Text-To-Speech Synthesis In The Wild

0
Sign in to get full access
Overview
- Text-to-speech (TTS) synthesis is the process of generating artificial speech from text.
- Deploying TTS systems "in the wild" refers to using them in real-world applications beyond controlled research settings.
- This paper examines the challenges and considerations involved in deploying TTS systems in unconstrained environments.
Plain English Explanation
TTS systems are software that can convert written text into spoken audio. When these systems are used in real-world applications, such as digital assistants or audiobook readers, they face a variety of challenges that don't exist in controlled research settings.
The paper explores some of these challenges, such as:
- Handling diverse content: TTS systems need to be able to handle a wide range of text, from formal writing to casual conversation, without sounding unnatural.
- Dealing with errors: Real-world text often contains typos, abbreviations, or unconventional formatting that can trip up TTS systems.
- Accounting for user preferences: Different users may have different preferences for the voice, speaking style, or pronunciation of the TTS output.
By understanding these challenges, the researchers hope to guide the development of more robust and user-friendly TTS systems that can be successfully deployed "in the wild" - in real-world applications where they need to handle diverse and unpredictable content.
Technical Explanation
The paper examines the challenges involved in deploying text-to-speech (TTS) synthesis systems in unconstrained, real-world environments, which the authors refer to as "in the wild."
The researchers identify several key challenges, including:
-
Handling Diverse Content: TTS systems need to be able to handle a wide range of text, from formal writing to casual conversation, without sounding unnatural or out of place.
-
Dealing with Errors: Real-world text often contains typos, abbreviations, or unconventional formatting that can trip up TTS systems, leading to poor pronunciation or unexpected outputs.
-
Accounting for User Preferences: Different users may have different preferences for the voice, speaking style, or pronunciation of the TTS output, requiring the system to be highly adaptable.
To address these challenges, the researchers suggest that TTS systems need to be designed with a focus on robustness, flexibility, and personalization, rather than just optimizing for a narrow set of conditions.
Critical Analysis
The paper provides a valuable perspective on the practical challenges of deploying TTS systems in real-world applications. The authors acknowledge that while significant progress has been made in TTS technology, there are still many hurdles to overcome when transitioning these systems from controlled research settings to the unpredictable conditions of the "wild."
One limitation of the paper is that it does not propose specific solutions to the challenges it identifies. The authors primarily focus on outlining the problem space, without delving into the technical details of how TTS systems could be designed or adapted to address these issues.
Additionally, the paper does not address the potential ethical and societal implications of widespread TTS deployment, such as concerns around privacy, accessibility, or the perpetuation of biases. As TTS systems become more ubiquitous, these broader considerations will become increasingly important to consider.
Overall, the paper serves as a valuable starting point for further research and development in the field of TTS synthesis, highlighting the need for a more holistic approach that prioritizes robustness, flexibility, and user-centric design.
Conclusion
This paper provides a thought-provoking examination of the challenges involved in deploying text-to-speech (TTS) synthesis systems in real-world, "in the wild" applications. By identifying key issues such as handling diverse content, dealing with errors, and accounting for user preferences, the researchers underscore the need for TTS systems to be designed with a focus on robustness, flexibility, and personalization.
As TTS technology continues to advance, this paper serves as a valuable guide for researchers and developers working to bring these systems out of the controlled research environment and into the unpredictable conditions of the "wild." By addressing these challenges, the field can work towards creating more user-friendly and reliable TTS solutions that can be widely adopted and integrated into a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Text-To-Speech Synthesis In The Wild
Jee-weon Jung, Wangyou Zhang, Soumi Maiti, Yihan Wu, Xin Wang, Ji-Hoon Kim, Yuta Matsunaga, Seyun Um, Jinchuan Tian, Hye-jin Shim, Nicholas Evans, Joon Son Chung, Shinnosuke Takamichi, Shinji Watanabe
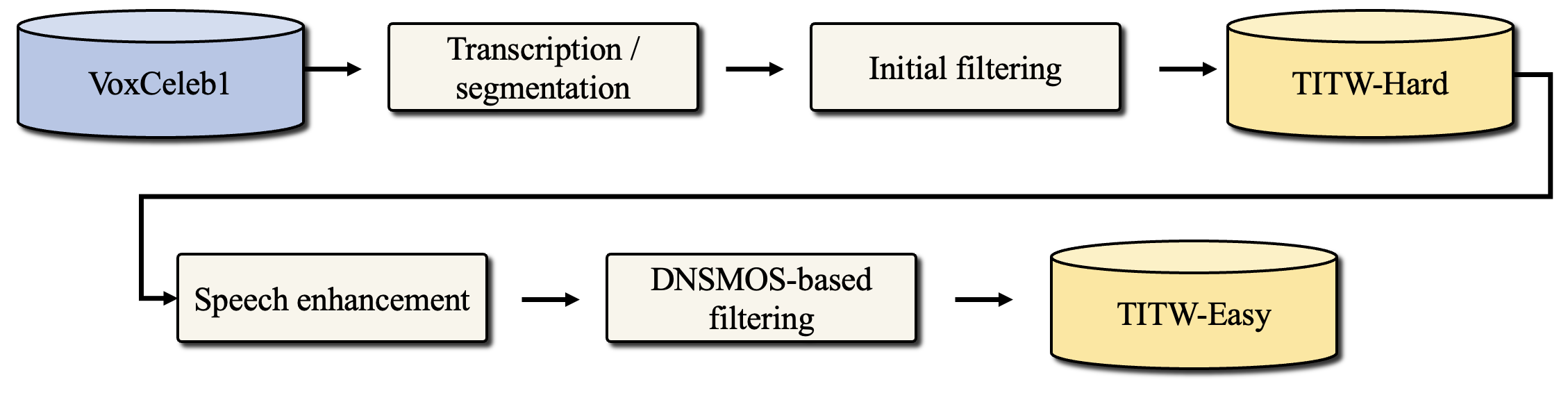
Text-to-speech (TTS) systems are traditionally trained using modest databases of studio-quality, prompted or read speech collected in benign acoustic environments such as anechoic rooms. The recent literature nonetheless shows efforts to train TTS systems using data collected in the wild. While this approach allows for the use of massive quantities of natural speech, until now, there are no common datasets. We introduce the TTS In the Wild (TITW) dataset, the result of a fully automated pipeline, in this case, applied to the VoxCeleb1 dataset commonly used for speaker recognition. We further propose two training sets. TITW-Hard is derived from the transcription, segmentation, and selection of VoxCeleb1 source data. TITW-Easy is derived from the additional application of enhancement and additional data selection based on DNSMOS. We show that a number of recent TTS models can be trained successfully using TITW-Easy, but that it remains extremely challenging to produce similar results using TITW-Hard. Both the dataset and protocols are publicly available and support the benchmarking of TTS systems trained using TITW data.
Read more9/16/2024

