Text-Guided Mixup Towards Long-Tailed Image Categorization

0

Sign in to get full access
Overview
- Addresses the challenge of long-tailed image categorization, where some classes have many examples while others have few
- Proposes a "Text-Guided Mixup" technique to augment the training data and improve model performance on the long-tailed distribution
- Leverages text descriptions of the image classes to guide the mixup process and generate more informative synthetic samples
Plain English Explanation
In machine learning, there is often a long-tailed distribution of data, where some image classes have many examples while others have very few. This can make it challenging for models to learn to accurately classify the rare or under-represented classes.
The authors of this paper introduce a new technique called "Text-Guided Mixup" to address this problem. Mixup is a data augmentation method that creates new training examples by blending pairs of existing images and their labels.
The key innovation in this work is using the text descriptions of the image classes to guide the mixup process. By considering the semantic relationships between the classes, the technique can generate more informative and realistic synthetic samples to supplement the training data.
This helps the model learn better representations of the rare classes, improving its overall performance on the long-tailed distribution. The text-guided mixup technique is a clever way to leverage additional information about the data to address the challenge of long-tailed image classification.
Technical Explanation
The authors propose a Text-Guided Mixup approach to augment the training data for long-tailed image categorization tasks. The core idea is to leverage the semantic relationships between image classes, captured in their text descriptions, to generate more informative synthetic samples using a mixup-based data augmentation method.
Specifically, the technique works as follows:
- Text Embedding: The text descriptions of the image classes are encoded into semantic embeddings using a pre-trained language model.
- Mixup Sample Generation: For each training batch, the method selects a pair of images and their corresponding text embeddings. It then computes a weighted blend of the image and text features to create a new synthetic sample.
- Consistency Regularization: To ensure the generated samples are realistic, the method enforces consistency between the predicted class probabilities for the synthetic image and the blended text embedding.
By incorporating the semantic relationships between classes, this text-guided mixup approach is able to generate more informative and diverse synthetic samples compared to standard mixup. This helps the model learn better representations of the long-tailed distribution, leading to improved classification performance.
The authors evaluate their approach on several long-tailed image classification benchmarks and demonstrate consistent improvements over baseline methods, especially for the rare and underrepresented classes.
Critical Analysis
The Text-Guided Mixup technique presented in this paper is a clever and effective way to address the challenge of long-tailed image categorization. By leveraging the semantic information in the class descriptions, the method is able to generate more meaningful synthetic samples that help the model learn better representations of the rare classes.
One potential limitation is that the approach relies on having high-quality text descriptions for the image classes. In cases where these descriptions are not available or are of poor quality, the benefits of the text-guided mixup may be diminished.
Additionally, the authors do not explore the robustness of their approach to different types of long-tailed distributions or the computational efficiency of the technique compared to other data augmentation methods. Further investigation in these areas could provide valuable insights.
Overall, the Text-Guided Mixup is a promising and innovative technique that demonstrates the value of leveraging multi-modal information to address challenges in long-tailed image classification. The research opens up interesting directions for future work in this important area of machine learning.
Conclusion
This paper presents a novel Text-Guided Mixup approach to address the challenging problem of long-tailed image categorization. By incorporating the semantic relationships between image classes, captured in their text descriptions, the technique is able to generate more informative and diverse synthetic samples to supplement the training data.
The key strength of this work is its ability to improve the model's performance on the rare and underrepresented classes, which are often the most important for real-world applications. The text-guided mixup technique is a clever and effective way to leverage multi-modal information to tackle the long-tailed distribution challenge in image classification.
