing information
- Partially answerable
- Ambiguous with multiple valid answers
- Completely unanswerable
The researchers found that GPT-4 often struggled with SoeQs and was not always aware of the limits of its own knowledge, frequently generating responses that went beyond its KB and resulted in hallucinations.
Critical Analysis
The researchers' approach of using an auxiliary model to explore ambiguous answers for the target LLM is a novel and promising technique. By reducing the generation probability of high-probability answers, they were able to uncover more low-probability ambiguous answers that may be beyond the LLM's KB.
However, the researchers acknowledge that their method is limited by the capabilities of the auxiliary model, which may not be able to accurately estimate the probabilities of all possible answers. Additionally, the researchers only tested their approach on GPT-4, and it's unclear how well it would generalize to other LLMs.
Furthermore, the researchers did not delve into the potential reasons why LLMs like GPT-4 struggle with SoeQs and are often unaware of the limits of their KB. Investigating the underlying causes of these issues could lead to important insights and inform the development of more robust and reliable LLMs.
Future research could also explore the potential applications of this approach, such as using it to improve LLM-based systems for knowledge-seeking or decision-making tasks. By better understanding the boundaries of an LLM's knowledge, we can develop more effective ways to leverage these powerful models while mitigating the risk of hallucinations.
Conclusion
This paper presents a novel approach to investigating the knowledge boundaries of large language models, with a focus on semi-open-ended questions. The researchers found that LLMs like GPT-4 often struggle with these types of questions and are not always aware of the limits of their own knowledge, leading to hallucinations.
By using an auxiliary model to explore ambiguous answers, the researchers were able to uncover several types of answers that were beyond the KB of the target LLM. This work highlights the importance of understanding the knowledge boundaries of LLMs and the need for more robust and reliable language models that can better recognize the limits of their own understanding.
As LLMs become increasingly pervasive in knowledge-seeking and decision-making tasks, it is crucial that we develop techniques to ensure their outputs are factually accurate and trustworthy. The insights from this research can contribute to the ongoing efforts to improve the safety and reliability of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Teaching Large Language Models to Express Knowledge Boundary from Their Own Signals
Lida Chen, Zujie Liang, Xintao Wang, Jiaqing Liang, Yanghua Xiao, Feng Wei, Jinglei Chen, Zhenghong Hao, Bing Han, Wei Wang
0
0
Large language models (LLMs) have achieved great success, but their occasional content fabrication, or hallucination, limits their practical application. Hallucination arises because LLMs struggle to admit ignorance due to inadequate training on knowledge boundaries. We call it a limitation of LLMs that they can not accurately express their knowledge boundary, answering questions they know while admitting ignorance to questions they do not know. In this paper, we aim to teach LLMs to recognize and express their knowledge boundary, so they can reduce hallucinations caused by fabricating when they do not know. We propose CoKE, which first probes LLMs' knowledge boundary via internal confidence given a set of questions, and then leverages the probing results to elicit the expression of the knowledge boundary. Extensive experiments show CoKE helps LLMs express knowledge boundaries, answering known questions while declining unknown ones, significantly improving in-domain and out-of-domain performance.
