Texture-aware and Shape-guided Transformer for Sequential DeepFake Detection

0

Sign in to get full access
Overview
- Proposes a novel Transformer-based model for sequential DeepFake detection that leverages both texture and shape information
- Introduces a Shape-Guided Attention module to capture high-level shape features and a Texture-Aware Attention module to focus on low-level texture details
- Demonstrates improved performance over state-of-the-art DeepFake detection methods on multiple benchmark datasets
Plain English Explanation
This research paper presents a new deep learning model for detecting DeepFake videos, which are manipulated videos that aim to deceive viewers by making it appear that someone said or did something they did not. The model uses a Transformer architecture, a type of deep neural network that is particularly good at processing sequential data like videos.
The key innovation of this model is that it pays attention to both the texture (fine-grain details) and the shape (high-level structure) of the faces in the video. It has two specialized attention modules - one that focuses on texture information and one that focuses on shape information. This allows the model to capture a more comprehensive set of visual cues to distinguish real videos from DeepFakes.
The Texture-Aware and Shape-Guided Transformer for Sequential DeepFake Detection model was tested on several standard DeepFake detection benchmark datasets and was found to outperform other state-of-the-art approaches. This suggests that incorporating both texture and shape information can lead to more accurate and robust DeepFake detection.
Technical Explanation
The proposed model, called Texture-aware and Shape-guided Transformer for Sequential DeepFake Detection, uses a Transformer architecture to process video frames sequentially. It has two key components:
-
Shape-Guided Attention Module: This module extracts high-level shape features from the input faces using a convolutional neural network. It then uses attention mechanisms to selectively focus on the most informative shape features for DeepFake detection.
-
Texture-Aware Attention Module: This module extracts low-level texture details from the input faces using another convolutional network. It then uses attention to highlight the most discriminative texture features.
The outputs of these two attention modules are combined and passed through additional Transformer layers to make the final DeepFake classification. This design allows the model to capture both fine-grained texture information and coarse-grained shape information, which the authors show is crucial for accurate DeepFake detection.
The model is evaluated on several popular DeepFake detection benchmarks, including FaceForensics++, Celeb-DF, and WildDeepfake. The results demonstrate that the Texture-aware and Shape-guided Transformer outperforms other state-of-the-art DeepFake detection methods, highlighting the importance of modeling both texture and shape information for this task.
Critical Analysis
The authors acknowledge several limitations of their work:
- The model's performance may degrade on DeepFake videos generated by unseen methods, as it is trained on a finite set of DeepFake datasets.
- The computational complexity of the Transformer architecture could limit the real-time deployment of the model on resource-constrained devices.
- The model's interpretability is not fully explored, making it difficult to understand the specific texture and shape features it uses for DeepFake detection.
Additionally, the paper does not provide a thorough analysis of the relative contributions of the Texture-Aware and Shape-Guided Attention modules. It would be valuable to understand how much each component contributes to the overall performance, as this could inform future model design choices.
Conclusion
The Texture-aware and Shape-guided Transformer for Sequential DeepFake Detection model presents a novel approach to DeepFake detection that leverages both low-level texture information and high-level shape features. By combining these complementary visual cues, the model achieves state-of-the-art performance on several benchmark datasets.
This research highlights the importance of developing robust and comprehensive DeepFake detection methods, as the proliferation of manipulated media poses significant risks to individual privacy, political discourse, and societal trust. The authors' work advances the field by demonstrating the value of a multi-faceted approach to this challenging problem.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Texture-aware and Shape-guided Transformer for Sequential DeepFake Detection
Yunfei Li, Yuezun Li, Xin Wang, Jiaran Zhou, Junyu Dong
Sequential DeepFake detection is an emerging task that aims to predict the manipulation sequence in order. Existing methods typically formulate it as an image-to-sequence problem, employing conventional Transformer architectures for detection. However, these methods lack dedicated design and consequently result in limited performance. In this paper, we propose a novel Texture-aware and Shape-guided Transformer to enhance detection performance. Our method features four major improvements. Firstly, we describe a texture-aware branch that effectively captures subtle manipulation traces with the Diversiform Pixel Difference Attention module. Then we introduce a Bidirectional Interaction Cross-attention module that seeks deep correlations among spatial and sequential features, enabling effective modeling of complex manipulation traces. To further enhance the cross-attention, we describe a Shape-guided Gaussian mapping strategy, providing initial priors of the manipulation shape. Finally, observing that the latter manipulation in a sequence may influence traces left in the earlier one, we intriguingly invert the prediction order from forward to backward, leading to notable gains as expected. Extensive experimental results demonstrate that our method outperforms others by a large margin, highlighting the superiority of our method.
Read more5/7/2024
🔮
0
Tex-ViT: A Generalizable, Robust, Texture-based dual-branch cross-attention deepfake detector
Deepak Dagar, Dinesh Kumar Vishwakarma
Deepfakes, which employ GAN to produce highly realistic facial modification, are widely regarded as the prevailing method. Traditional CNN have been able to identify bogus media, but they struggle to perform well on different datasets and are vulnerable to adversarial attacks due to their lack of robustness. Vision transformers have demonstrated potential in the realm of image classification problems, but they require enough training data. Motivated by these limitations, this publication introduces Tex-ViT (Texture-Vision Transformer), which enhances CNN features by combining ResNet with a vision transformer. The model combines traditional ResNet features with a texture module that operates in parallel on sections of ResNet before each down-sampling operation. The texture module then serves as an input to the dual branch of the cross-attention vision transformer. It specifically focuses on improving the global texture module, which extracts feature map correlation. Empirical analysis reveals that fake images exhibit smooth textures that do not remain consistent over long distances in manipulations. Experiments were performed on different categories of FF++, such as DF, f2f, FS, and NT, together with other types of GAN datasets in cross-domain scenarios. Furthermore, experiments also conducted on FF++, DFDCPreview, and Celeb-DF dataset underwent several post-processing situations, such as blurring, compression, and noise. The model surpassed the most advanced models in terms of generalization, achieving a 98% accuracy in cross-domain scenarios. This demonstrates its ability to learn the shared distinguishing textural characteristics in the manipulated samples. These experiments provide evidence that the proposed model is capable of being applied to various situations and is resistant to many post-processing procedures.
