TextIM: Part-aware Interactive Motion Synthesis from Text

0

Sign in to get full access
Overview
- The paper introduces TextIM, a novel method for generating interactive motion sequences from text descriptions.
- TextIM is part-aware, meaning it can generate motions for individual body parts in response to text inputs.
- The method uses a transformer-based architecture to learn the relationship between text and motion, and allows for interactive control of the generated animations.
Plain English Explanation
TextIM: Part-aware Interactive Motion Synthesis from Text presents a new way to create animated human motions based on written descriptions. Rather than manually animating characters, this approach allows you to simply describe what you want the character to do, and the system will generate the corresponding motion.
The key innovation is that TextIM can create motions for specific body parts. So if you want a character to wave their hand while walking, the system can generate that detailed motion rather than just creating a generic full-body walk. This part-aware control gives you more flexibility to craft the exact movements you want.
Under the hood, TextIM uses a deep learning model built on transformers - a type of neural network that excels at understanding language. The model learns the relationship between text descriptions and the corresponding human motions. This allows it to take new text inputs and generate realistic, interactive animations in response.
Technical Explanation
TextIM: Part-aware Interactive Motion Synthesis from Text builds on prior work in text-driven motion synthesis, but introduces a part-aware approach that can generate motions for individual body parts. This is achieved through a transformer-based architecture that learns the mapping between text descriptions and the corresponding body part movements.
The model takes a text description as input and outputs a sequence of 3D joint positions representing the full-body motion. Importantly, the model also produces a set of part-level motion parameters that control the movement of individual body parts, such as the arms, legs, and torso. This allows for more fine-grained control and interaction with the generated animations.
The authors introduce several key innovations, including a novel part-aware motion discriminator and a part-aware motion blending module. These components help the model learn the correlations between text and part-level motions, and seamlessly combine the part-level motions into a coherent full-body animation.
Critical Analysis
TextIM: Part-aware Interactive Motion Synthesis from Text represents an interesting advance in text-driven motion synthesis, but there are a few potential limitations and areas for future work:
-
The model was trained on a limited dataset of motion capture data, so its ability to generalize to a wider range of motions and body types may be constrained. Expanding the training data could improve the model's versatility.
-
The part-aware control is a valuable feature, but the paper does not explore the limits of this capability. It's unclear how fine-grained the part-level control can be, or whether the model can handle highly complex, coordinated multi-part motions.
-
The interactive control aspect of TextIM is briefly mentioned but not deeply explored. More details on how users can dynamically manipulate the generated animations would be helpful.
Overall, TextIM: Part-aware Interactive Motion Synthesis from Text represents an important step forward in text-to-motion synthesis, with the potential to enable more natural and expressive character animations driven by language. Further research and development could unlock even more powerful applications in areas like gaming, filmmaking, and virtual reality.
Conclusion
TextIM: Part-aware Interactive Motion Synthesis from Text introduces a novel approach for generating human motions from text descriptions, with the key innovation of part-aware control. This allows for more detailed and interactive character animations, where specific body parts can be controlled independently.
The transformer-based architecture learns the mapping between language and motion, enabling users to create customized animations simply by describing what they want the character to do. While the current model has some limitations, this research opens up exciting possibilities for more natural and expressive text-driven character animation in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TextIM: Part-aware Interactive Motion Synthesis from Text
Siyuan Fan, Bo Du, Xiantao Cai, Bo Peng, Longling Sun
In this work, we propose TextIM, a novel framework for synthesizing TEXT-driven human Interactive Motions, with a focus on the precise alignment of part-level semantics. Existing methods often overlook the critical roles of interactive body parts and fail to adequately capture and align part-level semantics, resulting in inaccuracies and even erroneous movement outcomes. To address these issues, TextIM utilizes a decoupled conditional diffusion framework to enhance the detailed alignment between interactive movements and corresponding semantic intents from textual descriptions. Our approach leverages large language models, functioning as a human brain, to identify interacting human body parts and to comprehend interaction semantics to generate complicated and subtle interactive motion. Guided by the refined movements of the interacting parts, TextIM further extends these movements into a coherent whole-body motion. We design a spatial coherence module to complement the entire body movements while maintaining consistency and harmony across body parts using a part graph convolutional network. For training and evaluation, we carefully selected and re-labeled interactive motions from HUMANML3D to develop a specialized dataset. Experimental results demonstrate that TextIM produces semantically accurate human interactive motions, significantly enhancing the realism and applicability of synthesized interactive motions in diverse scenarios, even including interactions with deformable and dynamically changing objects.
