Tensor Train Low-rank Approximation (TT-LoRA): Democratizing AI with Accelerated LLMs

0

Sign in to get full access
Overview
- Tensor Train Low-rank Approximation (TT-LoRA) is a novel technique for compressing and accelerating large language models (LLMs).
- It enables efficient training and deployment of LLMs on resource-constrained devices by reducing their parameter count.
- The approach involves approximating the weight matrices of the LLM using a tensor train (TT) decomposition, which can significantly reduce the model size.
Plain English Explanation
Tensor Train Low-rank Approximation (TT-LoRA) is a new method that makes it easier to use and deploy large language models (LLMs) like BERT. LLMs are powerful AI models that can understand and generate human-like text, but they typically have billions of parameters, making them very large and resource-intensive to run.
TT-LoRA solves this problem by compressing the LLM's internal weight matrices using a technique called tensor train (TT) decomposition. This allows the model to be much smaller and faster, while still maintaining most of its original capabilities. The key idea is to represent each large weight matrix as a series of smaller, interconnected "tensor" matrices, which can be stored and processed more efficiently.
By using TT-LoRA, the researchers were able to reduce the size of a BERT-based LLM by up to 90% without significantly impacting its performance. This makes it much easier to deploy these powerful models on a wider range of devices, from powerful servers to resource-constrained mobile phones and edge devices. This "democratization" of AI can enable more people and organizations to benefit from the capabilities of LLMs.
Technical Explanation
Tensor Train Low-rank Approximation (TT-LoRA) is a novel compression technique that leverages the tensor train (TT) decomposition to reduce the parameter count of large language models (LLMs) like BERT.
The key idea behind TT-LoRA is to approximate the weight matrices in the LLM using a tensor train representation, which can significantly reduce the number of parameters required to represent the model. The TT decomposition represents each large weight matrix as a sequence of smaller, interconnected "tensor" matrices, which can be stored and processed more efficiently.
The researchers demonstrated the effectiveness of TT-LoRA by applying it to a BERT-based LLM. They were able to achieve up to 90% reduction in the model size without significantly impacting the model's performance on various natural language processing tasks. This compression allows for more efficient training and deployment of LLMs, especially on resource-constrained devices.
The authors also introduced an optimization algorithm to further fine-tune the TT-LoRA parameters, which helped maintain the model's performance during compression. Additionally, they explored the use of TT-LoRA for task-specific fine-tuning, showing that it can be effectively used to adapt the LLM to specific downstream tasks.
Critical Analysis
The Tensor Train Low-rank Approximation (TT-LoRA) approach presents a promising solution for reducing the resource requirements of large language models (LLMs) while maintaining their performance. The compression technique based on tensor train decomposition is well-suited for LLMs, which typically have high-dimensional weight matrices.
One potential limitation of the TT-LoRA approach is that the compression ratio and performance trade-off may vary depending on the specific LLM architecture and task. The authors acknowledge that the optimal TT-LoRA configuration may need to be tuned for different models and applications. Additionally, the computational overhead of the TT-LoRA optimization process could be a concern, especially for resource-constrained devices.