Read more9/2/2024
👀
0
A Timely Survey on Vision Transformer for Deepfake Detection
Zhikan Wang, Zhongyao Cheng, Jiajie Xiong, Xun Xu, Tianrui Li, Bharadwaj Veeravalli, Xulei Yang
In recent years, the rapid advancement of deepfake technology has revolutionized content creation, lowering forgery costs while elevating quality. However, this progress brings forth pressing concerns such as infringements on individual rights, national security threats, and risks to public safety. To counter these challenges, various detection methodologies have emerged, with Vision Transformer (ViT)-based approaches showcasing superior performance in generality and efficiency. This survey presents a timely overview of ViT-based deepfake detection models, categorized into standalone, sequential, and parallel architectures. Furthermore, it succinctly delineates the structure and characteristics of each model. By analyzing existing research and addressing future directions, this survey aims to equip researchers with a nuanced understanding of ViT's pivotal role in deepfake detection, serving as a valuable reference for both academic and practical pursuits in this domain.
Read more5/15/2024
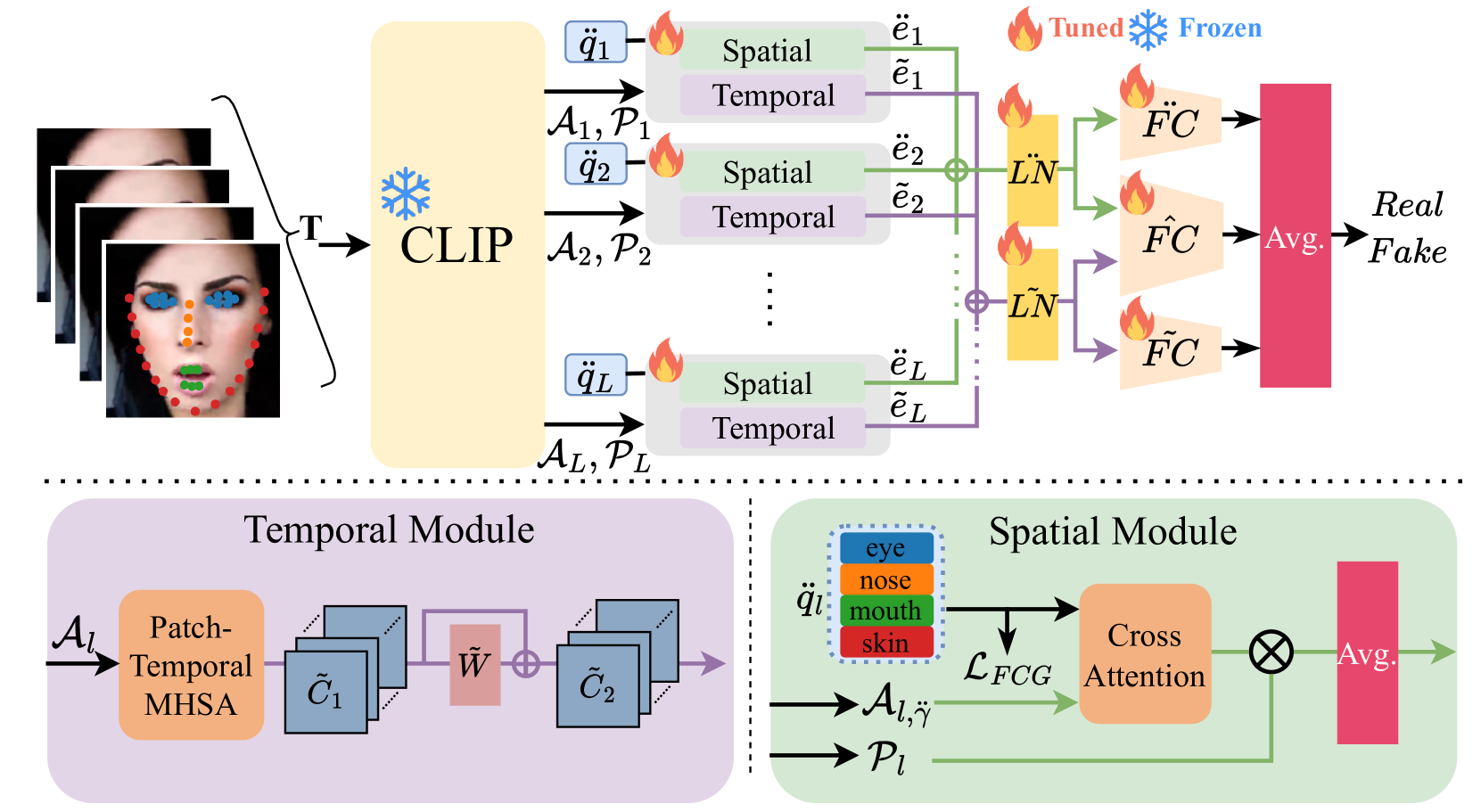
0
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to encourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvement even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especially a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
Read more6/6/2024