T3M: Text Guided 3D Human Motion Synthesis from Speech

0
Sign in to get full access
Overview
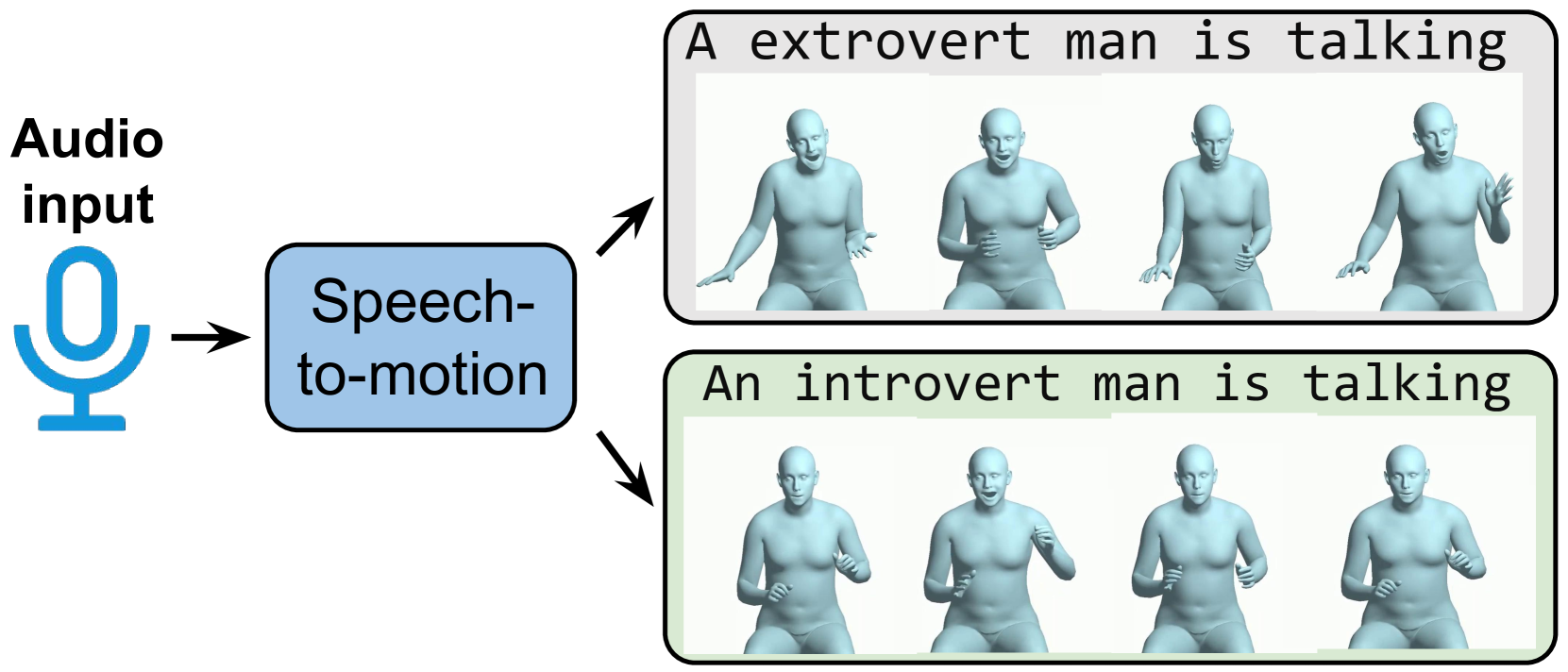
- Presents a novel framework, T3M, for text-guided 3D human motion synthesis from speech
- Leverages language models to map speech to motion by learning the connection between text and corresponding 3D human poses
- Generates realistic 3D human motion that is aligned with the given speech
Plain English Explanation
The paper introduces a new system called T3M that can create 3D animations of a human moving and gesturing based on spoken speech. This system takes advantage of recent advancements in language models to learn the relationship between text and the corresponding body movements.
By feeding the system a transcript of speech, it can then generate a 3D animation of a person speaking and moving in a way that matches the text. This allows for text-guided 3D human motion synthesis - creating lifelike 3D animations controlled by the words being spoken.
The key innovation is using powerful language models to bridge the gap between text and the complex 3D motion of a human body. This builds on prior work on multi-track timeline control from text and part-aware interactive motion synthesis from text. The authors show this approach can generate realistic 3D human animations that are well-synchronized with the input speech.
Technical Explanation
The T3M framework consists of several key components. First, it uses a pre-trained language model to encode the input speech transcript into a meaningful text representation. This text encoding is then fed into a motion prediction network that outputs a sequence of 3D human poses corresponding to the input text.
To train this motion prediction network, the authors leverage a large dataset of 3D human motion capture data aligned with transcripts of spoken speech. By learning the correlation between text and motion from this data, the network can generate plausible 3D human movements that match new speech inputs.
The authors also incorporate additional techniques to improve the quality and realism of the generated 3D motions. This includes using a differentiable renderer to provide fine-grained feedback during training, as well as applying physics-based constraints to ensure the motions obey the laws of human biomechanics.
Overall, the T3M framework demonstrates the potential of language models to enable text-driven 3D human motion synthesis, opening up new possibilities for applications like virtual avatars, animation, and interactive 3D environments. This builds on prior work on generating human motion in 3D scenes from text.
Critical Analysis
The paper makes a compelling case for the value of text-guided 3D human motion synthesis, but there are a few potential limitations and areas for further research:
- The motion prediction network was trained on a limited dataset of motion capture data, so the system may struggle to generate diverse or complex motion sequences outside of this training distribution.
- The authors do not provide extensive quantitative evaluation of the generated motion quality or alignment with input speech, so it's difficult to assess the system's real-world performance.
- While the differentiable renderer and physics-based constraints help improve realism, the motions could potentially be further enhanced through the use of more advanced human motion modeling techniques.
Additionally, it would be interesting to see how this approach could be extended to handle more open-ended language input beyond just speech transcripts, enabling truly freeform text-driven 3D animation generation.
Conclusion
Overall, the T3M framework represents an exciting step forward in using language models to enable text-guided 3D human motion synthesis from speech. By bridging the gap between text and complex 3D body movements, this work opens up new possibilities for realistic virtual avatars, interactive 3D environments, and other applications where lifelike human animation is required. While there is still room for improvement, this research demonstrates the power of combining language understanding with 3D animation to create compelling, text-driven visual experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
T3M: Text Guided 3D Human Motion Synthesis from Speech
Wenshuo Peng, Kaipeng Zhang, Sai Qian Zhang
Speech-driven 3D motion synthesis seeks to create lifelike animations based on human speech, with potential uses in virtual reality, gaming, and the film production. Existing approaches reply solely on speech audio for motion generation, leading to inaccurate and inflexible synthesis results. To mitigate this problem, we introduce a novel text-guided 3D human motion synthesis method, termed textit{T3M}. Unlike traditional approaches, T3M allows precise control over motion synthesis via textual input, enhancing the degree of diversity and user customization. The experiment results demonstrate that T3M can greatly outperform the state-of-the-art methods in both quantitative metrics and qualitative evaluations. We have publicly released our code at href{https://github.com/Gloria2tt/T3M.git}{https://github.com/Gloria2tt/T3M.git}
Read more8/26/2024

