TF-Attack: Transferable and Fast Adversarial Attacks on Large Language Models

0

Sign in to get full access
Overview
- TF-Attack is a new method for conducting fast and transferable adversarial attacks on large language models.
- Adversarial attacks aim to fool AI models by making small, imperceptible changes to input data that cause the model to produce incorrect outputs.
- TF-Attack is designed to be more efficient and effective than existing adversarial attack methods.
Plain English Explanation
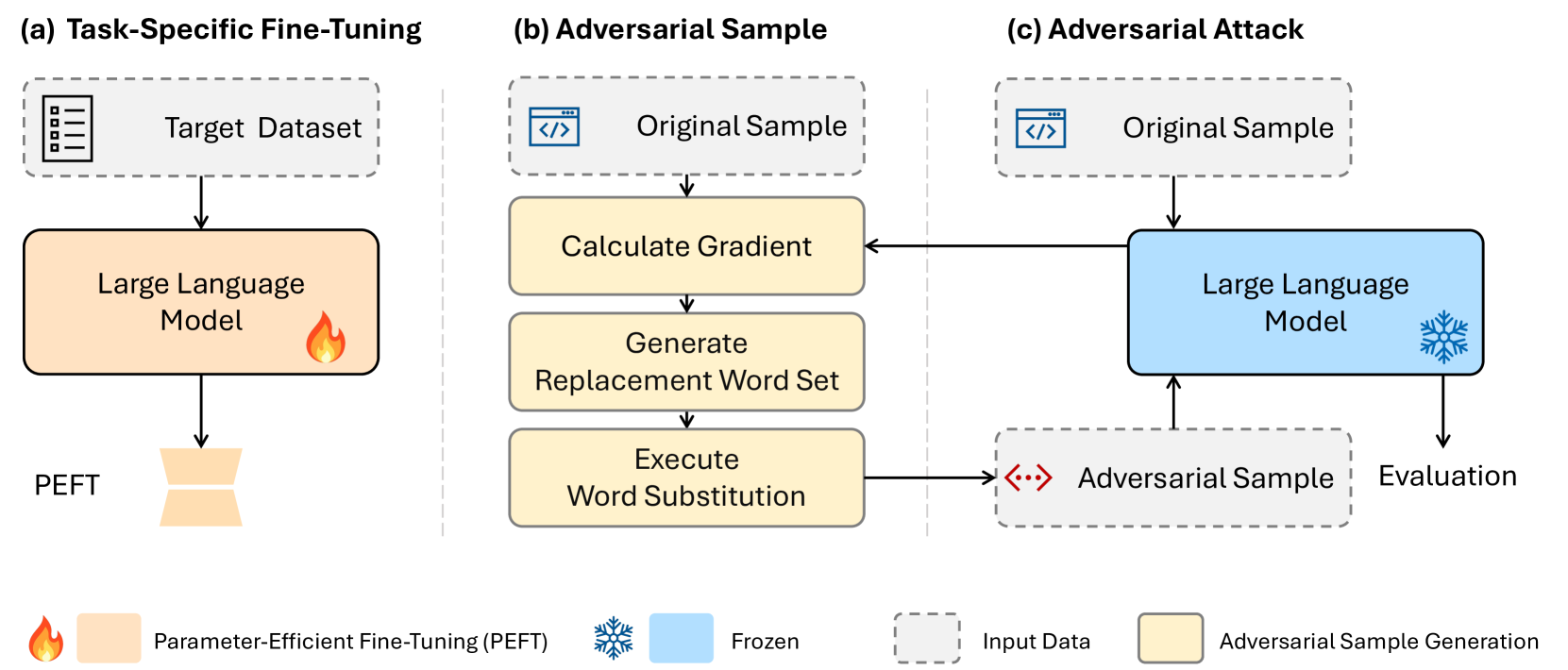
TF-Attack: Transferable and Fast Adversarial Attacks on Large Language Models introduces a new technique called TF-Attack for conducting adversarial attacks on large language models. Adversarial attacks are a way of tricking AI systems by making tiny, almost unnoticeable changes to input data that cause the model to output incorrect or nonsensical results. The key innovation of TF-Attack is that it is designed to be both fast and transferable, meaning the adversarial examples it generates can fool multiple different language models, not just the one it was trained on.
This is important because it makes adversarial attacks more scalable and dangerous - if an attacker can create one set of adversarial examples that work across many different AI models, they can more easily exploit vulnerabilities in a wide range of real-world AI systems. The researchers show that TF-Attack outperforms previous state-of-the-art adversarial attack methods in terms of both attack success rate and computational efficiency.
Technical Explanation
The researchers behind TF-Attack propose a new algorithm for generating transferable adversarial examples that can fool multiple different large language models. Their key insight is that by optimizing the adversarial perturbations to maximize the model's uncertainty, rather than just its prediction error, they can create adversarial examples that transfer more effectively across models.
They evaluate TF-Attack on a variety of language tasks and models, including sentiment analysis, question answering, and text generation. The results show that TF-Attack can achieve high attack success rates while being significantly faster and more computationally efficient than previous methods.
One of the main innovations of TF-Attack is its use of a "meta-gradient" approach, which allows the model to learn how to generate adversarial perturbations that are tailored to maximize transferability. This is in contrast to previous techniques that optimized perturbations for a single target model.
The paper also includes an analysis of the types of linguistic features that make text more or less vulnerable to TF-Attack, providing insights into the weaknesses of current language models.
Critical Analysis
The TF-Attack paper makes a valuable contribution to the field of adversarial machine learning by introducing a new, more efficient and transferable attack method. However, it's important to note that the authors themselves acknowledge several limitations and caveats to their work.
For one, the experiments are conducted on a relatively limited set of language tasks and models, so it's unclear how well TF-Attack would generalize to a wider range of real-world applications. There's also the concern that by making adversarial attacks more scalable and transferable, the paper could inadvertently empower bad actors to more easily exploit vulnerabilities in AI systems.
Additionally, the paper does not address potential defenses or mitigation strategies against TF-Attack. As the authors point out, developing robust countermeasures is an important area for future research.
Overall, while TF-Attack represents an interesting advance in adversarial attack techniques, it's crucial that the research community continues to explore ways of enhancing the security and reliability of large language models in the face of such threats.
Conclusion
TF-Attack is a new method for conducting fast and transferable adversarial attacks on large language models. By optimizing perturbations to maximize model uncertainty rather than just prediction error, the technique can generate adversarial examples that are effective across a range of different language AI systems.
While this work advances the state of the art in adversarial machine learning, it also highlights the ongoing challenges in developing robust and secure AI systems. As large language models become more widely deployed, it will be critical to continue researching both offensive and defensive techniques to ensure these powerful technologies are used responsibly and for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TF-Attack: Transferable and Fast Adversarial Attacks on Large Language Models
Zelin Li, Kehai Chen, Lemao Liu, Xuefeng Bai, Mingming Yang, Yang Xiang, Min Zhang
With the great advancements in large language models (LLMs), adversarial attacks against LLMs have recently attracted increasing attention. We found that pre-existing adversarial attack methodologies exhibit limited transferability and are notably inefficient, particularly when applied to LLMs. In this paper, we analyze the core mechanisms of previous predominant adversarial attack methods, revealing that 1) the distributions of importance score differ markedly among victim models, restricting the transferability; 2) the sequential attack processes induces substantial time overheads. Based on the above two insights, we introduce a new scheme, named TF-Attack, for Transferable and Fast adversarial attacks on LLMs. TF-Attack employs an external LLM as a third-party overseer rather than the victim model to identify critical units within sentences. Moreover, TF-Attack introduces the concept of Importance Level, which allows for parallel substitutions of attacks. We conduct extensive experiments on 6 widely adopted benchmarks, evaluating the proposed method through both automatic and human metrics. Results show that our method consistently surpasses previous methods in transferability and delivers significant speed improvements, up to 20 times faster than earlier attack strategies.
Read more9/10/2024

