Textless Dependency Parsing by Labeled Sequence Prediction

0

Sign in to get full access
Overview
- This paper proposes a novel approach called "Wav2tree" for textless dependency parsing, which aims to perform syntactic analysis of speech without the need for transcripts.
- The key idea is to train a cascading model that can directly predict dependency tree structures from raw speech input, bypassing the need for intermediate text representations.
- This work builds on recent advancements in textless speech modeling and structured sentiment analysis, demonstrating how textless approaches can be extended to syntactic parsing.
Plain English Explanation
The researchers have developed a new system called "Wav2tree" that can analyze the grammatical structure of speech without first converting it to text. Traditional dependency parsing methods require transcripts of the spoken language, but this new approach can directly predict the syntactic tree structure from the raw audio signal.
The key insight is to build a cascading model that can learn to map speech directly to the tree-like representations used in dependency parsing. This skips the usual intermediate step of converting speech to text, which can introduce errors and relies on having accurate transcripts available.
By avoiding the need for text, this textless approach opens up new possibilities for speech analysis in scenarios where transcripts may be difficult or expensive to obtain, such as low-resource languages or spontaneous conversational speech. The researchers show that their Wav2tree model can achieve competitive performance on standard dependency parsing benchmarks, demonstrating the potential of this direct speech-to-syntax approach.
Technical Explanation
The paper introduces the "Wav2tree" model, which is a cascading neural network architecture for performing textless dependency parsing. The core idea is to train the model to directly predict the structured dependency tree representation from the raw speech audio, without the need for an intermediate text transcript.
The Wav2tree model consists of two main components:
- A speech encoder that processes the input audio waveform and produces contextualized speech representations.
- A tree decoder that takes these speech representations and predicts the corresponding dependency tree structure, including the labeled arcs between words.
The speech encoder is built upon recent advancements in unsupervised speech representation learning, utilizing self-supervised pre-training techniques to learn powerful audio features. The tree decoder then takes these speech features and applies a sequence-to-sequence modeling approach to generate the final dependency parse tree.
The researchers evaluate their Wav2tree model on several standard dependency parsing benchmarks, including datasets in both low-resource and high-resource languages. They demonstrate that the textless approach can achieve competitive performance compared to traditional text-based parsing methods, while avoiding the need for accurate speech transcripts.
Critical Analysis
The Wav2tree approach represents an interesting and promising step towards truly textless natural language processing, bypassing the reliance on intermediate text representations that has traditionally been a bottleneck. By directly mapping speech to syntactic structures, the model has the potential to be more robust to errors and noisy inputs that can occur in speech recognition.
However, the paper also acknowledges several limitations and areas for future work. For example, the current model is still constrained by the quality of the underlying speech representations, and may struggle with highly spontaneous or disfluent speech. Additionally, the training process requires access to speech data paired with gold-standard dependency trees, which may not be trivially available for all languages and domains.
Further research is needed to explore ways of reducing the reliance on annotated training data, potentially through self-supervised or weakly-supervised techniques. Integrating the Wav2tree approach with other textless capabilities, such as unsupervised speech recognition or text-free language modeling, could also lead to more powerful and versatile speech processing systems.
Conclusion
The Wav2tree model presented in this paper represents an important step towards truly textless natural language processing, demonstrating how syntactic analysis can be performed directly on raw speech input. By bypassing the need for accurate speech transcripts, this approach holds promise for applications in low-resource languages, spontaneous conversations, and other scenarios where text may be difficult or expensive to obtain.
While there are still challenges to overcome, the promising results on standard dependency parsing benchmarks suggest that the Wav2tree framework could serve as a foundation for further advancements in textless speech understanding. As research in this area continues to evolve, we may see increasingly capable and versatile speech processing systems that can operate without relying on intermediate text representations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Textless Dependency Parsing by Labeled Sequence Prediction
Shunsuke Kando, Yusuke Miyao, Jason Naradowsky, Shinnosuke Takamichi
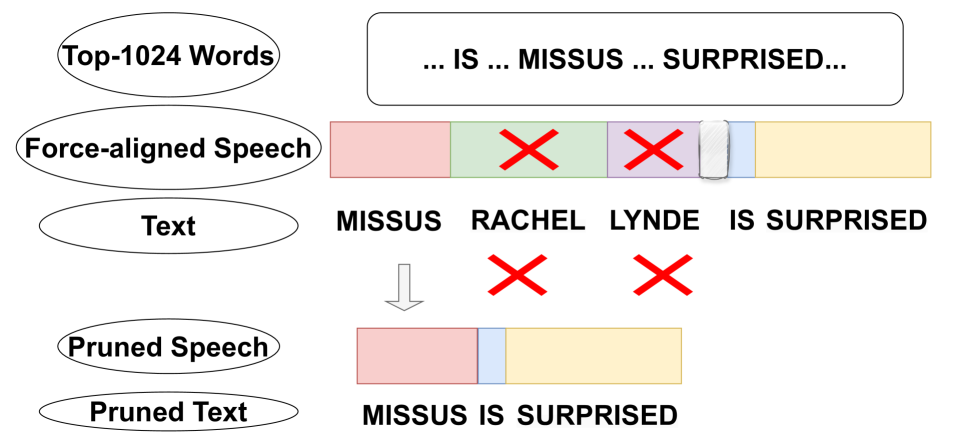
Traditional spoken language processing involves cascading an automatic speech recognition (ASR) system into text processing models. In contrast, textless methods process speech representations without ASR systems, enabling the direct use of acoustic speech features. Although their effectiveness is shown in capturing acoustic features, it is unclear in capturing lexical knowledge. This paper proposes a textless method for dependency parsing, examining its effectiveness and limitations. Our proposed method predicts a dependency tree from a speech signal without transcribing, representing the tree as a labeled sequence. scading method outperforms the textless method in overall parsing accuracy, the latter excels in instances with important acoustic features. Our findings highlight the importance of fusing word-level representations and sentence-level prosody for enhanced parsing performance. The code and models are made publicly available: https://github.com/mynlp/SpeechParser.
Read more7/16/2024