0
MotionFix: Text-Driven 3D Human Motion Editing
Nikos Athanasiou, Alp'ar Ceske, Markos Diomataris, Michael J. Black, Gul Varol
The focus of this paper is 3D motion editing. Given a 3D human motion and a textual description of the desired modification, our goal is to generate an edited motion as described by the text. The challenges include the lack of training data and the design of a model that faithfully edits the source motion. In this paper, we address both these challenges. We build a methodology to semi-automatically collect a dataset of triplets in the form of (i) a source motion, (ii) a target motion, and (iii) an edit text, and create the new MotionFix dataset. Having access to such data allows us to train a conditional diffusion model, TMED, that takes both the source motion and the edit text as input. We further build various baselines trained only on text-motion pairs datasets, and show superior performance of our model trained on triplets. We introduce new retrieval-based metrics for motion editing and establish a new benchmark on the evaluation set of MotionFix. Our results are encouraging, paving the way for further research on finegrained motion generation. Code and models will be made publicly available.
Read more8/2/2024

0
Text-guided 3D Human Motion Generation with Keyframe-based Parallel Skip Transformer
Zichen Geng, Caren Han, Zeeshan Hayder, Jian Liu, Mubarak Shah, Ajmal Mian
Text-driven human motion generation is an emerging task in animation and humanoid robot design. Existing algorithms directly generate the full sequence which is computationally expensive and prone to errors as it does not pay special attention to key poses, a process that has been the cornerstone of animation for decades. We propose KeyMotion, that generates plausible human motion sequences corresponding to input text by first generating keyframes followed by in-filling. We use a Variational Autoencoder (VAE) with Kullback-Leibler regularization to project the keyframes into a latent space to reduce dimensionality and further accelerate the subsequent diffusion process. For the reverse diffusion, we propose a novel Parallel Skip Transformer that performs cross-modal attention between the keyframe latents and text condition. To complete the motion sequence, we propose a text-guided Transformer designed to perform motion-in-filling, ensuring the preservation of both fidelity and adherence to the physical constraints of human motion. Experiments show that our method achieves state-of-theart results on the HumanML3D dataset outperforming others on all R-precision metrics and MultiModal Distance. KeyMotion also achieves competitive performance on the KIT dataset, achieving the best results on Top3 R-precision, FID, and Diversity metrics.
Read more5/27/2024
🛸
0
Multi-Track Timeline Control for Text-Driven 3D Human Motion Generation
Mathis Petrovich, Or Litany, Umar Iqbal, Michael J. Black, Gul Varol, Xue Bin Peng, Davis Rempe
Recent advances in generative modeling have led to promising progress on synthesizing 3D human motion from text, with methods that can generate character animations from short prompts and specified durations. However, using a single text prompt as input lacks the fine-grained control needed by animators, such as composing multiple actions and defining precise durations for parts of the motion. To address this, we introduce the new problem of timeline control for text-driven motion synthesis, which provides an intuitive, yet fine-grained, input interface for users. Instead of a single prompt, users can specify a multi-track timeline of multiple prompts organized in temporal intervals that may overlap. This enables specifying the exact timings of each action and composing multiple actions in sequence or at overlapping intervals. To generate composite animations from a multi-track timeline, we propose a new test-time denoising method. This method can be integrated with any pre-trained motion diffusion model to synthesize realistic motions that accurately reflect the timeline. At every step of denoising, our method processes each timeline interval (text prompt) individually, subsequently aggregating the predictions with consideration for the specific body parts engaged in each action. Experimental comparisons and ablations validate that our method produces realistic motions that respect the semantics and timing of given text prompts. Our code and models are publicly available at https://mathis.petrovich.fr/stmc.
Read more5/27/2024