TexIm FAST: Text-to-Image Representation for Semantic Similarity Evaluation using Transformers

0

Sign in to get full access
Overview
• This paper introduces TexIm FAST, a text-to-image representation approach for evaluating semantic similarity using transformers.
• The method encodes text and images into a shared latent space, allowing for direct comparison of their semantic representations.
• TexIm FAST is designed to address limitations of existing text-image similarity measures, which can struggle to capture nuanced semantic relationships.
Plain English Explanation
TexIm FAST is a new way to compare the meaning and content of text and images. It takes text and images and turns them into a common format that can be directly compared. This allows for a more accurate assessment of how similar the meaning and concepts in the text and images really are.
Existing methods for comparing text and images can sometimes miss subtle connections between them. TexIm FAST aims to overcome this by representing both in a shared latent space - a common format that preserves the semantic relationships. This makes it easier to see how closely the meanings in the text and images align.
The key insight is that by encoding text and images into this shared representation, we can directly measure their semantic similarity. This could be useful in applications like image captioning, where we want to assess how well the text description matches the visual content of an image.
Technical Explanation
The paper presents the TexIm FAST method, which uses transformer-based models to encode text and images into a shared latent space representation. This allows for direct comparison of the semantic similarity between the text and image content.
The approach first encodes the text using a pre-trained language model like BERT. It then encodes the corresponding image using a vision transformer. These text and image encodings are mapped into a common latent space, enabling direct semantic similarity computation.
The authors evaluate TexIm FAST on standard text-image retrieval benchmarks, demonstrating improved performance over prior approaches. The shared latent space allows TexIm FAST to better capture nuanced semantic relationships between the text and visual content.
Critical Analysis
The paper provides a novel approach to text-image semantic similarity evaluation, addressing limitations of prior methods. However, the authors acknowledge that TexIm FAST relies on pre-trained models, which may introduce biases or restrict its applicability to specialized domains.
Additionally, the paper does not explore the interpretability of the learned latent space representations. Understanding how the model encodes and relates semantic concepts in text and images could provide further insights.
Lastly, the authors mention the potential for TexIm FAST to be used in applications like image captioning, but do not provide a thorough analysis of its real-world performance and implications in such scenarios.
Conclusion
TexIm FAST offers a new way to compare the semantic meaning between text and images by encoding both into a shared latent space. This can lead to more accurate assessments of how well the text describes the visual content, with potential applications in areas like image captioning.
While the paper demonstrates promising results, further research is needed to address the interpretability of the learned representations and to explore the practical implications of TexIm FAST in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TexIm FAST: Text-to-Image Representation for Semantic Similarity Evaluation using Transformers
Wazib Ansar, Saptarsi Goswami, Amlan Chakrabarti
One of the principal objectives of Natural Language Processing (NLP) is to generate meaningful representations from text. Improving the informativeness of the representations has led to a tremendous rise in the dimensionality and the memory footprint. It leads to a cascading effect amplifying the complexity of the downstream model by increasing its parameters. The available techniques cannot be applied to cross-modal applications such as text-to-image. To ameliorate these issues, a novel Text-to-Image methodology for generating fixed-length representations through a self-supervised Variational Auto-Encoder (VAE) for semantic evaluation applying transformers (TexIm FAST) has been proposed in this paper. The pictorial representations allow oblivious inference while retaining the linguistic intricacies, and are potent in cross-modal applications. TexIm FAST deals with variable-length sequences and generates fixed-length representations with over 75% reduced memory footprint. It enhances the efficiency of the models for downstream tasks by reducing its parameters. The efficacy of TexIm FAST has been extensively analyzed for the task of Semantic Textual Similarity (STS) upon the MSRPC, CNN/ Daily Mail, and XSum data-sets. The results demonstrate 6% improvement in accuracy compared to the baseline and showcase its exceptional ability to compare disparate length sequences such as a text with its summary.
Read more6/10/2024
🛸
0
An Empirical Study and Analysis of Text-to-Image Generation Using Large Language Model-Powered Textual Representation
Zhiyu Tan, Mengping Yang, Luozheng Qin, Hao Yang, Ye Qian, Qiang Zhou, Cheng Zhang, Hao Li
One critical prerequisite for faithful text-to-image generation is the accurate understanding of text inputs. Existing methods leverage the text encoder of the CLIP model to represent input prompts. However, the pre-trained CLIP model can merely encode English with a maximum token length of 77. Moreover, the model capacity of the text encoder from CLIP is relatively limited compared to Large Language Models (LLMs), which offer multilingual input, accommodate longer context, and achieve superior text representation. In this paper, we investigate LLMs as the text encoder to improve the language understanding in text-to-image generation. Unfortunately, training text-to-image generative model with LLMs from scratch demands significant computational resources and data. To this end, we introduce a three-stage training pipeline that effectively and efficiently integrates the existing text-to-image model with LLMs. Specifically, we propose a lightweight adapter that enables fast training of the text-to-image model using the textual representations from LLMs. Extensive experiments demonstrate that our model supports not only multilingual but also longer input context with superior image generation quality.
