TextCAVs: Debugging vision models using text

0

Sign in to get full access
Overview
- TextCAVs is a novel approach for debugging vision models using text explanations.
- It aims to provide interpretability for vision models by leveraging text-based concept activation vectors (TextCAVs).
- TextCAVs can identify the specific textual concepts that drive a vision model's predictions, enabling better understanding and debugging of the model.
Plain English Explanation
TextCAVs is a new technique that can help us understand how vision models, like those used for medical image analysis, make their predictions. These vision models are often like black boxes - we can see the inputs (the images) and the outputs (the predictions), but it's not always clear how the model arrived at those predictions.
TextCAVs tries to open up that black box by connecting the model's internal workings to textual concepts. The key idea is that vision models don't just look at pixels - they also learn to recognize higher-level visual concepts, like "lung" or "fracture." TextCAVs can identify which of these textual concepts are most important for a given prediction, allowing researchers and developers to better understand and debug the model.
For example, if a vision model for analyzing chest X-rays is mistakenly predicting "pneumonia" when the image actually shows a "lung nodule," TextCAVs could reveal that the model is overly relying on textual concepts like "opacity" and "consolidation" rather than more specific concepts like "nodule" or "mass." This information can then be used to improve the model's performance and robustness.
Technical Explanation
TextCAVs works by first training a separate text-based model to predict the same target labels as the vision model. This text model learns to associate textual concepts with the target labels. Then, when the vision model makes a prediction, TextCAVs can identify which textual concepts are most strongly activated, providing insight into the model's reasoning.
The paper demonstrates the effectiveness of TextCAVs on two medical imaging tasks: chest X-ray classification and skin lesion classification. In the chest X-ray experiments, TextCAVs was able to highlight textual concepts like "opacity" and "consolidation" that were driving incorrect "pneumonia" predictions, allowing the researchers to improve the model. Similarly, in the skin lesion experiments, TextCAVs uncovered textual concepts like "melanoma" and "nevus" that were influential for the model's predictions.
Critical Analysis
The TextCAVs approach is a promising step towards making vision models more interpretable and debuggable. By connecting the model's internal workings to textual concepts, it provides a valuable window into how the model is making its decisions.
However, the paper does note some limitations. The text-based model used to generate the TextCAVs is trained separately from the vision model, so there may be some disconnect between the two. Additionally, the paper focuses on relatively simple vision tasks, and it's unclear how well TextCAVs would scale to more complex models and domains.
Further research could explore ways to more tightly integrate the text-based and vision-based models, potentially by using a single model that can learn from both modalities simultaneously. Applying TextCAVs to a wider range of vision tasks, including more challenging ones, would also help demonstrate its broader applicability and robustness.
Conclusion
TextCAVs represents an important step towards making vision models more transparent and interpretable. By connecting the model's predictions to specific textual concepts, it provides a valuable tool for researchers and developers to better understand and debug these powerful but often opaque systems.
As AI models become increasingly influential in high-stakes domains like healthcare, developing interpretability techniques like TextCAVs will be crucial for building trust, ensuring fairness, and ultimately improving the real-world impact of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TextCAVs: Debugging vision models using text
Angus Nicolson, Yarin Gal, J. Alison Noble
Concept-based interpretability methods are a popular form of explanation for deep learning models which provide explanations in the form of high-level human interpretable concepts. These methods typically find concept activation vectors (CAVs) using a probe dataset of concept examples. This requires labelled data for these concepts -- an expensive task in the medical domain. We introduce TextCAVs: a novel method which creates CAVs using vision-language models such as CLIP, allowing for explanations to be created solely using text descriptions of the concept, as opposed to image exemplars. This reduced cost in testing concepts allows for many concepts to be tested and for users to interact with the model, testing new ideas as they are thought of, rather than a delay caused by image collection and annotation. In early experimental results, we demonstrate that TextCAVs produces reasonable explanations for a chest x-ray dataset (MIMIC-CXR) and natural images (ImageNet), and that these explanations can be used to debug deep learning-based models.
Read more8/19/2024
0
Explaining Explainability: Understanding Concept Activation Vectors
Angus Nicolson, Lisa Schut, J. Alison Noble, Yarin Gal
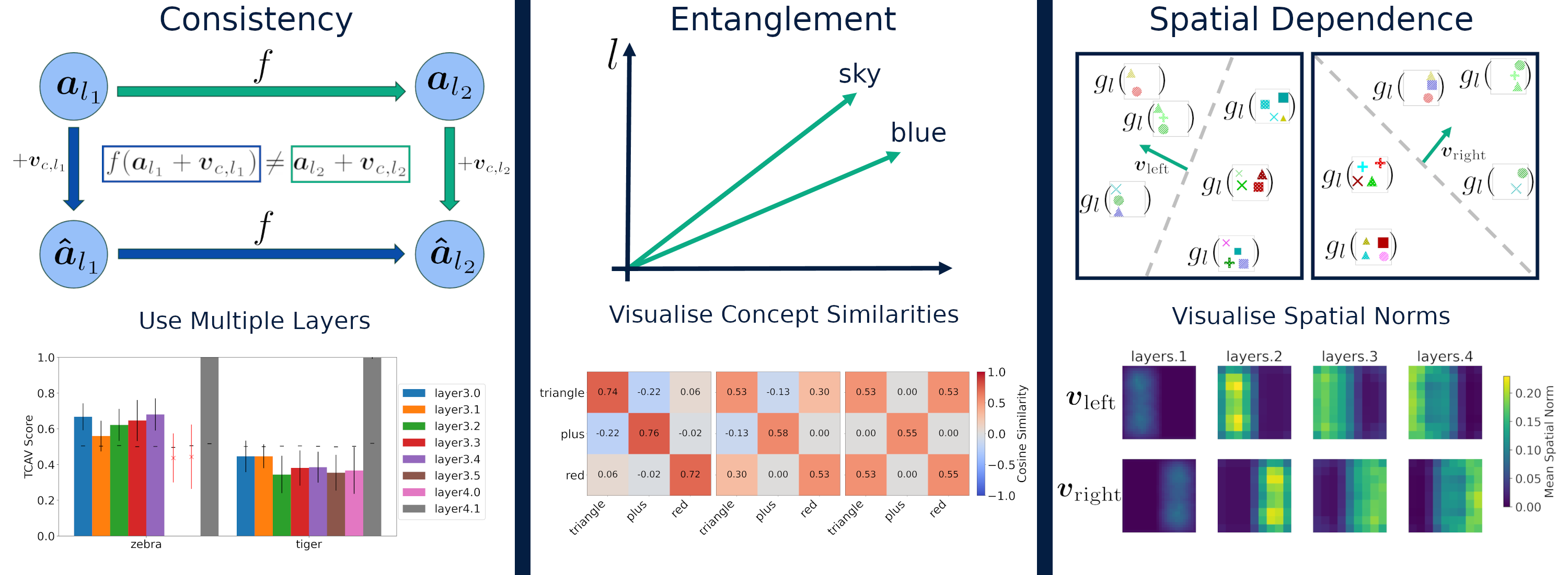
Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
Read more4/8/2024

