Tex-ViT: A Generalizable, Robust, Texture-based dual-branch cross-attention deepfake detector

0
🔮
Sign in to get full access
Overview
- Deepfakes, which use Generative Adversarial Networks (GANs) to create highly realistic facial modifications, are a major concern.
- Traditional Convolutional Neural Networks (CNNs) can identify fake media, but struggle with different datasets and are vulnerable to adversarial attacks due to lack of robustness.
- Vision Transformers have shown promise for image classification, but require significant training data.
- This paper introduces Tex-ViT (Texture-Vision Transformer), which combines CNN features from ResNet with a Texture module and Vision Transformer to enhance deepfake detection.
Plain English Explanation
The paper presents a new Tex-ViT (Texture-Vision Transformer) model for detecting deepfake images. Deepfakes use advanced AI to realistically manipulate faces in photos and videos, which is a growing problem.
Traditional Convolutional Neural Networks (CNNs) can detect some deepfakes, but they struggle when the fakes are shown in different datasets or when the fakes try to actively avoid detection (adversarial attacks). Vision Transformers have shown promise for image classification, but they require a lot of training data.
The Tex-ViT model combines the strengths of CNNs and Vision Transformers. It takes CNN features from a ResNet model and adds a "Texture module" that focuses on analyzing the visual textures in the images. This texture information is then fed into a Vision Transformer, which can learn higher-level patterns to detect deepfakes.
The key insight is that manipulated images often have smooth, inconsistent textures compared to real images. By explicitly modeling these textural cues, the Tex-ViT model can detect deepfakes more accurately, even when they are disguised or shown in new datasets.
Technical Explanation
The Tex-ViT model builds on a standard ResNet CNN backbone, adding a parallel "Texture module" that operates on sections of the ResNet feature maps before each downsampling operation.
This Texture module extracts correlation information from the feature maps, capturing the global textural patterns in the image. The Texture module's output is then combined with the ResNet features and fed into a Vision Transformer, which can learn high-level representations to distinguish real from fake images.
The researchers evaluated Tex-ViT on various deepfake datasets, including FF++, DFDCPreview, and Celeb-DF. They also tested the model's robustness to common post-processing techniques like blurring, compression, and noise.
The results showed that Tex-ViT outperformed state-of-the-art deepfake detectors, achieving over 98% accuracy in cross-domain scenarios. This indicates that the model is able to effectively learn the distinctive textural patterns that distinguish real and manipulated images, even when the fakes are modified or shown in new datasets.
Critical Analysis
The paper provides a compelling approach to deepfake detection by leveraging the complementary strengths of CNNs and Vision Transformers. The focus on modeling global textural cues is a novel and promising direction, as prior work has often relied more on local facial features.
That said, the paper does not provide much insight into the limitations or failure cases of the Tex-ViT model. It would be helpful to understand scenarios where the model struggles, such as highly advanced deepfakes or when the fakes are created using techniques that specifically target textural inconsistencies.
Additionally, the paper does not discuss the computational efficiency or real-world deployment considerations of the Tex-ViT approach. As deepfake detection needs to run on a variety of hardware, understanding the trade-offs between accuracy and inference speed would be valuable.
Overall, the Tex-ViT model represents an interesting and effective step forward in deepfake detection research. However, further analysis of its limitations and practical feasibility would help provide a more comprehensive understanding of its strengths and weaknesses.
Conclusion
This paper introduces the Tex-ViT model, which combines CNN features with a dedicated Texture module and Vision Transformer to enhance deepfake detection. By explicitly modeling the global textural patterns in images, Tex-ViT achieves state-of-the-art performance, even in cross-domain and post-processing scenarios.
The key innovation is the Texture module, which captures the correlation between feature map sections to identify the inconsistent textures that often characterize manipulated images. This textural information is then used to train a Vision Transformer, which can learn high-level representations to distinguish real from fake media.
