Text-guided Foundation Model Adaptation for Long-Tailed Medical Image Classification

0
Sign in to get full access
Overview
- The provided paper discusses a text-guided approach to adapt a foundation model for long-tailed medical image classification.
- The key idea is to leverage text descriptions of medical images to guide the adaptation of a pre-trained model to better recognize rare disease classes.
- The authors demonstrate the effectiveness of their approach on long-tailed medical image datasets, achieving improvements over previous methods.
Plain English Explanation
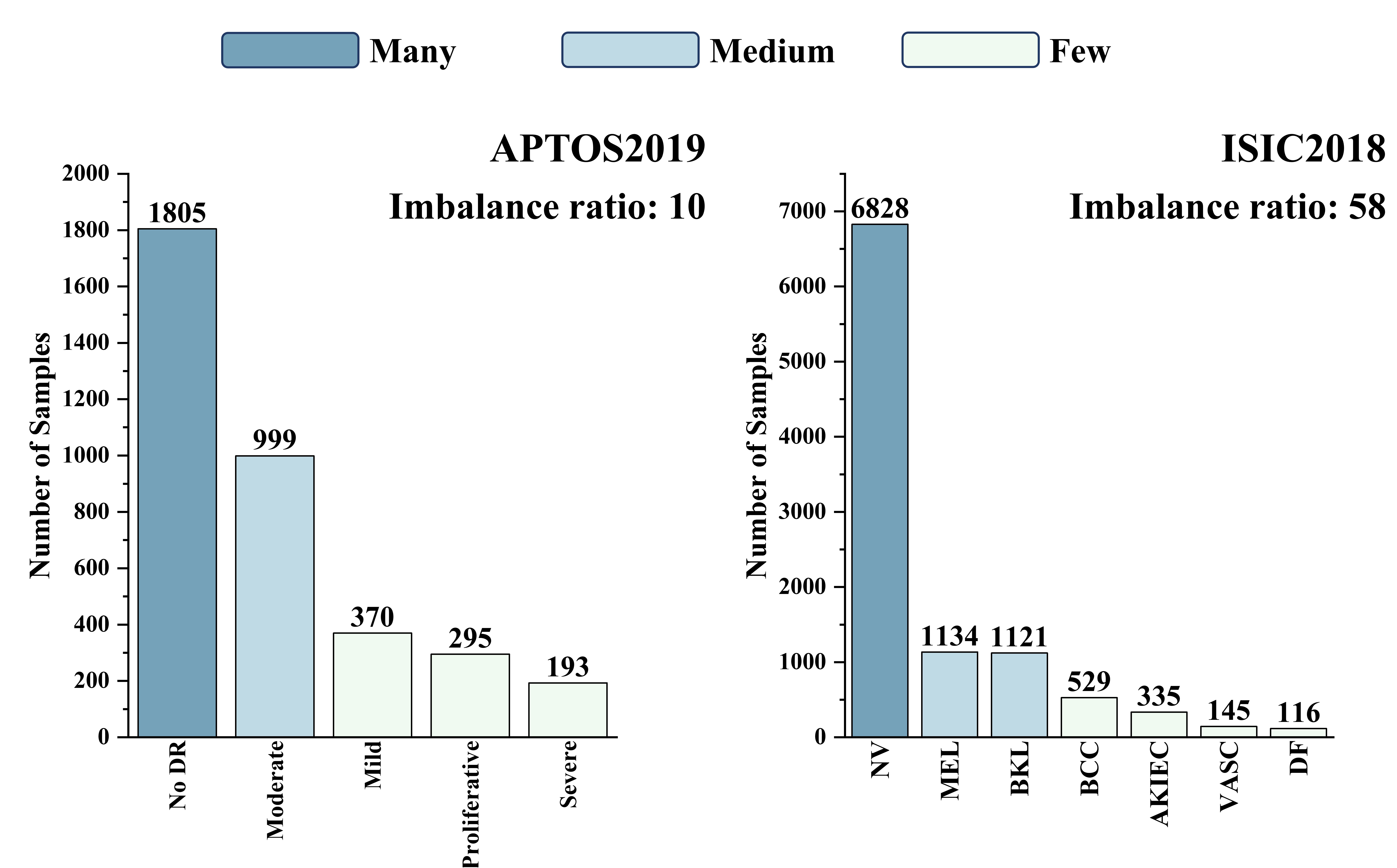
In the world of medical imaging, there is often a long-tailed distribution of disease types. This means that some diseases are very common, while others are quite rare. Traditional machine learning models can struggle to accurately classify these rare disease cases.
