Training Neural Networks from Scratch with Parallel Low-Rank Adapters

0

Sign in to get full access
Overview
- Trains neural networks from scratch with parallel low-rank adapters
- Proposes a novel training approach that enables efficient learning of large neural networks
- Demonstrates strong performance on a range of tasks, including image classification and natural language processing
Plain English Explanation
The paper introduces a new method for training neural networks from scratch using an approach called "parallel low-rank adapters." This approach allows large neural networks to be trained efficiently, by learning a set of small, specialized "adapter" modules that can be plugged into the main network.
The key idea is that instead of training the entire network end-to-end, the method trains these adapter modules in parallel, which can significantly speed up the training process. The adapters are designed to be low-rank, meaning they have a compact representation that takes up less memory and computational resources.
This parallel low-rank adapter approach has several advantages. It enables efficient learning of large neural networks, which can be challenging to train from scratch. It also allows for serving thousands of concurrent adapters, making the approach scalable and practical for real-world applications.
The paper demonstrates the effectiveness of this method on a variety of tasks, including image classification and natural language processing. The results show that the parallel low-rank adapter approach can match or outperform traditional end-to-end training, while being more efficient and scalable.
Technical Explanation
The paper proposes a novel training approach called "Parallel Low-Rank Adapters" (PLRA) that enables efficient learning of large neural networks from scratch. The key idea is to train a set of small, specialized "adapter" modules in parallel, which can then be plugged into the main network.
The adapters are designed to be low-rank, meaning they have a compact representation that takes up less memory and computational resources. This allows the network to be trained more efficiently, as the adapters can be learned independently and in parallel.
The paper provides a detailed explanation of the PLRA architecture and training procedure. The main network is first initialized with a set of pre-trained weights, and then the adapter modules are trained in parallel, with each adapter learning a specific transformation that can be applied to the network.
The authors conduct extensive experiments to evaluate the PLRA approach on a range of tasks, including image classification and natural language processing. The results demonstrate that PLRA can match or outperform traditional end-to-end training, while being more efficient and scalable.
Critical Analysis
The paper presents a promising approach for training large neural networks from scratch, but there are a few potential limitations and areas for further research:
- The computational limits of low-rank adaptation are not fully explored, and it's unclear how the PLRA approach would scale to truly massive models.
- The paper only examines the use of PLRA for specific tasks, and it's not clear how well the approach would generalize to a wider range of applications.
- The progressive adaptation of the adapters is not explored, which could potentially further improve the efficiency and effectiveness of the training process.
Overall, the PLRA approach is a compelling contribution to the field of efficient neural network training, but additional research is needed to fully understand its strengths, limitations, and broader applicability.
Conclusion
The paper introduces a novel training approach called "Parallel Low-Rank Adapters" (PLRA) that enables efficient learning of large neural networks from scratch. The key innovation is the use of small, specialized adapter modules that can be trained in parallel, leveraging their low-rank structure to reduce memory and computational requirements.
The results demonstrate that PLRA can match or outperform traditional end-to-end training on a range of tasks, while being more efficient and scalable. This approach has the potential to significantly advance the state of the art in neural network training, particularly for large-scale models and real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training Neural Networks from Scratch with Parallel Low-Rank Adapters
Minyoung Huh, Brian Cheung, Jeremy Bernstein, Phillip Isola, Pulkit Agrawal
The scalability of deep learning models is fundamentally limited by computing resources, memory, and communication. Although methods like low-rank adaptation (LoRA) have reduced the cost of model finetuning, its application in model pre-training remains largely unexplored. This paper explores extending LoRA to model pre-training, identifying the inherent constraints and limitations of standard LoRA in this context. We introduce LoRA-the-Explorer (LTE), a novel bi-level optimization algorithm designed to enable parallel training of multiple low-rank heads across computing nodes, thereby reducing the need for frequent synchronization. Our approach includes extensive experimentation on vision transformers using various vision datasets, demonstrating that LTE is competitive with standard pre-training.