Read more7/19/2024
👨🏫
0
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
Read more5/3/2024
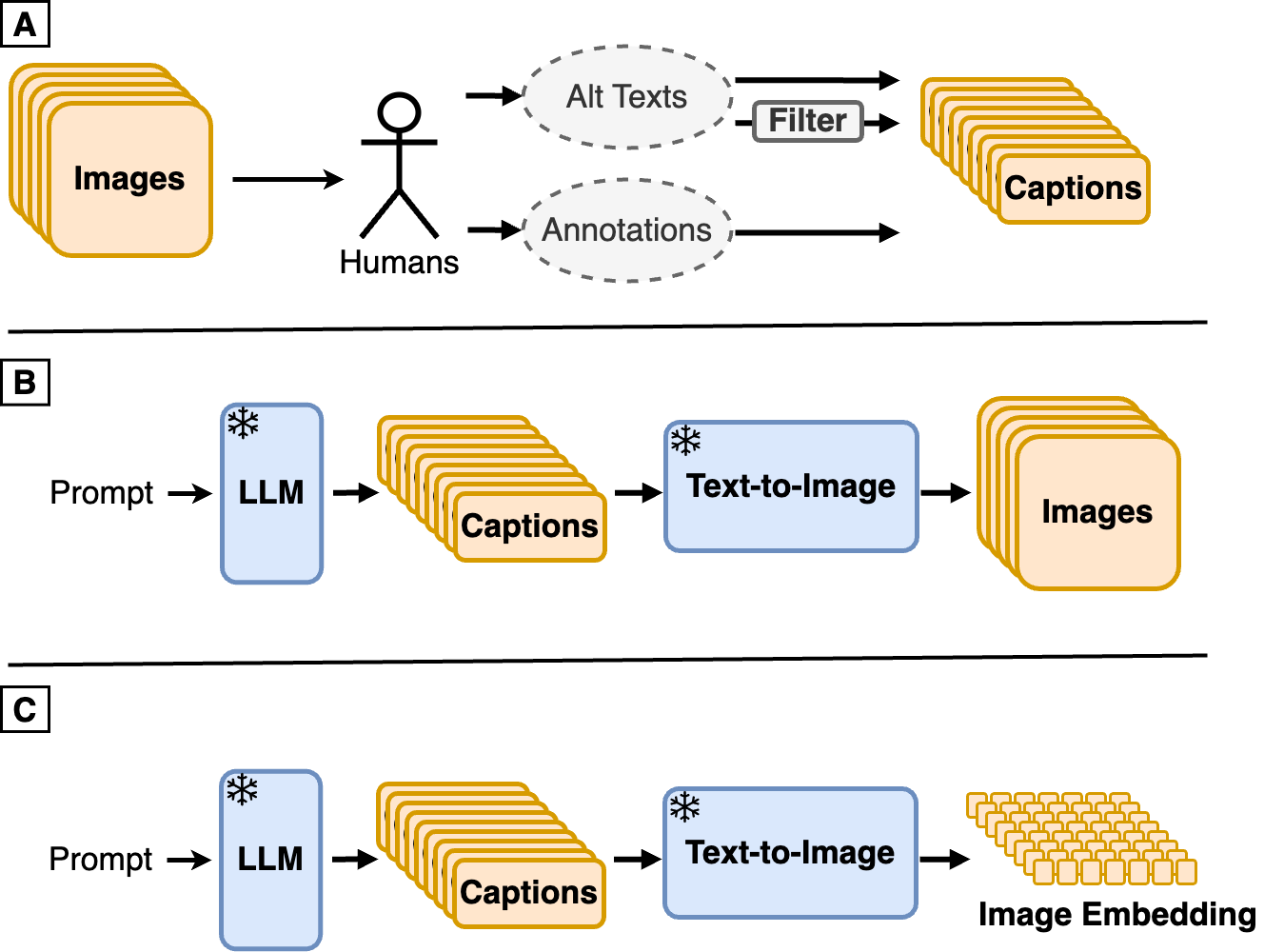
0
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
Read more6/10/2024