0
Utilizing TTS Synthesized Data for Efficient Development of Keyword Spotting Model
Hyun Jin Park, Dhruuv Agarwal, Neng Chen, Rentao Sun, Kurt Partridge, Justin Chen, Harry Zhang, Pai Zhu, Jacob Bartel, Kyle Kastner, Gary Wang, Andrew Rosenberg, Quan Wang
This paper explores the use of TTS synthesized training data for KWS (keyword spotting) task while minimizing development cost and time. Keyword spotting models require a huge amount of training data to be accurate, and obtaining such training data can be costly. In the current state of the art, TTS models can generate large amounts of natural-sounding data, which can help reducing cost and time for KWS model development. Still, TTS generated data can be lacking diversity compared to real data. To pursue maximizing KWS model accuracy under the constraint of limited resources and current TTS capability, we explored various strategies to mix TTS data and real human speech data, with a focus on minimizing real data use and maximizing diversity of TTS output. Our experimental results indicate that relatively small amounts of real audio data with speaker diversity (100 speakers, 2k utterances) and large amounts of TTS synthesized data can achieve reasonably high accuracy (within 3x error rate of baseline), compared to the baseline (trained with 3.8M real positive utterances).
Read more7/29/2024
0
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024

0
Synth4Kws: Synthesized Speech for User Defined Keyword Spotting in Low Resource Environments
Pai Zhu, Dhruuv Agarwal, Jacob W. Bartel, Kurt Partridge, Hyun Jin Park, Quan Wang
One of the challenges in developing a high quality custom keyword spotting (KWS) model is the lengthy and expensive process of collecting training data covering a wide range of languages, phrases and speaking styles. We introduce Synth4Kws - a framework to leverage Text to Speech (TTS) synthesized data for custom KWS in different resource settings. With no real data, we found increasing TTS phrase diversity and utterance sampling monotonically improves model performance, as evaluated by EER and AUC metrics over 11k utterances of the speech command dataset. In low resource settings, with 50k real utterances as a baseline, we found using optimal amounts of TTS data can improve EER by 30.1% and AUC by 46.7%. Furthermore, we mix TTS data with varying amounts of real data and interpolate the real data needed to achieve various quality targets. Our experiments are based on English and single word utterances but the findings generalize to i18n languages and other keyword types.
Read more7/25/2024