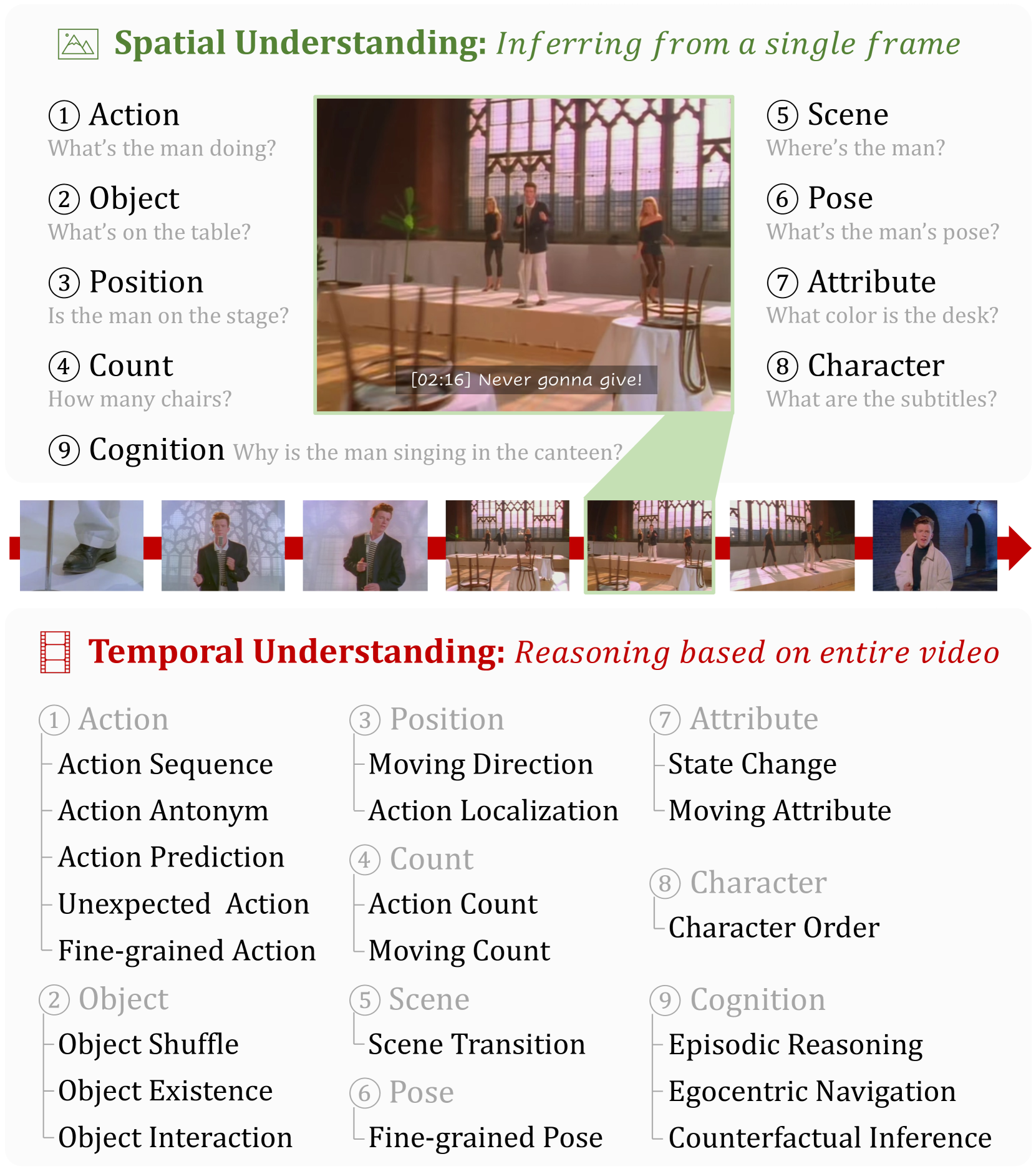
TempCompass: Do Video LLMs Really Understand Videos?
2403.00476
0
0

Abstract
Recently, there is a surge in interest surrounding video large language models (Video LLMs). However, existing benchmarks fail to provide a comprehensive feedback on the temporal perception ability of Video LLMs. On the one hand, most of them are unable to distinguish between different temporal aspects (e.g., speed, direction) and thus cannot reflect the nuanced performance on these specific aspects. On the other hand, they are limited in the diversity of task formats (e.g., only multi-choice QA), which hinders the understanding of how temporal perception performance may vary across different types of tasks. Motivated by these two problems, we propose the textbf{TempCompass} benchmark, which introduces a diversity of temporal aspects and task formats. To collect high-quality test data, we devise two novel strategies: (1) In video collection, we construct conflicting videos that share the same static content but differ in a specific temporal aspect, which prevents Video LLMs from leveraging single-frame bias or language priors. (2) To collect the task instructions, we propose a paradigm where humans first annotate meta-information for a video and then an LLM generates the instruction. We also design an LLM-based approach to automatically and accurately evaluate the responses from Video LLMs. Based on TempCompass, we comprehensively evaluate 8 state-of-the-art (SOTA) Video LLMs and 3 Image LLMs, and reveal the discerning fact that these models exhibit notably poor temporal perception ability. Our data will be available at https://github.com/llyx97/TempCompass.
Create account to get full access
Overview
- This paper explores whether current video large language models (VLLMs) truly understand the video content they process, or if they are simply pattern matching without deeper comprehension.
- The researchers propose a new benchmark called TempCompass to assess VLLMs' ability to generalize their understanding across time.