As machine learning models continue to be deployed in increasingly diverse and complex real-world scenarios, techniques like Text-Guided Mixup will become increasingly important for ensuring robust and equitable performance across all classes of interest.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Text-Guided Mixup Towards Long-Tailed Image Categorization
Richard Franklin, Jiawei Yao, Deyang Zhong, Qi Qian, Juhua Hu
In many real-world applications, the frequency distribution of class labels for training data can exhibit a long-tailed distribution, which challenges traditional approaches of training deep neural networks that require heavy amounts of balanced data. Gathering and labeling data to balance out the class label distribution can be both costly and time-consuming. Many existing solutions that enable ensemble learning, re-balancing strategies, or fine-tuning applied to deep neural networks are limited by the inert problem of few class samples across a subset of classes. Recently, vision-language models like CLIP have been observed as effective solutions to zero-shot or few-shot learning by grasping a similarity between vision and language features for image and text pairs. Considering that large pre-trained vision-language models may contain valuable side textual information for minor classes, we propose to leverage text supervision to tackle the challenge of long-tailed learning. Concretely, we propose a novel text-guided mixup technique that takes advantage of the semantic relations between classes recognized by the pre-trained text encoder to help alleviate the long-tailed problem. Our empirical study on benchmark long-tailed tasks demonstrates the effectiveness of our proposal with a theoretical guarantee. Our code is available at https://github.com/rsamf/text-guided-mixup.
Read more9/6/2024

0
Efficient and Long-Tailed Generalization for Pre-trained Vision-Language Model
Jiang-Xin Shi, Chi Zhang, Tong Wei, Yu-Feng Li
Pre-trained vision-language models like CLIP have shown powerful zero-shot inference ability via image-text matching and prove to be strong few-shot learners in various downstream tasks. However, in real-world scenarios, adapting CLIP to downstream tasks may encounter the following challenges: 1) data may exhibit long-tailed data distributions and might not have abundant samples for all the classes; 2) There might be