Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
2406.09170
0
0
Abstract
Large language models (LLMs) have showcased remarkable reasoning capabilities, yet they remain susceptible to errors, particularly in temporal reasoning tasks involving complex temporal logic. Existing research has explored LLM performance on temporal reasoning using diverse datasets and benchmarks. However, these studies often rely on real-world data that LLMs may have encountered during pre-training or employ anonymization techniques that can inadvertently introduce factual inconsistencies. In this work, we address these limitations by introducing novel synthetic datasets specifically designed to assess LLM temporal reasoning abilities in various scenarios. The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance. Our findings provide valuable insights into the strengths and weaknesses of current LLMs in temporal reasoning tasks. To foster further research in this area, we are open-sourcing the datasets and evaluation framework used in our experiments: https://huggingface.co/datasets/baharef/ToT.
Create account to get full access
Overview
- This paper introduces a new benchmark called "Test of Time" for evaluating the temporal reasoning abilities of large language models (LLMs).
- The benchmark assesses how well LLMs can understand and reason about temporal information, such as dates, times, and sequences of events.
- The authors create a diverse dataset of questions that test different aspects of temporal reasoning, and evaluate several state-of-the-art LLMs on this benchmark.
Plain English Explanation
The paper presents a new way to test how well large language models (LLMs) - powerful AI systems that can understand and generate human-like text - can reason about time and events. The researchers created a "Test of Time" benchmark, which consists of a variety of questions that require understanding dates, timelines, and the order of things happening. By evaluating top LLMs on this benchmark, the authors can see how capable these models are at grasping temporal information and reasoning about it. This is an important skill for AI systems to have, as being able to understand time and the sequence of events is crucial for many real-world applications, like question answering, summarization, and dialogue. The findings from this benchmark can help guide the development of even more capable and temporally-aware language models in the future.
Technical Explanation
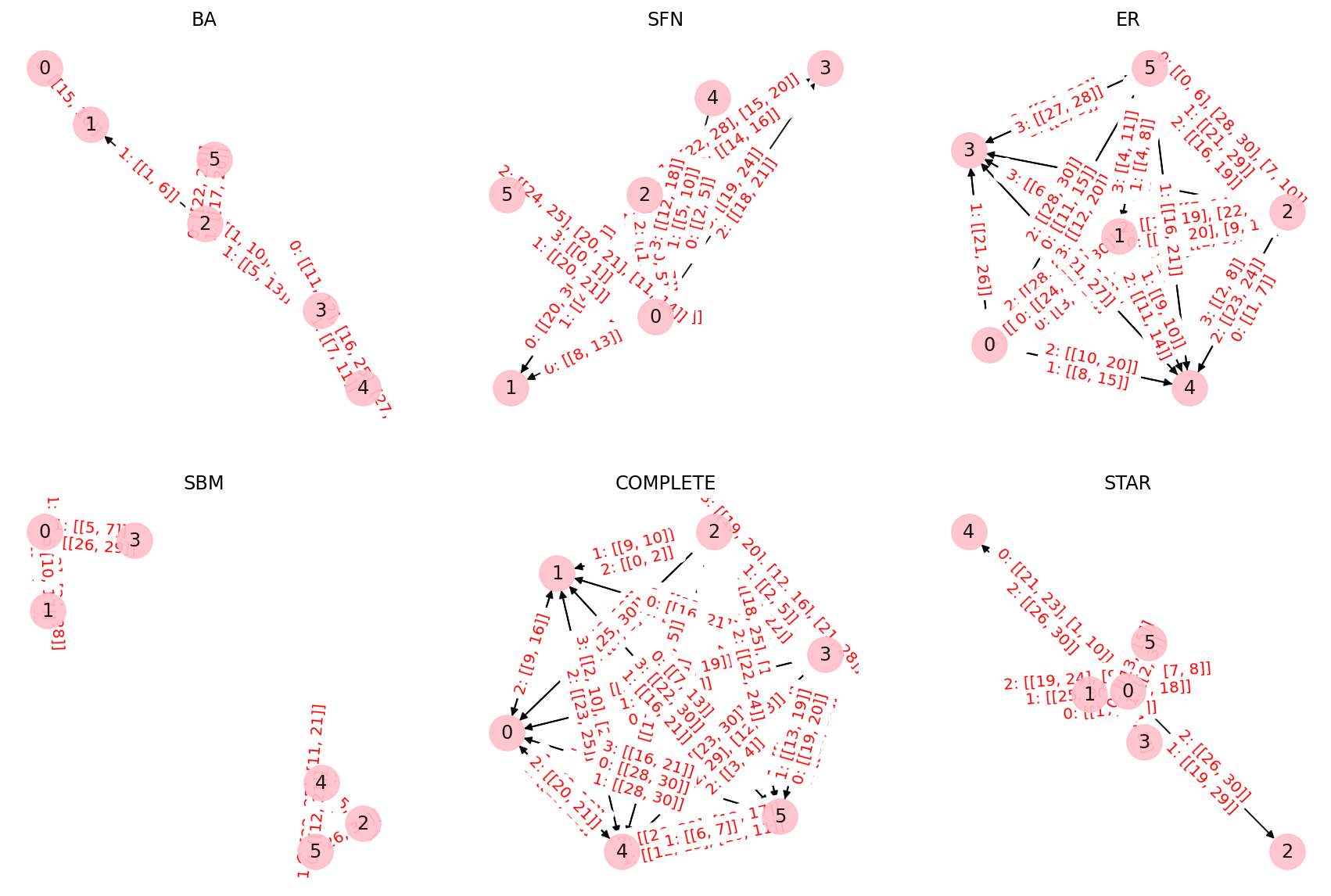
The paper introduces a new benchmark called "Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning" to assess the temporal reasoning abilities of large language models (LLMs). The benchmark consists of a diverse dataset of questions that test different aspects of temporal reasoning, such as understanding dates, timelines, and the sequence of events.