0
Explainable Concept Generation through Vision-Language Preference Learning
Aditya Taparia, Som Sagar, Ransalu Senanayake
Concept-based explanations have become a popular choice for explaining deep neural networks post-hoc because, unlike most other explainable AI techniques, they can be used to test high-level visual concepts that are not directly related to feature attributes. For instance, the concept of stripes is important to classify an image as a zebra. Concept-based explanation methods, however, require practitioners to guess and collect multiple candidate concept image sets, which can often be imprecise and labor-intensive. Addressing this limitation, in this paper, we frame concept image set creation as an image generation problem. However, since naively using a generative model does not result in meaningful concepts, we devise a reinforcement learning-based preference optimization algorithm that fine-tunes the vision-language generative model from approximate textual descriptions of concepts. Through a series of experiments, we demonstrate the capability of our method to articulate complex, abstract concepts that are otherwise challenging to craft manually. In addition to showing the efficacy and reliability of our method, we show how our method can be used as a diagnostic tool for analyzing neural networks.
Read more8/27/2024

0
Knowledge graphs for empirical concept retrieval
Lenka Tv{e}tkov'a, Teresa Karen Scheidt, Maria Mandrup Fogh, Ellen Marie Gaunby J{o}rgensen, Finn {AA}rup Nielsen, Lars Kai Hansen
Concept-based explainable AI is promising as a tool to improve the understanding of complex models at the premises of a given user, viz. as a tool for personalized explainability. An important class of concept-based explainability methods is constructed with empirically defined concepts, indirectly defined through a set of positive and negative examples, as in the TCAV approach (Kim et al., 2018). While it is appealing to the user to avoid formal definitions of concepts and their operationalization, it can be challenging to establish relevant concept datasets. Here, we address this challenge using general knowledge graphs (such as, e.g., Wikidata or WordNet) for comprehensive concept definition and present a workflow for user-driven data collection in both text and image domains. The concepts derived from knowledge graphs are defined interactively, providing an opportunity for personalization and ensuring that the concepts reflect the user's intentions. We test the retrieved concept datasets on two concept-based explainability methods, namely concept activation vectors (CAVs) and concept activation regions (CARs) (Crabbe and van der Schaar, 2022). We show that CAVs and CARs based on these empirical concept datasets provide robust and accurate explanations. Importantly, we also find good alignment between the models' representations of concepts and the structure of knowledge graphs, i.e., human representations. This supports our conclusion that knowledge graph-based concepts are relevant for XAI.
Read more4/11/2024