Read more8/7/2024
0
T3M: Text Guided 3D Human Motion Synthesis from Speech
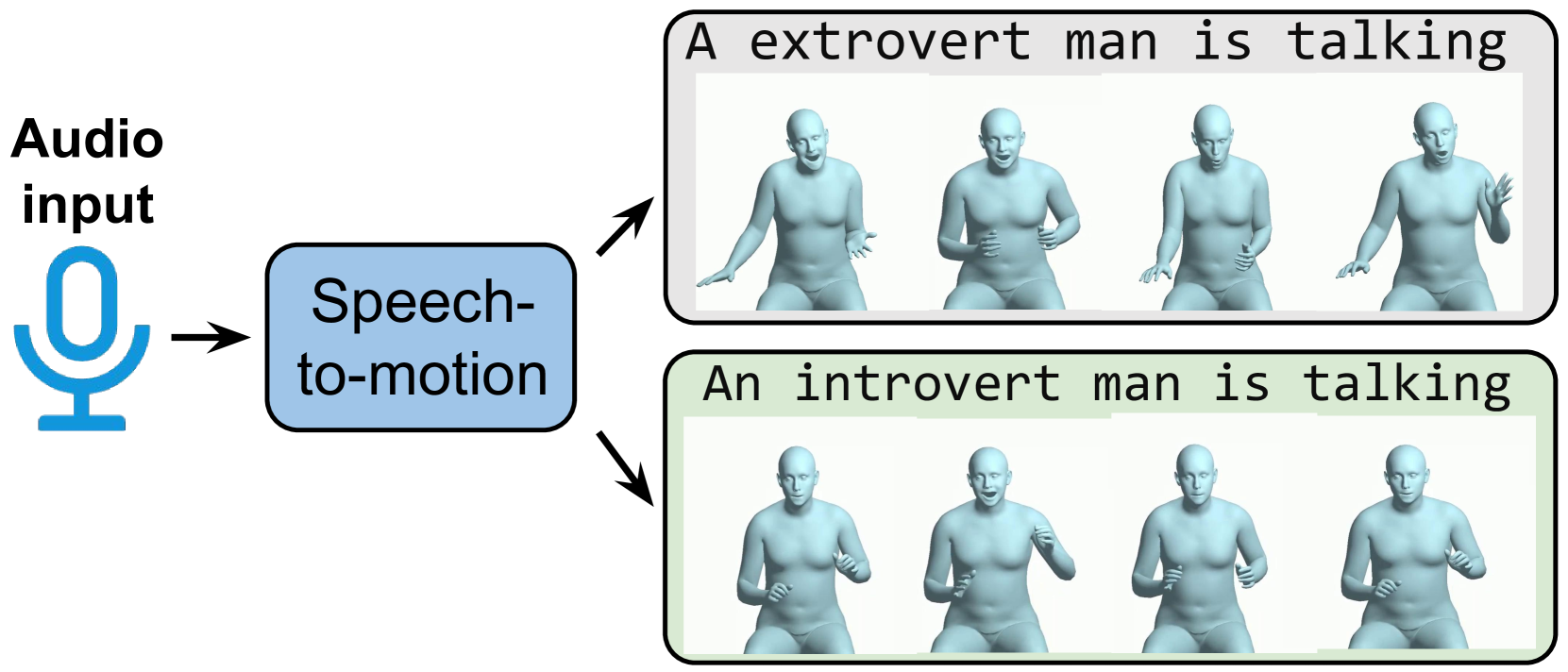
Wenshuo Peng, Kaipeng Zhang, Sai Qian Zhang
Speech-driven 3D motion synthesis seeks to create lifelike animations based on human speech, with potential uses in virtual reality, gaming, and the film production. Existing approaches reply solely on speech audio for motion generation, leading to inaccurate and inflexible synthesis results. To mitigate this problem, we introduce a novel text-guided 3D human motion synthesis method, termed textit{T3M}. Unlike traditional approaches, T3M allows precise control over motion synthesis via textual input, enhancing the degree of diversity and user customization. The experiment results demonstrate that T3M can greatly outperform the state-of-the-art methods in both quantitative metrics and qualitative evaluations. We have publicly released our code at href{https://github.com/Gloria2tt/T3M.git}{https://github.com/Gloria2tt/T3M.git}
Read more8/26/2024
0
Generating Human Interaction Motions in Scenes with Text Control
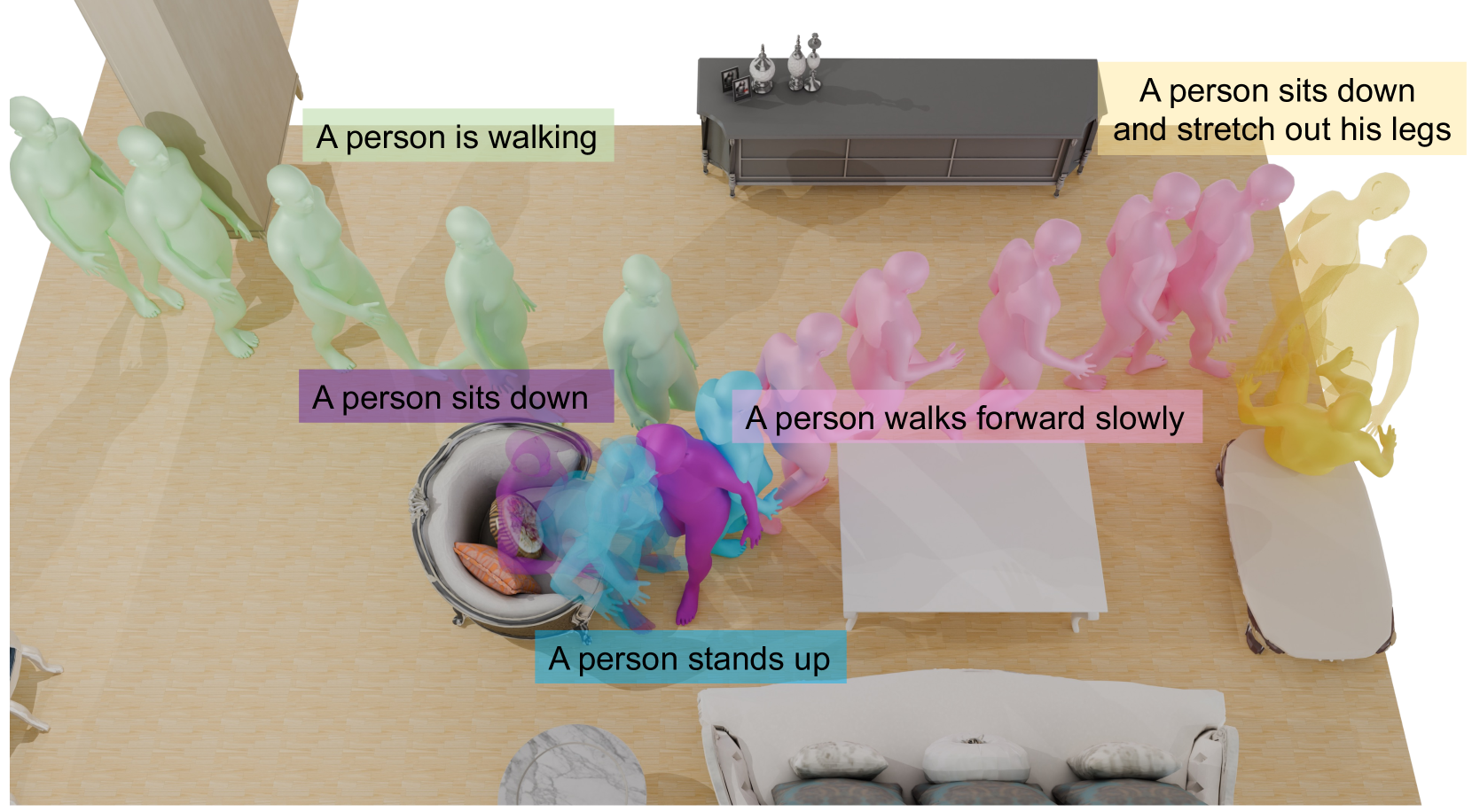
Hongwei Yi, Justus Thies, Michael J. Black, Xue Bin Peng, Davis Rempe
We present TeSMo, a method for text-controlled scene-aware motion generation based on denoising diffusion models. Previous text-to-motion methods focus on characters in isolation without considering scenes due to the limited availability of datasets that include motion, text descriptions, and interactive scenes. Our approach begins with pre-training a scene-agnostic text-to-motion diffusion model, emphasizing goal-reaching constraints on large-scale motion-capture datasets. We then enhance this model with a scene-aware component, fine-tuned using data augmented with detailed scene information, including ground plane and object shapes. To facilitate training, we embed annotated navigation and interaction motions within scenes. The proposed method produces realistic and diverse human-object interactions, such as navigation and sitting, in different scenes with various object shapes, orientations, initial body positions, and poses. Extensive experiments demonstrate that our approach surpasses prior techniques in terms of the plausibility of human-scene interactions, as well as the realism and variety of the generated motions. Code will be released upon publication of this work at https://research.nvidia.com/labs/toronto-ai/tesmo.