The authors evaluate several state-of-the-art LLMs, including GPT-3, BERT, and RoBERTa, on this benchmark. They find that while these models perform reasonably well on some temporal reasoning tasks, they still struggle with more complex temporal reasoning, especially when it comes to understanding the relative timing of events and temporal relations between entities.
The paper also introduces a new LLM architecture called "TRAM" that is specifically designed to improve temporal reasoning abilities. TRAM outperforms the other LLMs on the Test of Time benchmark, demonstrating the potential for more temporally-aware language models.
Additionally, the paper explores "temporal generalization" - the ability of LLMs to apply their temporal reasoning skills to new, unseen situations. The findings suggest that while LLMs can learn temporal reasoning to some extent, they struggle to generalize this knowledge to novel contexts.
Critical Analysis
The authors acknowledge several limitations of their research. First, the Test of Time benchmark, while comprehensive, may not capture all aspects of temporal reasoning that are relevant in real-world applications. There may be additional temporal reasoning skills that are not tested by the current benchmark.
Additionally, the paper focuses on evaluating the temporal reasoning abilities of LLMs, but does not delve into the underlying mechanisms and representations that enable (or hinder) this capability. Further research is needed to understand the cognitive processes and architectural choices that lead to more effective temporal reasoning in LLMs.
The authors also highlight the need for more work on "temporal generalization," as the current LLMs struggle to apply their temporal reasoning skills to novel contexts. Improving the ability of LLMs to generalize their temporal knowledge is an important area for future research.
Finally, the paper only evaluates a limited set of LLM architectures. There may be other model designs or training approaches that could further improve temporal reasoning capabilities, as demonstrated by the authors' own "TRAM" model.
Conclusion
This paper introduces a new benchmark, "Test of Time," for evaluating the temporal reasoning abilities of large language models (LLMs). The findings suggest that while current state-of-the-art LLMs can perform some temporal reasoning tasks, they still struggle with more complex temporal understanding and the ability to generalize their temporal knowledge to new situations.
The paper's contribution lies in its provision of a comprehensive benchmark for assessing temporal reasoning in LLMs, as well as the insights it offers on the current limitations of these models in this domain. These findings can inform the development of more temporally-aware and generalizable language models, which will be crucial for a wide range of real-world applications that require robust temporal reasoning capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
TRAM: Benchmarking Temporal Reasoning for Large Language Models
Yuqing Wang, Yun Zhao
0
0
Reasoning about time is essential for understanding the nuances of events described in natural language. Previous research on this topic has been limited in scope, characterized by a lack of standardized benchmarks that would allow for consistent evaluations across different studies. In this paper, we introduce TRAM, a temporal reasoning benchmark composed of ten datasets, encompassing various temporal aspects of events such as order, arithmetic, frequency, and duration, designed to facilitate a comprehensive evaluation of the TeR capabilities of large language models (LLMs). We evaluate popular LLMs like GPT-4 and Llama2 in zero-shot and few-shot scenarios, and establish baselines with BERT-based and domain-specific models. Our findings indicate that the best-performing model lags significantly behind human performance. It is our aspiration that TRAM will spur further progress in enhancing the TeR capabilities of LLMs.