- The paper compares the performance of several state-of-the-art VLLMs on this new benchmark and provides insights into the strengths and limitations of current video understanding capabilities.
Plain English Explanation
The paper investigates whether video language models, which are AI systems trained on large amounts of video data, can truly understand the content they are processing or if they are just matching patterns without deeper comprehension.
The researchers created a new test called TempCompass to assess how well these video models can generalize their understanding over time. They compared the performance of several leading video language models on this new benchmark to gain insights into the current capabilities and limitations of video understanding AI.
The key idea is to see if these models can take what they've learned from one part of a video and apply it to understand what's happening in a different part of the same video. This tests whether the models have grasped the underlying concepts or are just recognizing superficial features.
Technical Explanation
The paper proposes a new benchmark called TempCompass to evaluate the temporal reasoning capabilities of video large language models (VLLMs). The benchmark assesses how well these models can generalize their understanding across different time segments within the same video.
The researchers collected a diverse dataset of videos spanning multiple domains and annotated them with dense temporal grounding of semantically relevant events. They then designed a series of tasks that challenge the VLLMs to make predictions about future or past events based on their understanding of the current video context.
The paper evaluates the performance of several state-of-the-art VLLMs, including MoMentor, ViDCOM, and VTG-LLM, on the TempCompass benchmark. The results provide insights into the temporal reasoning capabilities of these models and identify areas for improvement in video understanding.
Critical Analysis
The paper raises important questions about the true depth of understanding achieved by current video language models. While these models have demonstrated impressive performance on various video understanding tasks, the TempCompass benchmark reveals limitations in their ability to generalize their knowledge across time within the same video.
One potential limitation of the study is the reliance on a single benchmark dataset. The diversity of the dataset is highlighted, but additional evaluation on a broader range of video types and tasks could provide a more comprehensive assessment of the models' capabilities.
Furthermore, the paper does not delve into the specific architectural choices or training approaches used by the evaluated models. A deeper examination of these factors could shed light on the underlying reasons for the observed performance differences and guide future improvements in video understanding.
It would also be valuable to explore how the temporal reasoning capabilities of VLLMs compare to those of human observers. Comparison to human benchmarks could help establish more meaningful performance targets and identify areas where AI systems still fall short in their video comprehension abilities.
Conclusion
This paper presents a novel benchmark, TempCompass, to assess the temporal reasoning capabilities of video large language models. The results suggest that while these models have made significant progress in video understanding, they still struggle to fully generalize their knowledge across different time segments within the same video.
The insights from this research could inform the development of more robust and contextually aware video understanding systems. By addressing the limitations identified in this study, future video language models may be able to achieve a deeper, more human-like comprehension of video content, with applications in areas such as video summarization, question answering, and video-based reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, Yu Qiao
0
0
With the rapid development of Multi-modal Large Language Models (MLLMs), a number of diagnostic benchmarks have recently emerged to evaluate the comprehension capabilities of these models. However, most benchmarks predominantly assess spatial understanding in the static image tasks, while overlooking temporal understanding in the dynamic video tasks. To alleviate this issue, we introduce a comprehensive Multi-modal Video understanding Benchmark, namely MVBench, which covers 20 challenging video tasks that cannot be effectively solved with a single frame. Specifically, we first introduce a novel static-to-dynamic method to define these temporal-related tasks. By transforming various static tasks into dynamic ones, we enable the systematic generation of video tasks that require a broad spectrum of temporal skills, ranging from perception to cognition. Then, guided by the task definition, we automatically convert public video annotations into multiple-choice QA to evaluate each task. On one hand, such a distinct paradigm allows us to build MVBench efficiently, without much manual intervention. On the other hand, it guarantees evaluation fairness with ground-truth video annotations, avoiding the biased scoring of LLMs. Moreover, we further develop a robust video MLLM baseline, i.e., VideoChat2, by progressive multi-modal training with diverse instruction-tuning data. The extensive results on our MVBench reveal that, the existing MLLMs are far from satisfactory in temporal understanding, while our VideoChat2 largely surpasses these leading models by over 15% on MVBench. All models and data are available at https://github.com/OpenGVLab/Ask-Anything.
5/24/2024
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, Bryan Perozzi
0
0
Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
6/14/2024

Momentor: Advancing Video Large Language Model with Fine-Grained Temporal Reasoning
Long Qian, Juncheng Li, Yu Wu, Yaobo Ye, Hao Fei, Tat-Seng Chua, Yueting Zhuang, Siliang Tang
0
0
Large Language Models (LLMs) demonstrate remarkable proficiency in comprehending and handling text-based tasks. Many efforts are being made to transfer these attributes to video modality, which are termed Video-LLMs. However, existing Video-LLMs can only capture the coarse-grained semantics and are unable to effectively handle tasks related to comprehension or localization of specific video segments. In light of these challenges, we propose Momentor, a Video-LLM capable of accomplishing fine-grained temporal understanding tasks. To support the training of Momentor, we design an automatic data generation engine to construct Moment-10M, a large-scale video instruction dataset with segment-level instruction data. We train Momentor on Moment-10M, enabling it to perform segment-level reasoning and localization. Zero-shot evaluations on several tasks demonstrate that Momentor excels in fine-grained temporally grounded comprehension and localization.
6/4/2024
⛏️
Evaluating LLMs at Evaluating Temporal Generalization
Chenghao Zhu, Nuo Chen, Yufei Gao, Benyou Wang
0
0
The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
5/15/2024