0
Typography Leads Semantic Diversifying: Amplifying Adversarial Transferability across Multimodal Large Language Models
Hao Cheng, Erjia Xiao, Jiahang Cao, Le Yang, Kaidi Xu, Jindong Gu, Renjing Xu
Following the advent of the Artificial Intelligence (AI) era of large models, Multimodal Large Language Models (MLLMs) with the ability to understand cross-modal interactions between vision and text have attracted wide attention. Adversarial examples with human-imperceptible perturbation are shown to possess a characteristic known as transferability, which means that a perturbation generated by one model could also mislead another different model. Augmenting the diversity in input data is one of the most significant methods for enhancing adversarial transferability. This method has been certified as a way to significantly enlarge the threat impact under black-box conditions. Research works also demonstrate that MLLMs can be exploited to generate adversarial examples in the white-box scenario. However, the adversarial transferability of such perturbations is quite limited, failing to achieve effective black-box attacks across different models. In this paper, we propose the Typographic-based Semantic Transfer Attack (TSTA), which is inspired by: (1) MLLMs tend to process semantic-level information; (2) Typographic Attack could effectively distract the visual information captured by MLLMs. In the scenarios of Harmful Word Insertion and Important Information Protection, our TSTA demonstrates superior performance.
Read more5/31/2024
0
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
Read more9/16/2024
💬
0
Adversarial Evasion Attack Efficiency against Large Language Models
Jo~ao Vitorino, Eva Maia, Isabel Prac{c}a
Large Language Models (LLMs) are valuable for text classification, but their vulnerabilities must not be disregarded. They lack robustness against adversarial examples, so it is pertinent to understand the impacts of different types of perturbations, and assess if those attacks could be replicated by common users with a small amount of perturbations and a small number of queries to a deployed LLM. This work presents an analysis of the effectiveness, efficiency, and practicality of three different types of adversarial attacks against five different LLMs in a sentiment classification task. The obtained results demonstrated the very distinct impacts of the word-level and character-level attacks. The word attacks were more effective, but the character and more constrained attacks were more practical and required a reduced number of perturbations and queries. These differences need to be considered during the development of adversarial defense strategies to train more robust LLMs for intelligent text classification applications.
Read more6/13/2024