Text-Driven Traffic Anomaly Detection with Temporal High-Frequency Modeling in Driving Videos

0

Sign in to get full access
Overview
- Proposes a text-driven traffic anomaly detection method that leverages high-frequency temporal modeling in driving videos
- Incorporates multi-modal learning by combining video and text data to improve anomaly detection performance
- Utilizes attention mechanisms to effectively integrate the video and text information
Plain English Explanation
This research paper presents a new approach for detecting unusual or abnormal events in driving videos. The key insight is that by incorporating both the video footage and accompanying text descriptions, the system can more accurately identify traffic anomalies.
The method works by first extracting high-frequency temporal patterns from the video data. This allows the system to pick up on subtle changes and fluctuations that might signal an anomalous event, such as a car swerving or a pedestrian suddenly crossing the street.
At the same time, the text data - which might describe the driving conditions, weather, or other contextual information - is used to provide additional context. An attention mechanism is employed to intelligently weigh the relative importance of the video and text inputs, allowing the system to focus on the most relevant cues for anomaly detection.
By combining these high-frequency video patterns with the complementary text data, the researchers were able to achieve significantly better performance in identifying traffic anomalies compared to using just video or text alone. This multi-modal approach helps the system better understand the nuances of the driving environment and recognize when something out of the ordinary is occurring.
Technical Explanation
The proposed method, called "Text-Driven Traffic Anomaly Detection with Temporal High-Frequency Modeling in Driving Videos", leverages both video and text data to improve the detection of traffic anomalies.
The video processing component focuses on extracting high-frequency temporal patterns, which can capture subtle fluctuations and changes that may indicate an anomalous event. This is accomplished using a video anomaly detection model that learns to identify anomalies from the video data alone.
To incorporate the complementary text information, the system uses an attention mechanism to dynamically weigh the relative importance of the video and text inputs. This allows the model to focus on the most relevant cues for anomaly detection, drawing on both the visual and contextual data.
The researchers evaluated their approach on a dataset of driving videos with associated text descriptions. The results showed that the text-driven, high-frequency modeling technique significantly outperformed video-only and text-only baselines, demonstrating the advantages of the multi-modal approach.
Critical Analysis
The paper presents a novel and promising approach for traffic anomaly detection, leveraging both video and text data. The use of high-frequency temporal modeling to capture subtle patterns in the video is a valuable contribution, as many existing methods focus more on coarse-grained, lower-frequency features.
However, the paper does not provide much detail on the specific architectures or training techniques used for the video and text processing components. Additionally, the dataset used for evaluation is not publicly available, which makes it difficult for other researchers to build upon or validate the findings.
Another potential limitation is the focus on driving videos, which may not generalize well to other types of traffic environments, such as crowded urban scenes or complex intersections. Further research could explore the transferability of the proposed approach to a wider range of traffic scenarios.
Finally, the paper does not address the issue of model robustness - it's unclear how the system would perform under challenging conditions, such as low visibility, occlusions, or adversarial attacks. Evaluating the method's resilience to such real-world challenges would be an important next step.
Conclusion
This research presents a novel text-driven approach for traffic anomaly detection that combines high-frequency temporal modeling of video data with attention-based fusion of text information. The results demonstrate the advantages of this multi-modal technique over video-only or text-only methods, suggesting that the integration of complementary data sources can lead to significant improvements in anomaly detection performance.