Read more4/17/2024

0
New!Contact-aware Human Motion Generation from Textual Descriptions
Sihan Ma, Qiong Cao, Jing Zhang, Dacheng Tao
This paper addresses the problem of generating 3D interactive human motion from text. Given a textual description depicting the actions of different body parts in contact with static objects, we synthesize sequences of 3D body poses that are visually natural and physically plausible. Yet, this task poses a significant challenge due to the inadequate consideration of interactions by physical contacts in both motion and textual descriptions, leading to unnatural and implausible sequences. To tackle this challenge, we create a novel dataset named RICH-CAT, representing Contact-Aware Texts constructed from the RICH dataset. RICH-CAT comprises high-quality motion, accurate human-object contact labels, and detailed textual descriptions, encompassing over 8,500 motion-text pairs across 26 indoor/outdoor actions. Leveraging RICH-CAT, we propose a novel approach named CATMO for text-driven interactive human motion synthesis that explicitly integrates human body contacts as evidence. We employ two VQ-VAE models to encode motion and body contact sequences into distinct yet complementary latent spaces and an intertwined GPT for generating human motions and contacts in a mutually conditioned manner. Additionally, we introduce a pre-trained text encoder to learn textual embeddings that better discriminate among various contact types, allowing for more precise control over synthesized motions and contacts. Our experiments demonstrate the superior performance of our approach compared to existing text-to-motion methods, producing stable, contact-aware motion sequences. Code and data will be available for research purposes at https://xymsh.github.io/RICH-CAT/
Read more9/17/2024