0
Growing Trees on Sounds: Assessing Strategies for End-to-End Dependency Parsing of Speech
Adrien Pupier, Maximin Coavoux, J'er^ome Goulian, Benjamin Lecouteux
Direct dependency parsing of the speech signal -- as opposed to parsing speech transcriptions -- has recently been proposed as a task (Pupier et al. 2022), as a way of incorporating prosodic information in the parsing system and bypassing the limitations of a pipeline approach that would consist of using first an Automatic Speech Recognition (ASR) system and then a syntactic parser. In this article, we report on a set of experiments aiming at assessing the performance of two parsing paradigms (graph-based parsing and sequence labeling based parsing) on speech parsing. We perform this evaluation on a large treebank of spoken French, featuring realistic spontaneous conversations. Our findings show that (i) the graph based approach obtain better results across the board (ii) parsing directly from speech outperforms a pipeline approach, despite having 30% fewer parameters.
Read more6/19/2024
🗣️
0
Analyzing Speech Unit Selection for Textless Speech-to-Speech Translation
Jarod Duret (LIA), Yannick Est`eve (LIA), Titouan Parcollet (CAM)
Recent advancements in textless speech-to-speech translation systems have been driven by the adoption of self-supervised learning techniques. Although most state-of-the-art systems adopt a similar architecture to transform source language speech into sequences of discrete representations in the target language, the criteria for selecting these target speech units remains an open question. This work explores the selection process through a study of downstream tasks such as automatic speech recognition, speech synthesis, speaker recognition, and emotion recognition. Interestingly, our findings reveal a discrepancy in the optimization of discrete speech units: units that perform well in resynthesis performance do not necessarily correlate with those that enhance translation efficacy. This discrepancy underscores the nuanced complexity of target feature selection and its impact on the overall performance of speech-to-speech translation systems.
Read more7/29/2024
0
Towards Unsupervised Speech Recognition Without Pronunciation Models
Junrui Ni, Liming Wang, Yang Zhang, Kaizhi Qian, Heting Gao, Mark Hasegawa-Johnson, Chang D. Yoo
Recent advancements in supervised automatic speech recognition (ASR) have achieved remarkable performance, largely due to the growing availability of large transcribed speech corpora. However, most languages lack sufficient paired speech and text data to effectively train these systems. In this article, we tackle the challenge of developing ASR systems without paired speech and text corpora by proposing the removal of reliance on a phoneme lexicon. We explore a new research direction: word-level unsupervised ASR. Using a curated speech corpus containing only high-frequency English words, our system achieves a word error rate of nearly 20% without parallel transcripts or oracle word boundaries. Furthermore, we experimentally demonstrate that an unsupervised speech recognizer can emerge from joint speech-to-speech and text-to-text masked token-infilling. This innovative model surpasses the performance of previous unsupervised ASR models trained with direct distribution matching.
Read more6/13/2024