6/18/2024
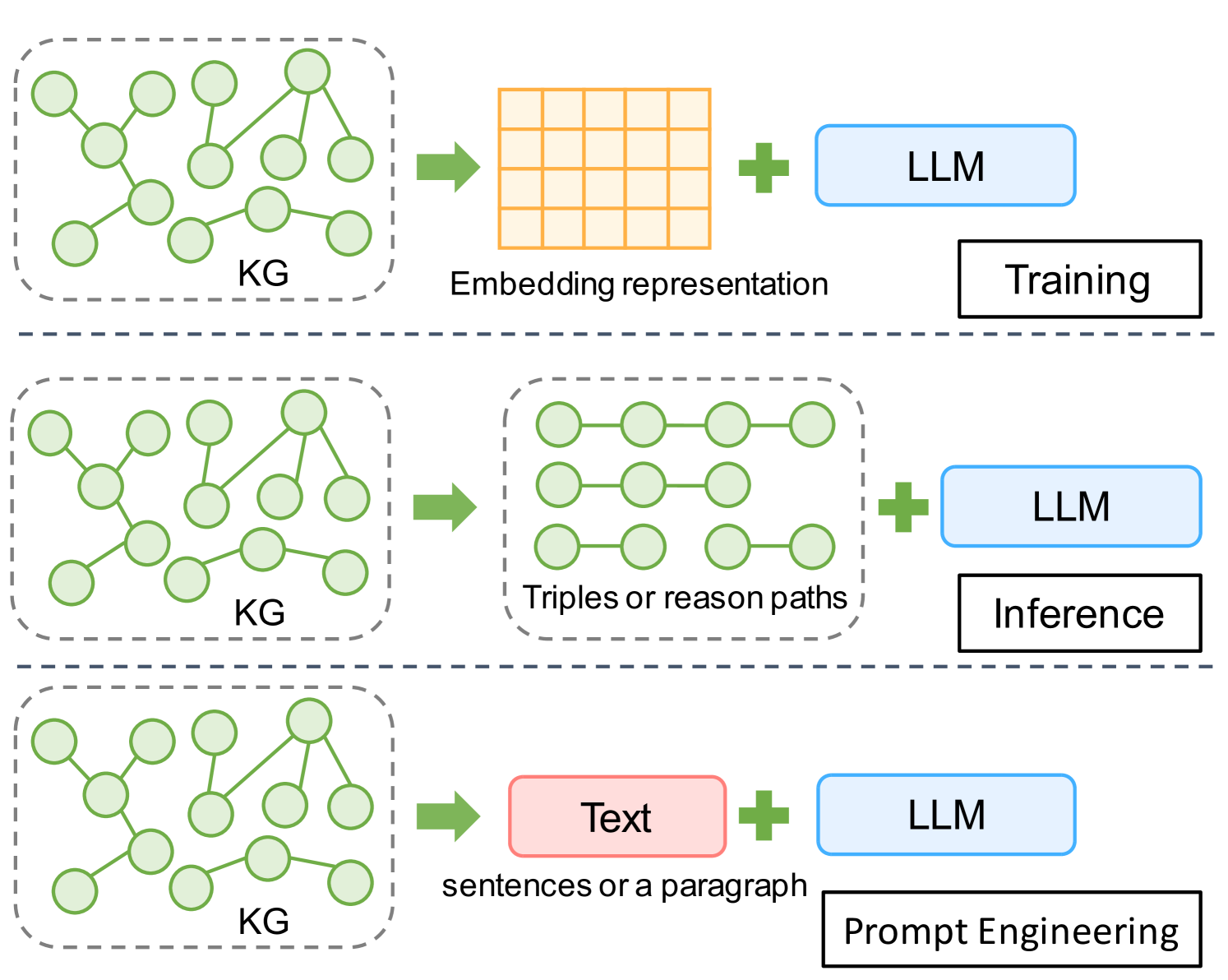
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024
💬
Knowledge of Knowledge: Exploring Known-Unknowns Uncertainty with Large Language Models
Alfonso Amayuelas, Liangming Pan, Wenhu Chen, William Wang
0
0
This paper investigates the capabilities of Large Language Models (LLMs) in the context of understanding their knowledge and uncertainty over questions. Specifically, we focus on addressing known-unknown questions, characterized by high uncertainty due to the absence of definitive answers. To facilitate our study, we collect a new dataset with Known-Unknown Questions (KUQ) and establish a categorization framework to clarify the origins of uncertainty in such queries. Subsequently, we examine the performance of open-source LLMs, fine-tuned using this dataset, in distinguishing between known and unknown queries within open-ended question-answering scenarios. The fine-tuned models demonstrated a significant improvement, achieving a considerable increase in F1-score relative to their pre-fine-tuning state. Through a comprehensive analysis, we reveal insights into the models' improved uncertainty articulation and their consequent efficacy in multi-agent debates. These findings help us understand how LLMs can be trained to identify and express uncertainty, improving our knowledge of how they understand and express complex or unclear information.
6/24/2024
💬
How Proficient Are Large Language Models in Formal Languages? An In-Depth Insight for Knowledge Base Question Answering
Jinxin Liu, Shulin Cao, Jiaxin Shi, Tingjian Zhang, Lunyiu Nie, Linmei Hu, Lei Hou, Juanzi Li
0
0
Knowledge Base Question Answering (KBQA) aims to answer natural language questions based on facts in knowledge bases. A typical approach to KBQA is semantic parsing, which translates a question into an executable logical form in a formal language. Recent works leverage the capabilities of large language models (LLMs) for logical form generation to improve performance. However, although it is validated that LLMs are capable of solving some KBQA problems, there has been little discussion on the differences in LLMs' proficiency in formal languages used in semantic parsing. In this work, we propose to evaluate the understanding and generation ability of LLMs to deal with differently structured logical forms by examining the inter-conversion of natural and formal language through in-context learning of LLMs. Extensive experiments with models of different sizes show that state-of-the-art LLMs can understand formal languages as well as humans, but generating correct logical forms given a few examples remains a challenge. Most importantly, our results also indicate that LLMs exhibit considerable sensitivity. In general, the formal language with a lower formalization level, i.e., the more similar it is to natural language, is more friendly to LLMs.
6/17/2024