The results demonstrate the power of combining complementary computer vision techniques to tackle the evolving challenge of deepfake detection. As AI-generated fakes continue to advance, approaches like Tex-ViT will be crucial for developing robust, generalizable detection systems to protect against this emerging threat.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Tex-ViT: A Generalizable, Robust, Texture-based dual-branch cross-attention deepfake detector
Deepak Dagar, Dinesh Kumar Vishwakarma
Deepfakes, which employ GAN to produce highly realistic facial modification, are widely regarded as the prevailing method. Traditional CNN have been able to identify bogus media, but they struggle to perform well on different datasets and are vulnerable to adversarial attacks due to their lack of robustness. Vision transformers have demonstrated potential in the realm of image classification problems, but they require enough training data. Motivated by these limitations, this publication introduces Tex-ViT (Texture-Vision Transformer), which enhances CNN features by combining ResNet with a vision transformer. The model combines traditional ResNet features with a texture module that operates in parallel on sections of ResNet before each down-sampling operation. The texture module then serves as an input to the dual branch of the cross-attention vision transformer. It specifically focuses on improving the global texture module, which extracts feature map correlation. Empirical analysis reveals that fake images exhibit smooth textures that do not remain consistent over long distances in manipulations. Experiments were performed on different categories of FF++, such as DF, f2f, FS, and NT, together with other types of GAN datasets in cross-domain scenarios. Furthermore, experiments also conducted on FF++, DFDCPreview, and Celeb-DF dataset underwent several post-processing situations, such as blurring, compression, and noise. The model surpassed the most advanced models in terms of generalization, achieving a 98% accuracy in cross-domain scenarios. This demonstrates its ability to learn the shared distinguishing textural characteristics in the manipulated samples. These experiments provide evidence that the proposed model is capable of being applied to various situations and is resistant to many post-processing procedures.
Read more9/2/2024
0
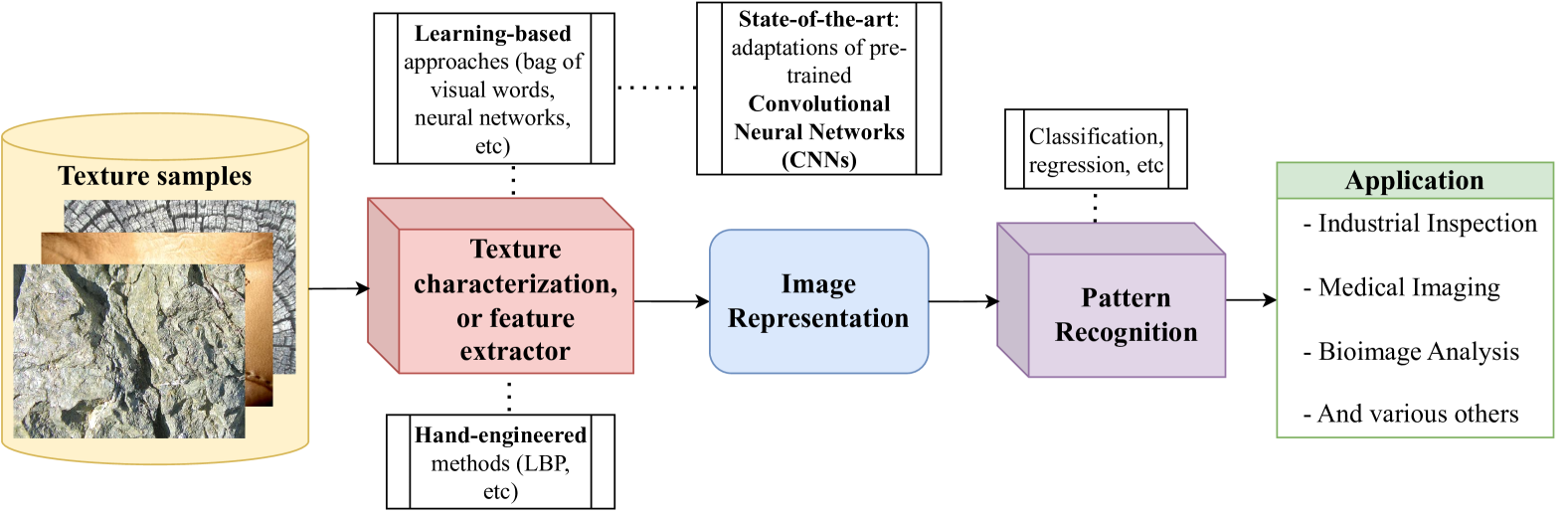
A Comparative Survey of Vision Transformers for Feature Extraction in Texture Analysis
Leonardo Scabini, Andre Sacilotti, Kallil M. Zielinski, Lucas C. Ribas, Bernard De Baets, Odemir M. Bruno
Texture, a significant visual attribute in images, has been extensively investigated across various image recognition applications. Convolutional Neural Networks (CNNs), which have been successful in many computer vision tasks, are currently among the best texture analysis approaches. On the other hand, Vision Transformers (ViTs) have been surpassing the performance of CNNs on tasks such as object recognition, causing a paradigm shift in the field. However, ViTs have so far not been scrutinized for texture recognition, hindering a proper appreciation of their potential in this specific setting. For this reason, this work explores various pre-trained ViT architectures when transferred to tasks that rely on textures. We review 21 different ViT variants and perform an extensive evaluation and comparison with CNNs and hand-engineered models on several tasks, such as assessing robustness to changes in texture rotation, scale, and illumination, and distinguishing color textures, material textures, and texture attributes. The goal is to understand the potential and differences among these models when directly applied to texture recognition, using pre-trained ViTs primarily for feature extraction and employing linear classifiers for evaluation. We also evaluate