emerging tasks with new classes that contain no samples at all. To overcome them, we propose a novel framework to achieve efficient and long-tailed generalization, which can be termed as Candle. During the training process, we propose compensating logit-adjusted loss to encourage large margins of prototypes and alleviate imbalance both within the base classes and between the base and new classes. For efficient adaptation, we treat the CLIP model as a black box and leverage the extracted features to obtain visual and textual prototypes for prediction. To make full use of multi-modal information, we also propose cross-modal attention to enrich the features from both modalities. For effective generalization, we introduce virtual prototypes for new classes to make up for their lack of training images. Candle achieves state-of-the-art performance over extensive experiments on 11 diverse datasets while substantially reducing the training time, demonstrating the superiority of our approach. The source code is available at https://github.com/shijxcs/Candle.
Read more6/19/2024
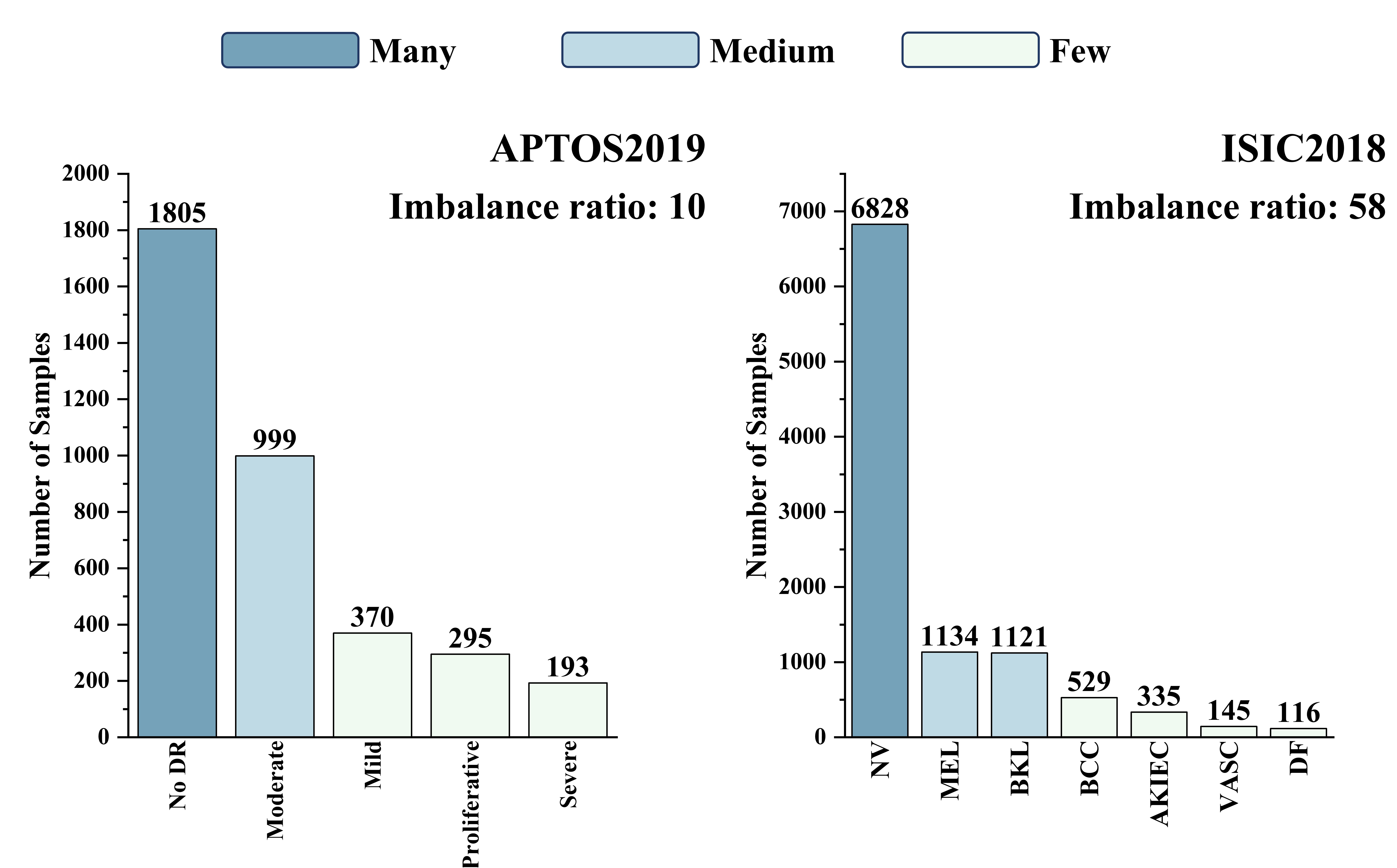
0
Text-guided Foundation Model Adaptation for Long-Tailed Medical Image Classification
Sirui Li, Li Lin, Yijin Huang, Pujin Cheng, Xiaoying Tang
In medical contexts, the imbalanced data distribution in long-tailed datasets, due to scarce labels for rare diseases, greatly impairs the diagnostic accuracy of deep learning models. Recent multimodal text-image supervised foundation models offer new solutions to data scarcity through effective representation learning. However, their limited medical-specific pretraining hinders their performance in medical image classification relative to natural images. To address this issue, we propose a novel Text-guided Foundation model Adaptation for Long-Tailed medical image classification (TFA-LT). We adopt a two-stage training strategy, integrating representations from the foundation model using just two linear adapters and a single ensembler for balanced outcomes. Experimental results on two long-tailed medical image datasets validate the simplicity, lightweight and efficiency of our approach: requiring only 6.1% GPU memory usage of the current best-performing algorithm, our method achieves an accuracy improvement of up to 27.1%, highlighting the substantial potential of foundation model adaptation in this area.