While the paper has some limitations in terms of architectural details and generalizability, it represents an important step forward in the field of traffic monitoring and safety. By leveraging both visual and contextual cues, the proposed system has the potential to enable more robust and reliable detection of hazardous or unusual events, which could ultimately contribute to enhancing traffic safety and efficiency.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Text-Driven Traffic Anomaly Detection with Temporal High-Frequency Modeling in Driving Videos
Rongqin Liang, Yuanman Li, Jiantao Zhou, Xia Li
Traffic anomaly detection (TAD) in driving videos is critical for ensuring the safety of autonomous driving and advanced driver assistance systems. Previous single-stage TAD methods primarily rely on frame prediction, making them vulnerable to interference from dynamic backgrounds induced by the rapid movement of the dashboard camera. While two-stage TAD methods appear to be a natural solution to mitigate such interference by pre-extracting background-independent features (such as bounding boxes and optical flow) using perceptual algorithms, they are susceptible to the performance of first-stage perceptual algorithms and may result in error propagation. In this paper, we introduce TTHF, a novel single-stage method aligning video clips with text prompts, offering a new perspective on traffic anomaly detection. Unlike previous approaches, the supervised signal of our method is derived from languages rather than orthogonal one-hot vectors, providing a more comprehensive representation. Further, concerning visual representation, we propose to model the high frequency of driving videos in the temporal domain. This modeling captures the dynamic changes of driving scenes, enhances the perception of driving behavior, and significantly improves the detection of traffic anomalies. In addition, to better perceive various types of traffic anomalies, we carefully design an attentive anomaly focusing mechanism that visually and linguistically guides the model to adaptively focus on the visual context of interest, thereby facilitating the detection of traffic anomalies. It is shown that our proposed TTHF achieves promising performance, outperforming state-of-the-art competitors by +5.4% AUC on the DoTA dataset and achieving high generalization on the DADA dataset.
Read more4/16/2024

0
Hybrid Video Anomaly Detection for Anomalous Scenarios in Autonomous Driving
Daniel Bogdoll, Jan Imhof, Tim Joseph, J. Marius Zollner
In autonomous driving, the most challenging scenarios are the ones that can only be detected within their temporal context. Most video anomaly detection approaches focus either on surveillance or traffic accidents, which are only a subfield of autonomous driving. In this work, we present HF$^2$-VAD$_{AD}$, a variation of the HF$^2$-VAD surveillance video anomaly detection method for autonomous driving. We learn a representation of normality from a vehicle's ego perspective and evaluate pixel-wise anomaly detections in rare and critical scenarios.
Read more6/11/2024

0
Training-Free Time-Series Anomaly Detection: Leveraging Image Foundation Models
Nobuo Namura, Yuma Ichikawa
Recent advancements in time-series anomaly detection have relied on deep learning models to handle the diverse behaviors of time-series data. However, these models often suffer from unstable training and require extensive hyperparameter tuning, leading to practical limitations. Although foundation models present a potential solution, their use in time series is limited. To overcome these issues, we propose an innovative image-based, training-free time-series anomaly detection (ITF-TAD) approach. ITF-TAD converts time-series data into images using wavelet transform and compresses them into a single representation, leveraging image foundation models for anomaly detection. This approach achieves high-performance anomaly detection without unstable neural network training or hyperparameter tuning. Furthermore, ITF-TAD identifies anomalies across different frequencies, providing users with a detailed visualization of anomalies and their corresponding frequencies. Comprehensive experiments on five benchmark datasets, including univariate and multivariate time series, demonstrate that ITF-TAD offers a practical and effective solution with performance exceeding or comparable to that of deep models.
