TG-LLaVA: Text Guided LLaVA via Learnable Latent Embeddings

0

Sign in to get full access
Overview
- This paper introduces TG-LLaVA, a text-guided latent diffusion model for generating visual content based on text prompts.
- The key innovation is the use of learnable latent embeddings to bridge the gap between text and visual representations.
- The model achieves strong performance on various vision-language benchmarks.
Plain English Explanation
The TG-LLaVA paper presents a new way to generate images from text descriptions. Traditional approaches often struggle to fully capture the connection between language and visuals.
TG-LLaVA tackles this by using "learnable latent embeddings" - essentially, it learns a shared representation that can translate between text and visual concepts. This allows the model to better understand the relationship between the words in a prompt and the visual elements it should generate.
The result is a system that can create images that are more closely aligned with the intent behind the text description. This could be useful for applications like image editing, creative content generation, or even improving the performance of vision-language models.
Technical Explanation
The key technical innovation in TG-LLaVA is the use of learnable latent embeddings to bridge the gap between text and visual representations.
The model consists of a text encoder that converts the input prompt into a latent text embedding, and a latent diffusion module that generates visual content from this latent representation. Crucially, the latent space is designed to be shared between the text and visual domains, allowing the model to learn associations between language and visual concepts.
This shared latent space is achieved through a novel "cross-attention" mechanism that aligns the text and visual embeddings during training. The authors demonstrate that this approach leads to significant performance gains on various vision-language benchmarks compared to previous methods.
Critical Analysis
The TG-LLaVA paper presents a promising step towards more coherent and semantically-grounded text-to-image generation. The use of learnable latent embeddings to bridge the text-visual gap is a thoughtful and well-executed innovation.
However, the paper does not address some potential limitations of the approach. For example, it is unclear how the model would perform on more complex, compositional prompts that require a deeper understanding of scene structure and object relationships. Additionally, the paper does not explore the model's robustness to out-of-domain or adversarial inputs.
Further research could also investigate the interpretability of the learned latent representations and how they capture the semantics of language and visual concepts. Examining failure cases and potential biases in the generated outputs would also be valuable.
Conclusion
The TG-LLaVA paper introduces an effective approach for text-guided image generation that leverages learnable latent embeddings to better align language and visual representations. This work represents an important advancement in the field of vision-language models and could have valuable applications in areas like creative content generation and image editing. While the paper demonstrates strong results, further research is needed to fully understand the model's capabilities and limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!TG-LLaVA: Text Guided LLaVA via Learnable Latent Embeddings
Dawei Yan, Pengcheng Li, Yang Li, Hao Chen, Qingguo Chen, Weihua Luo, Wei Dong, Qingsen Yan, Haokui Zhang, Chunhua Shen
Currently, inspired by the success of vision-language models (VLMs), an increasing number of researchers are focusing on improving VLMs and have achieved promising results. However, most existing methods concentrate on optimizing the connector and enhancing the language model component, while neglecting improvements to the vision encoder itself. In contrast, we propose Text Guided LLaVA (TG-LLaVA) in this paper, which optimizes VLMs by guiding the vision encoder with text, offering a new and orthogonal optimization direction. Specifically, inspired by the purpose-driven logic inherent in human behavior, we use learnable latent embeddings as a bridge to analyze textual instruction and add the analysis results to the vision encoder as guidance, refining it. Subsequently, another set of latent embeddings extracts additional detailed text-guided information from high-resolution local patches as auxiliary information. Finally, with the guidance of text, the vision encoder can extract text-related features, similar to how humans focus on the most relevant parts of an image when considering a question. This results in generating better answers. Experiments on various datasets validate the effectiveness of the proposed method. Remarkably, without the need for additional training data, our propsoed method can bring more benefits to the baseline (LLaVA-1.5) compared with other concurrent methods. Furthermore, the proposed method consistently brings improvement in different settings.
Read more9/17/2024

0
LLaVA-Read: Enhancing Reading Ability of Multimodal Language Models
Ruiyi Zhang, Yufan Zhou, Jian Chen, Jiuxiang Gu, Changyou Chen, Tong Sun
Large multimodal language models have demonstrated impressive capabilities in understanding and manipulating images. However, many of these models struggle with comprehending intensive textual contents embedded within the images, primarily due to the limited text recognition and layout understanding ability. To understand the sources of these limitations, we perform an exploratory analysis showing the drawbacks of classical visual encoders on visual text understanding. Hence, we present LLaVA-Read, a multimodal large language model that utilizes dual visual encoders along with a visual text encoder. Our model surpasses existing state-of-the-art models in various text-rich image understanding tasks, showcasing enhanced comprehension of textual content within images. Together, our research suggests visual text understanding remains an open challenge and an efficient visual text encoder is crucial for future successful multimodal systems.
Read more7/30/2024