While the paper demonstrates the effectiveness of TT-LoRA on a BERT-based LLM, it would be interesting to see how the technique performs on other state-of-the-art LLMs, such as GPT-3 or Megatron-LM. Exploring the limits of the compression ratio and its impact on downstream task performance would also provide valuable insights.
Conclusion
The Tensor Train Low-rank Approximation (TT-LoRA) technique presented in this paper is a significant contribution to the field of large language model compression and acceleration. By leveraging the tensor train decomposition, the researchers have demonstrated a effective way to reduce the parameter count of LLMs without sacrificing their performance.
This advancement has the potential to "democratize" AI by making powerful LLMs more accessible and deployable on a wider range of devices, from powerful servers to resource-constrained edge devices. As the field of AI continues to evolve, techniques like TT-LoRA will play a crucial role in enabling the widespread adoption and practical application of large language models in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tensor Train Low-rank Approximation (TT-LoRA): Democratizing AI with Accelerated LLMs
Afia Anjum, Maksim E. Eren, Ismael Boureima, Boian Alexandrov, Manish Bhattarai
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing (NLP) tasks, such as question-answering, sentiment analysis, text summarization, and machine translation. However, the ever-growing complexity of LLMs demands immense computational resources, hindering the broader research and application of these models. To address this, various parameter-efficient fine-tuning strategies, such as Low-Rank Approximation (LoRA) and Adapters, have been developed. Despite their potential, these methods often face limitations in compressibility. Specifically, LoRA struggles to scale effectively with the increasing number of trainable parameters in modern large scale LLMs. Additionally, Low-Rank Economic Tensor-Train Adaptation (LoRETTA), which utilizes tensor train decomposition, has not yet achieved the level of compression necessary for fine-tuning very large scale models with limited resources. This paper introduces Tensor Train Low-Rank Approximation (TT-LoRA), a novel parameter-efficient fine-tuning (PEFT) approach that extends LoRETTA with optimized tensor train (TT) decomposition integration. By eliminating Adapters and traditional LoRA-based structures, TT-LoRA achieves greater model compression without compromising downstream task performance, along with reduced inference latency and computational overhead. We conduct an exhaustive parameter search to establish benchmarks that highlight the trade-off between model compression and performance. Our results demonstrate significant compression of LLMs while maintaining comparable performance to larger models, facilitating their deployment on resource-constraint platforms.
Read more8/6/2024
🌿
2
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
Read more5/3/2024
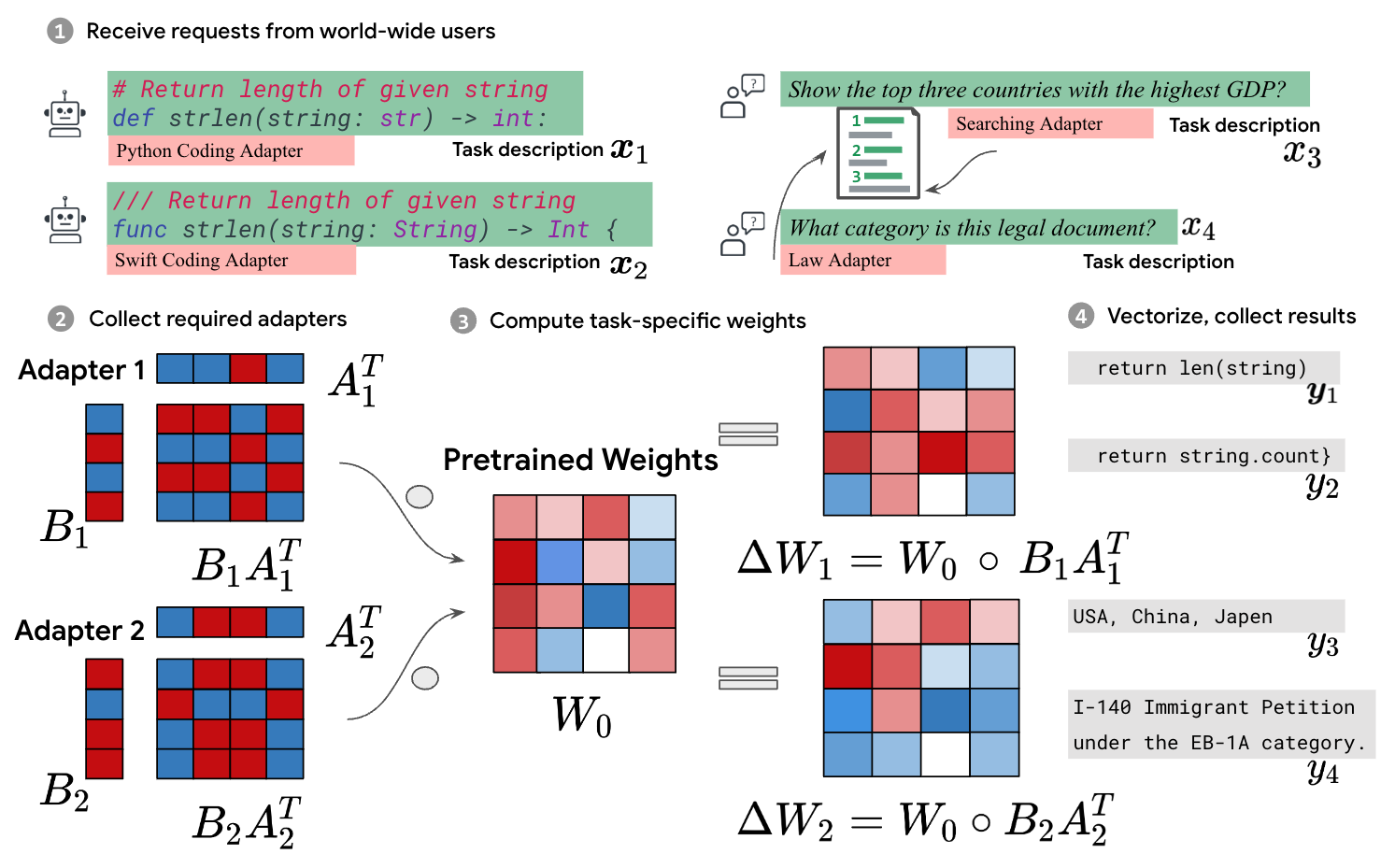
0
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024

0
Training Neural Networks from Scratch with Parallel Low-Rank Adapters
Minyoung Huh, Brian Cheung, Jeremy Bernstein, Phillip Isola, Pulkit Agrawal
The scalability of deep learning models is fundamentally limited by computing resources, memory, and communication. Although methods like low-rank adaptation (LoRA) have reduced the cost of model finetuning, its application in model pre-training remains largely unexplored. This paper explores extending LoRA to model pre-training, identifying the inherent constraints and limitations of standard LoRA in this context. We introduce LoRA-the-Explorer (LTE), a novel bi-level optimization algorithm designed to enable parallel training of multiple low-rank heads across computing nodes, thereby reducing the need for frequent synchronization. Our approach includes extensive experimentation on vision transformers using various vision datasets, demonstrating that LTE is competitive with standard pre-training.
Read more7/30/2024