6/3/2024
⛏️
Evaluating LLMs at Evaluating Temporal Generalization
Chenghao Zhu, Nuo Chen, Yufei Gao, Benyou Wang
0
0
The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
5/15/2024
Large Language Models Can Learn Temporal Reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, Faramarz Fekri
0
0
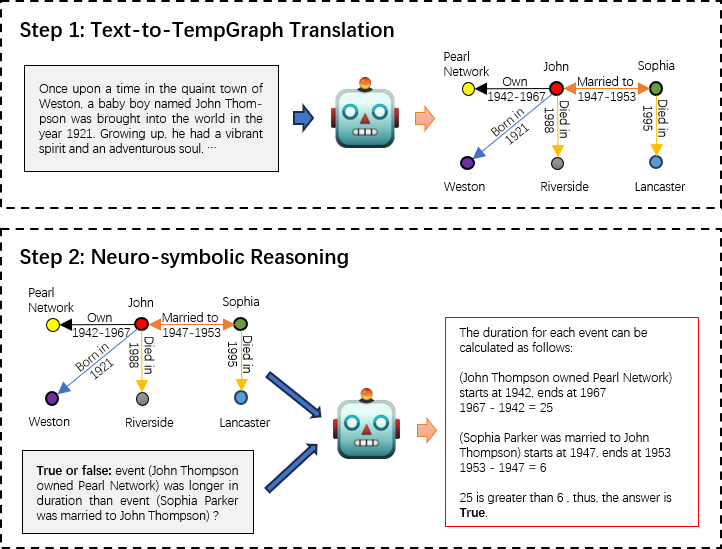
While large language models (LLMs) have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal concepts and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that enhances the learning of TR. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain-of-Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
6/12/2024
New!STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Wenbin Li, Di Yao, Ruibo Zhao, Wenjie Chen, Zijie Xu, Chengxue Luo, Chang Gong, Quanliang Jing, Haining Tan, Jingping Bi
0
0
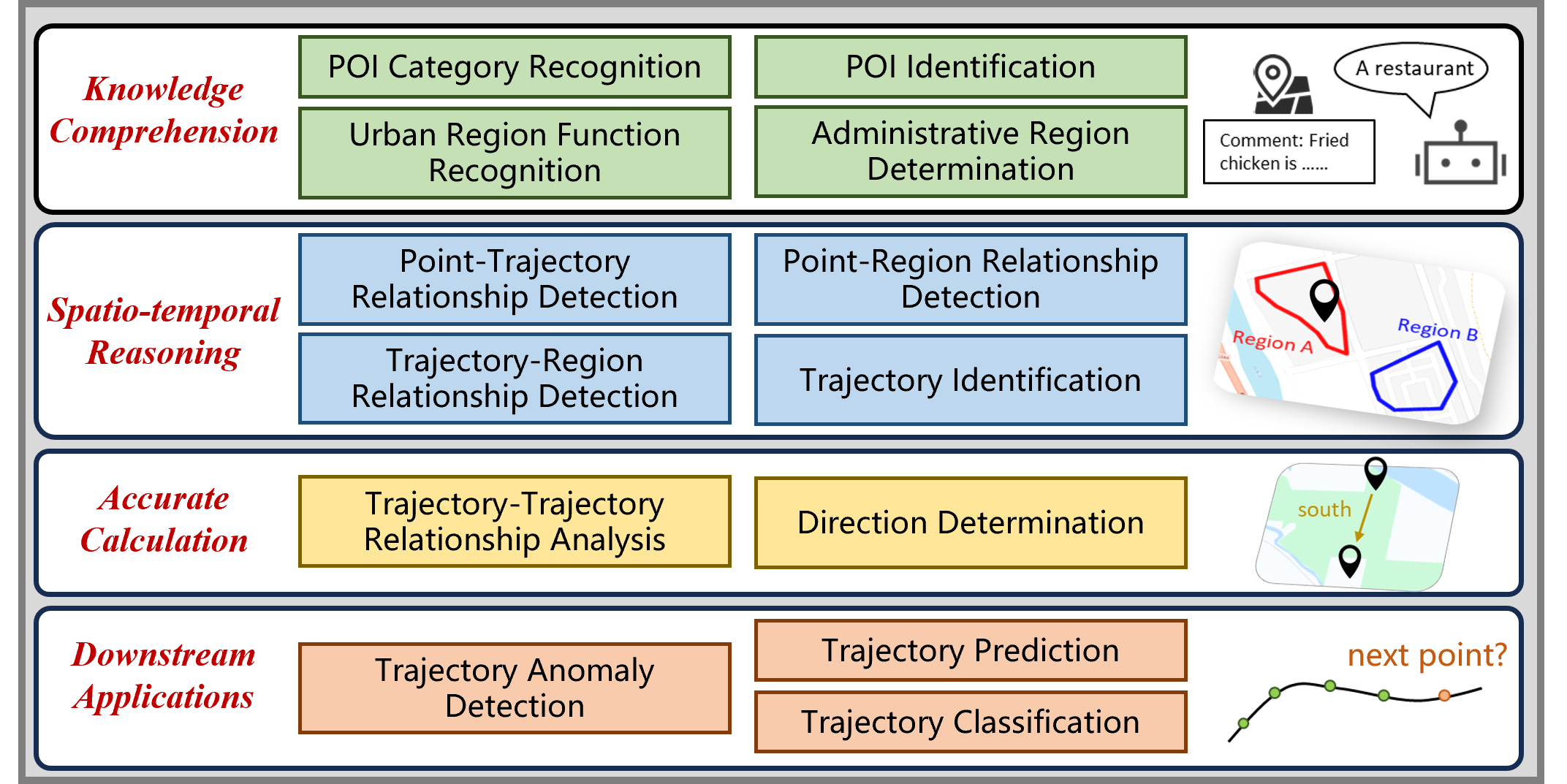
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
6/28/2024