The authors of this paper propose a new approach to address this challenge. They start with a pre-trained foundation model - a powerful machine learning model that has been trained on a large, general dataset. They then use text descriptions of the medical images to guide the adaptation of this foundation model, allowing it to better recognize the rare disease classes.
The key insight is that the text descriptions can provide additional information and context that helps the model understand the unique characteristics of the rare disease cases. By incorporating this textual guidance, the adapted model is able to more accurately classify a wide range of disease types, even those that are quite uncommon.
Technical Explanation
The authors propose a text-guided foundation model adaptation approach for long-tailed medical image classification. They start with a pre-trained vision-language model, such as CLIP, and fine-tune it on a long-tailed medical image dataset.
The adaptation process involves two key steps:
- Text-guided Feature Extraction: The authors use the text descriptions associated with each medical image to guide the feature extraction process of the foundation model. This helps the model focus on the most relevant visual features for disease classification.
- Text-guided Classification Head: The authors incorporate the text features into the classification head of the model, allowing the textual information to directly influence the final disease predictions.
Through extensive experiments on multiple long-tailed medical image datasets, the authors demonstrate that their text-guided approach outperforms previous methods that do not leverage the textual information.
Critical Analysis
The authors acknowledge several limitations of their work:
- The approach relies on the availability of high-quality text descriptions for the medical images, which may not always be the case in real-world scenarios.
- The performance of the text-guided adaptation may be sensitive to the specific architecture and characteristics of the foundation model being used.
- The authors do not explore the potential for cascading errors from the text-guided feature extraction and classification steps.
Further research could investigate ways to reduce the reliance on high-quality text annotations, as well as examine the robustness of the approach across a wider range of foundation models and medical image domains.
Conclusion
This paper presents a novel text-guided approach for adapting foundation models to improve long-tailed medical image classification. By leveraging the textual information associated with the images, the authors demonstrate significant performance improvements over existing methods.
The proposed technique has the potential to enhance the accuracy and robustness of medical image analysis systems, ultimately leading to better clinical decision-making and patient outcomes. As the field of medical AI continues to evolve, approaches like this that can effectively handle long-tailed distributions will be increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Text-guided Foundation Model Adaptation for Long-Tailed Medical Image Classification
Sirui Li, Li Lin, Yijin Huang, Pujin Cheng, Xiaoying Tang
In medical contexts, the imbalanced data distribution in long-tailed datasets, due to scarce labels for rare diseases, greatly impairs the diagnostic accuracy of deep learning models. Recent multimodal text-image supervised foundation models offer new solutions to data scarcity through effective representation learning. However, their limited medical-specific pretraining hinders their performance in medical image classification relative to natural images. To address this issue, we propose a novel Text-guided Foundation model Adaptation for Long-Tailed medical image classification (TFA-LT). We adopt a two-stage training strategy, integrating representations from the foundation model using just two linear adapters and a single ensembler for balanced outcomes. Experimental results on two long-tailed medical image datasets validate the simplicity, lightweight and efficiency of our approach: requiring only 6.1% GPU memory usage of the current best-performing algorithm, our method achieves an accuracy improvement of up to 27.1%, highlighting the substantial potential of foundation model adaptation in this area.