Read more8/28/2024
0
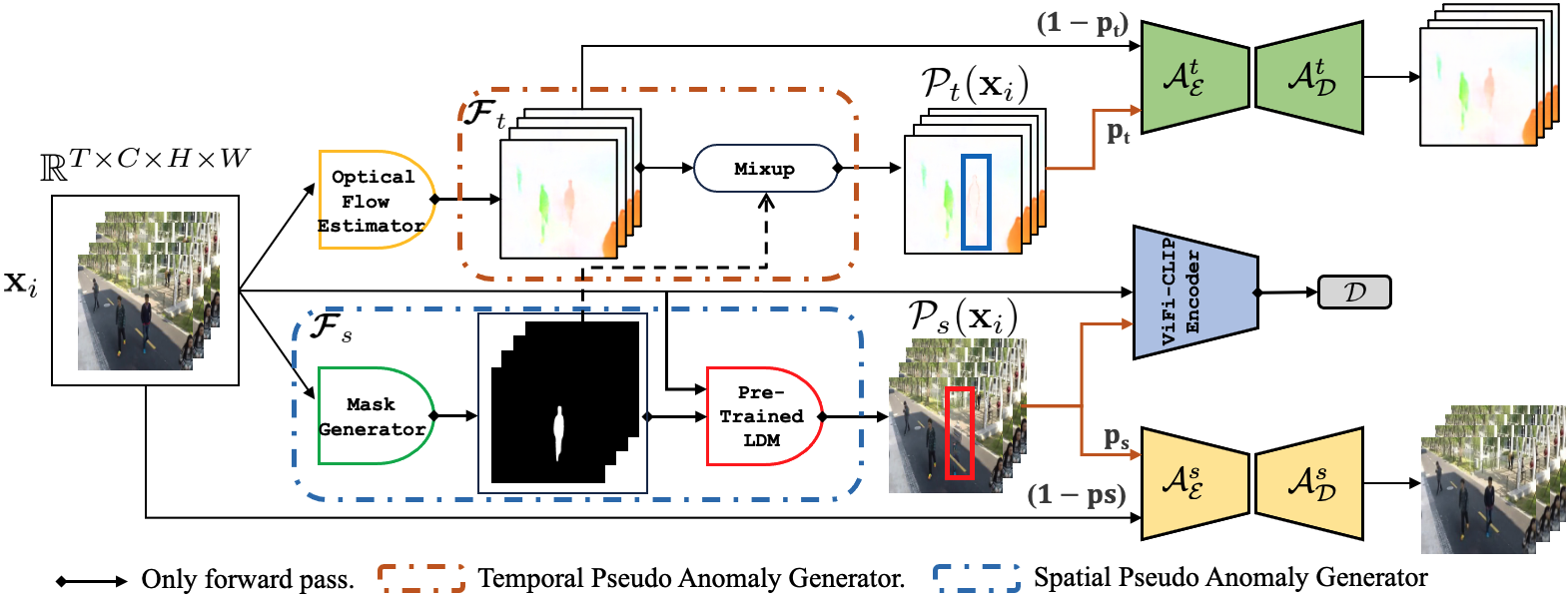
Video Anomaly Detection via Spatio-Temporal Pseudo-Anomaly Generation : A Unified Approach
Ayush K. Rai, Tarun Krishna, Feiyan Hu, Alexandru Drimbarean, Kevin McGuinness, Alan F. Smeaton, Noel E. O'Connor
Video Anomaly Detection (VAD) is an open-set recognition task, which is usually formulated as a one-class classification (OCC) problem, where training data is comprised of videos with normal instances while test data contains both normal and anomalous instances. Recent works have investigated the creation of pseudo-anomalies (PAs) using only the normal data and making strong assumptions about real-world anomalies with regards to abnormality of objects and speed of motion to inject prior information about anomalies in an autoencoder (AE) based reconstruction model during training. This work proposes a novel method for generating generic spatio-temporal PAs by inpainting a masked out region of an image using a pre-trained Latent Diffusion Model and further perturbing the optical flow using mixup to emulate spatio-temporal distortions in the data. In addition, we present a simple unified framework to detect real-world anomalies under the OCC setting by learning three types of anomaly indicators, namely reconstruction quality, temporal irregularity and semantic inconsistency. Extensive experiments on four VAD benchmark datasets namely Ped2, Avenue, ShanghaiTech and UBnormal demonstrate that our method performs on par with other existing state-of-the-art PAs generation and reconstruction based methods under the OCC setting. Our analysis also examines the transferability and generalisation of PAs across these datasets, offering valuable insights by identifying real-world anomalies through PAs.
Read more4/9/2024