Read more7/30/2024
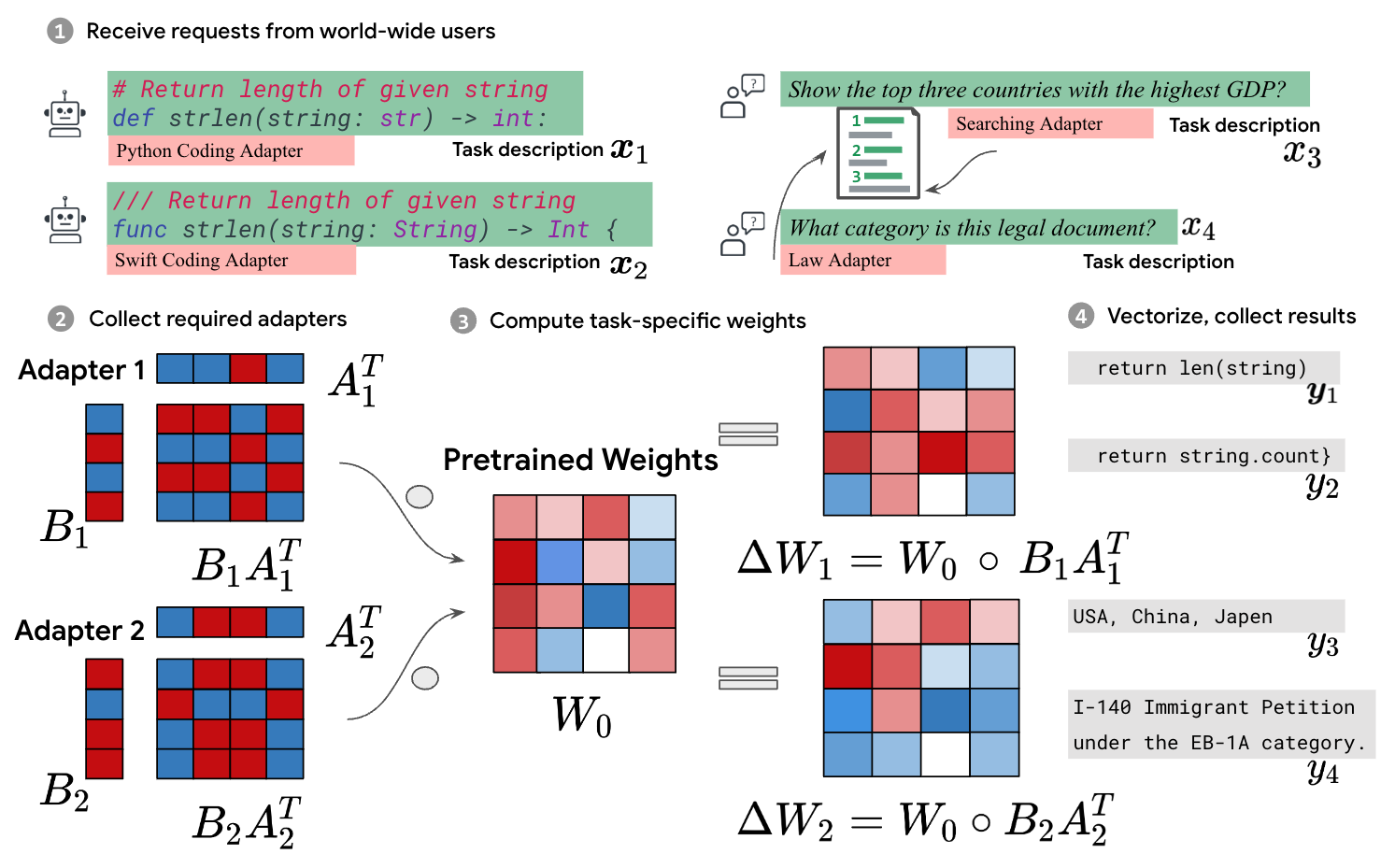
0
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
Read more4/29/2024
📶
130
LoRA+: Efficient Low Rank Adaptation of Large Models
Soufiane Hayou, Nikhil Ghosh, Bin Yu
In this paper, we show that Low Rank Adaptation (LoRA) as originally introduced in Hu et al. (2021) leads to suboptimal finetuning of models with large width (embedding dimension). This is due to the fact that adapter matrices A and B in LoRA are updated with the same learning rate. Using scaling arguments for large width networks, we demonstrate that using the same learning rate for A and B does not allow efficient feature learning. We then show that this suboptimality of LoRA can be corrected simply by setting different learning rates for the LoRA adapter matrices A and B with a well-chosen ratio. We call this proposed algorithm LoRA$+$. In our extensive experiments, LoRA$+$ improves performance (1-2 $%$ improvements) and finetuning speed (up to $sim$ 2X SpeedUp), at the same computational cost as LoRA.
Read more7/8/2024
📶
29
S-LoRA: Serving Thousands of Concurrent LoRA Adapters
Ying Sheng, Shiyi Cao, Dacheng Li, Coleman Hooper, Nicholas Lee, Shuo Yang, Christopher Chou, Banghua Zhu, Lianmin Zheng, Kurt Keutzer, Joseph E. Gonzalez, Ion Stoica
The pretrain-then-finetune paradigm is commonly adopted in the deployment of large language models. Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning method, is often employed to adapt a base model to a multitude of tasks, resulting in a substantial collection of LoRA adapters derived from one base model. We observe that this paradigm presents significant opportunities for batched inference during serving. To capitalize on these opportunities, we present S-LoRA, a system designed for the scalable serving of many LoRA adapters. S-LoRA stores all adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory. To efficiently use the GPU memory and reduce fragmentation, S-LoRA proposes Unified Paging. Unified Paging uses a unified memory pool to manage dynamic adapter weights with different ranks and KV cache tensors with varying sequence lengths. Additionally, S-LoRA employs a novel tensor parallelism strategy and highly optimized custom CUDA kernels for heterogeneous batching of LoRA computation. Collectively, these features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with a small overhead. Compared to state-of-the-art libraries such as HuggingFace PEFT and vLLM (with naive support of LoRA serving), S-LoRA can improve the throughput by up to 4 times and increase the number of served adapters by several orders of magnitude. As a result, S-LoRA enables scalable serving of many task-specific fine-tuned models and offers the potential for large-scale customized fine-tuning services. The code is available at https://github.com/S-LoRA/S-LoRA
Read more6/6/2024