Read more8/28/2024

0
Text-Guided Mixup Towards Long-Tailed Image Categorization
Richard Franklin, Jiawei Yao, Deyang Zhong, Qi Qian, Juhua Hu
In many real-world applications, the frequency distribution of class labels for training data can exhibit a long-tailed distribution, which challenges traditional approaches of training deep neural networks that require heavy amounts of balanced data. Gathering and labeling data to balance out the class label distribution can be both costly and time-consuming. Many existing solutions that enable ensemble learning, re-balancing strategies, or fine-tuning applied to deep neural networks are limited by the inert problem of few class samples across a subset of classes. Recently, vision-language models like CLIP have been observed as effective solutions to zero-shot or few-shot learning by grasping a similarity between vision and language features for image and text pairs. Considering that large pre-trained vision-language models may contain valuable side textual information for minor classes, we propose to leverage text supervision to tackle the challenge of long-tailed learning. Concretely, we propose a novel text-guided mixup technique that takes advantage of the semantic relations between classes recognized by the pre-trained text encoder to help alleviate the long-tailed problem. Our empirical study on benchmark long-tailed tasks demonstrates the effectiveness of our proposal with a theoretical guarantee. Our code is available at https://github.com/rsamf/text-guided-mixup.
Read more9/6/2024

0
Latent-based Diffusion Model for Long-tailed Recognition
Pengxiao Han, Changkun Ye, Jieming Zhou, Jing Zhang, Jie Hong, Xuesong Li
Long-tailed imbalance distribution is a common issue in practical computer vision applications. Previous works proposed methods to address this problem, which can be categorized into several classes: re-sampling, re-weighting, transfer learning, and feature augmentation. In recent years, diffusion models have shown an impressive generation ability in many sub-problems of deep computer vision. However, its powerful generation has not been explored in long-tailed problems. We propose a new approach, the Latent-based Diffusion Model for Long-tailed Recognition (LDMLR), as a feature augmentation method to tackle the issue. First, we encode the imbalanced dataset into features using the baseline model. Then, we train a Denoising Diffusion Implicit Model (DDIM) using these encoded features to generate pseudo-features. Finally, we train the classifier using the encoded and pseudo-features from the previous two steps. The model's accuracy shows an improvement on the CIFAR-LT and ImageNet-LT datasets by using the proposed method.
Read more4/24/2024
0
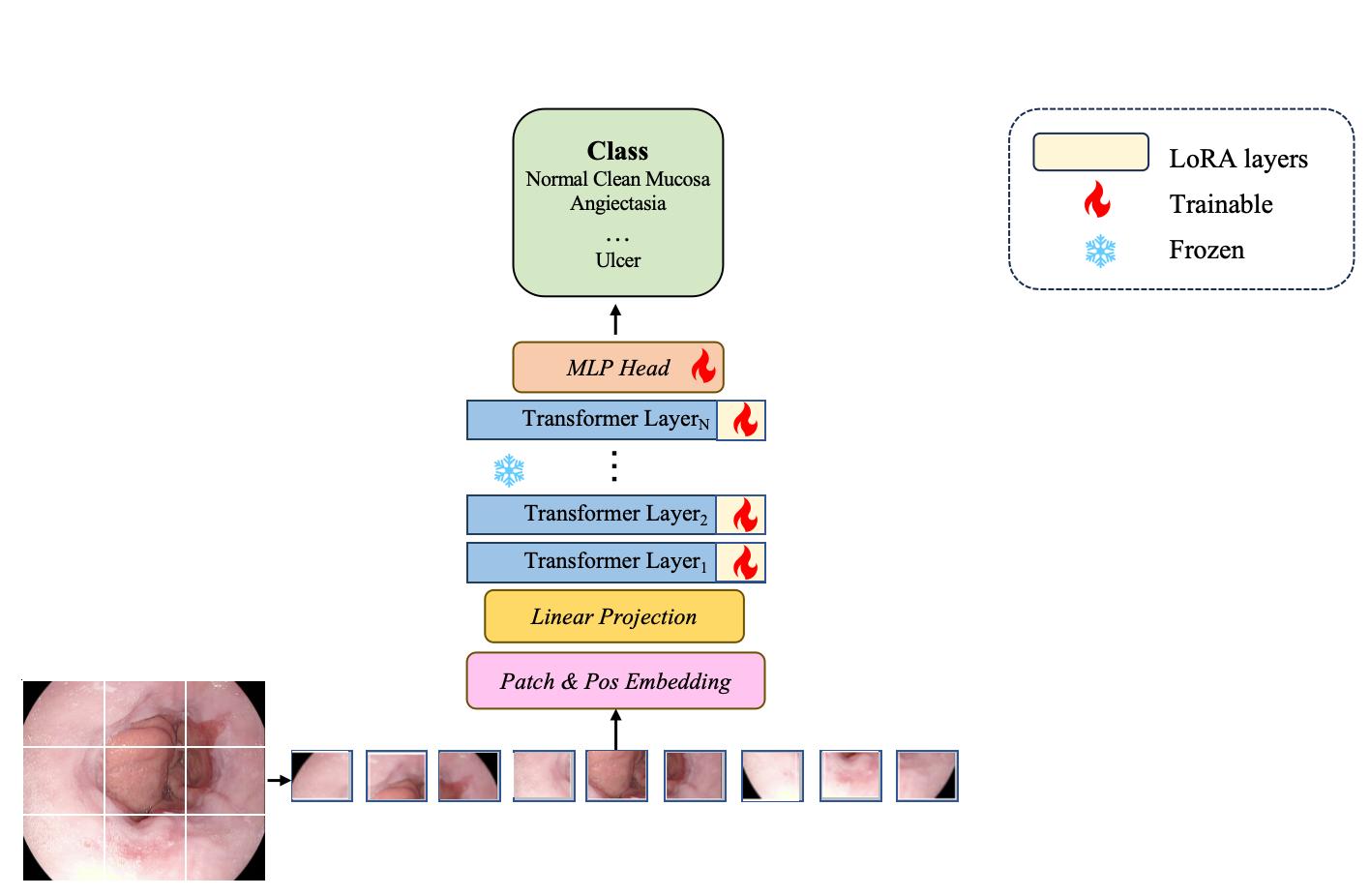
Learning to Adapt Foundation Model DINOv2 for Capsule Endoscopy Diagnosis
Bowen Zhang, Ying Chen, Long Bai, Yan Zhao, Yuxiang Sun, Yixuan Yuan, Jianhua Zhang, Hongliang Ren
Foundation models have become prominent in computer vision, achieving notable success in various tasks. However, their effectiveness largely depends on pre-training with extensive datasets. Applying foundation models directly to small datasets of capsule endoscopy images from scratch is challenging. Pre-training on broad, general vision datasets is crucial for successfully fine-tuning our model for specific tasks. In this work, we introduce a simplified approach called Adapt foundation models with a low-rank adaptation (LoRA) technique for easier customization. Our method, inspired by the DINOv2 foundation model, applies low-rank adaptation learning to tailor foundation models for capsule endoscopy diagnosis effectively. Unlike traditional fine-tuning methods, our strategy includes LoRA layers designed to absorb specific surgical domain knowledge. During the training process, we keep the main model (the backbone encoder) fixed and focus on optimizing the LoRA layers and the disease classification component. We tested our method on two publicly available datasets for capsule endoscopy disease classification. The results were impressive, with our model achieving 97.75% accuracy on the Kvasir-Capsule dataset and 98.81% on the Kvasirv2 dataset. Our solution demonstrates that foundation models can be adeptly adapted for capsule endoscopy diagnosis, highlighting that mere reliance on straightforward fine-tuning or pre-trained models from general computer vision tasks is inadequate for such specific applications.
Read more7/2/2024