Read more8/28/2024
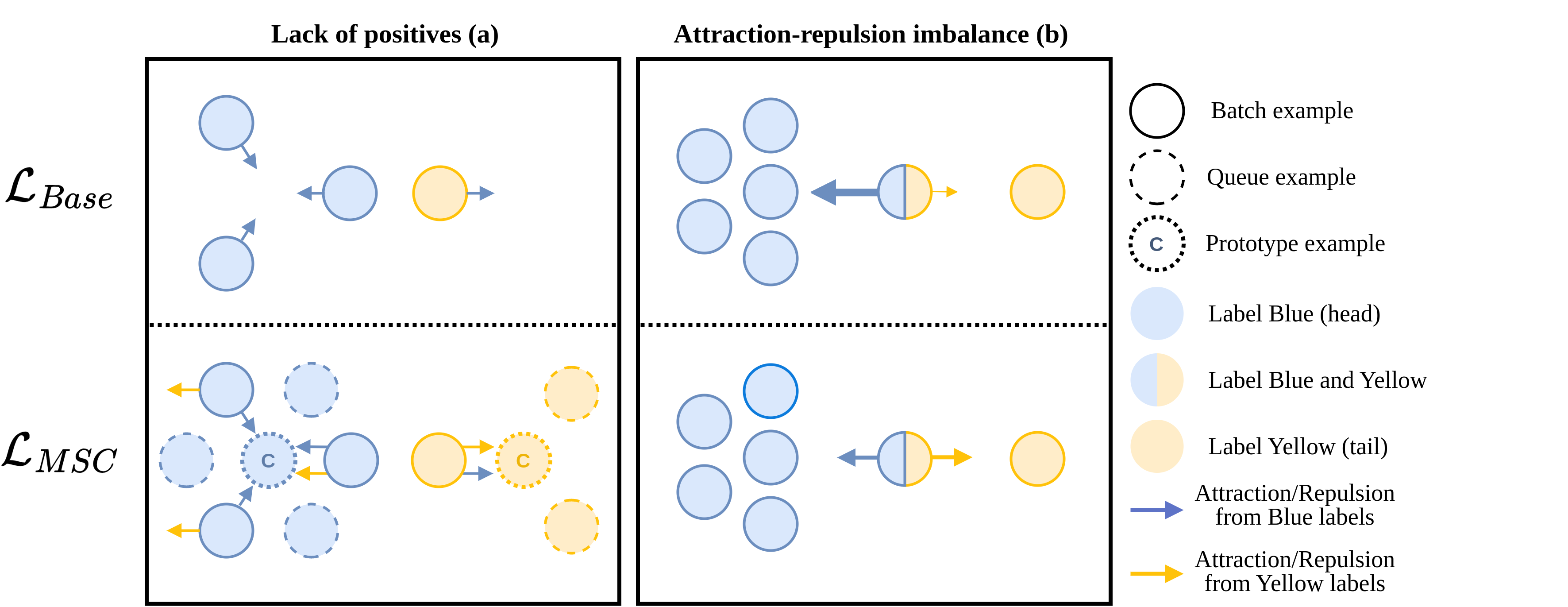
0
Exploring Contrastive Learning for Long-Tailed Multi-Label Text Classification
Alexandre Audibert, Aur'elien Gauffre, Massih-Reza Amini
Learning an effective representation in multi-label text classification (MLTC) is a significant challenge in NLP. This challenge arises from the inherent complexity of the task, which is shaped by two key factors: the intricate connections between labels and the widespread long-tailed distribution of the data. To overcome this issue, one potential approach involves integrating supervised contrastive learning with classical supervised loss functions. Although contrastive learning has shown remarkable performance in multi-class classification, its impact in the multi-label framework has not been thoroughly investigated. In this paper, we conduct an in-depth study of supervised contrastive learning and its influence on representation in MLTC context. We emphasize the importance of considering long-tailed data distributions to build a robust representation space, which effectively addresses two critical challenges associated with contrastive learning that we identify: the lack of positives and the attraction-repulsion imbalance. Building on this insight, we introduce a novel contrastive loss function for MLTC. It attains Micro-F1 scores that either match or surpass those obtained with other frequently employed loss functions, and demonstrates a significant improvement in Macro-F1 scores across three multi-label datasets.
Read more4/16/2024