their efficiency, which is one of the main drawbacks in contrast to other methods. Our results show that ViTs generally outperform both CNNs and hand-engineered models, especially when using stronger pre-training and tasks involving in-the-wild textures (images from the internet). We highlight the following promising models: ViT-B with DINO pre-training, BeiTv2, and the Swin architecture, as well as the EfficientFormer as a low-cost alternative. In terms of efficiency, although having a higher number of GFLOPs and parameters, ViT-B and BeiT(v2) can achieve a lower feature extraction time on GPUs compared to ResNet50.
Read more6/11/2024
🔎
0
Generalized Face Forgery Detection via Adaptive Learning for Pre-trained Vision Transformer
Anwei Luo, Rizhao Cai, Chenqi Kong, Yakun Ju, Xiangui Kang, Jiwu Huang, Alex C. Kot
With the rapid progress of generative models, the current challenge in face forgery detection is how to effectively detect realistic manipulated faces from different unseen domains. Though previous studies show that pre-trained Vision Transformer (ViT) based models can achieve some promising results after fully fine-tuning on the Deepfake dataset, their generalization performances are still unsatisfactory. One possible reason is that fully fine-tuned ViT-based models may disrupt the pre-trained features [1, 2] and overfit to some data-specific patterns [3]. To alleviate this issue, we present a textbf{F}orgery-aware textbf{A}daptive textbf{Vi}sion textbf{T}ransformer (FA-ViT) under the adaptive learning paradigm, where the parameters in the pre-trained ViT are kept fixed while the designed adaptive modules are optimized to capture forgery features. Specifically, a global adaptive module is designed to model long-range interactions among input tokens, which takes advantage of self-attention mechanism to mine global forgery clues. To further explore essential local forgery clues, a local adaptive module is proposed to expose local inconsistencies by enhancing the local contextual association. In addition, we introduce a fine-grained adaptive learning module that emphasizes the common compact representation of genuine faces through relationship learning in fine-grained pairs, driving these proposed adaptive modules to be aware of fine-grained forgery-aware information. Extensive experiments demonstrate that our FA-ViT achieves state-of-the-arts results in the cross-dataset evaluation, and enhances the robustness against unseen perturbations. Particularly, FA-ViT achieves 93.83% and 78.32% AUC scores on Celeb-DF and DFDC datasets in the cross-dataset evaluation. The code and trained model have been released at: https://github.com/LoveSiameseCat/FAViT.
Read more8/23/2024
👀
0
A Timely Survey on Vision Transformer for Deepfake Detection
Zhikan Wang, Zhongyao Cheng, Jiajie Xiong, Xun Xu, Tianrui Li, Bharadwaj Veeravalli, Xulei Yang
In recent years, the rapid advancement of deepfake technology has revolutionized content creation, lowering forgery costs while elevating quality. However, this progress brings forth pressing concerns such as infringements on individual rights, national security threats, and risks to public safety. To counter these challenges, various detection methodologies have emerged, with Vision Transformer (ViT)-based approaches showcasing superior performance in generality and efficiency. This survey presents a timely overview of ViT-based deepfake detection models, categorized into standalone, sequential, and parallel architectures. Furthermore, it succinctly delineates the structure and characteristics of each model. By analyzing existing research and addressing future directions, this survey aims to equip researchers with a nuanced understanding of ViT's pivotal role in deepfake detection, serving as a valuable reference for both academic and practical pursuits in this domain.
Read more5/15/2024