0
MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
Xiangyu Zhao, Xiangtai Li, Haodong Duan, Haian Huang, Yining Li, Kai Chen, Hua Yang
Multi-modal large language models (MLLMs) have made significant strides in various visual understanding tasks. However, the majority of these models are constrained to process low-resolution images, which limits their effectiveness in perception tasks that necessitate detailed visual information. In our study, we present MG-LLaVA, an innovative MLLM that enhances the model's visual processing capabilities by incorporating a multi-granularity vision flow, which includes low-resolution, high-resolution, and object-centric features. We propose the integration of an additional high-resolution visual encoder to capture fine-grained details, which are then fused with base visual features through a Conv-Gate fusion network. To further refine the model's object recognition abilities, we incorporate object-level features derived from bounding boxes identified by offline detectors. Being trained solely on publicly available multimodal data through instruction tuning, MG-LLaVA demonstrates exceptional perception skills. We instantiate MG-LLaVA with a wide variety of language encoders, ranging from 3.8B to 34B, to evaluate the model's performance comprehensively. Extensive evaluations across multiple benchmarks demonstrate that MG-LLaVA outperforms existing MLLMs of comparable parameter sizes, showcasing its remarkable efficacy. The code will be available at https://github.com/PhoenixZ810/MG-LLaVA.
Read more6/28/2024
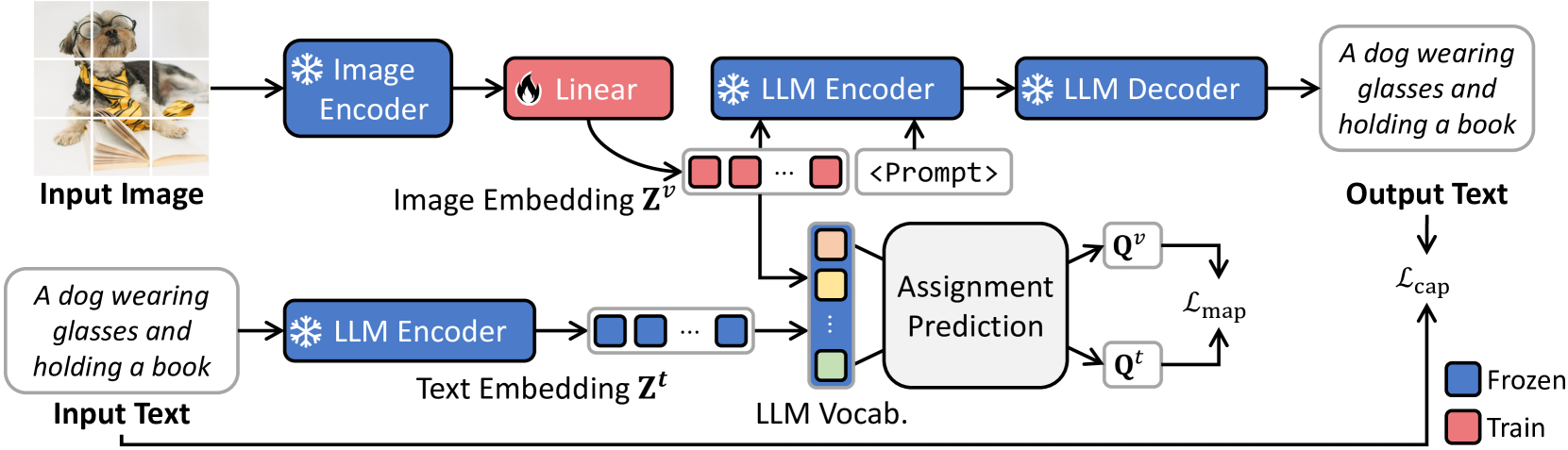
0
Bridging Vision and Language Spaces with Assignment Prediction
Jungin Park, Jiyoung Lee, Kwanghoon Sohn
This paper introduces VLAP, a novel approach that bridges pretrained vision models and large language models (LLMs) to make frozen LLMs understand the visual world. VLAP transforms the embedding space of pretrained vision models into the LLMs' word embedding space using a single linear layer for efficient and general-purpose visual and language understanding. Specifically, we harness well-established word embeddings to bridge two modality embedding spaces. The visual and text representations are simultaneously assigned to a set of word embeddings within pretrained LLMs by formulating the assigning procedure as an optimal transport problem. We predict the assignment of one modality from the representation of another modality data, enforcing consistent assignments for paired multimodal data. This allows vision and language representations to contain the same information, grounding the frozen LLMs' word embedding space in visual data. Moreover, a robust semantic taxonomy of LLMs can be preserved with visual data since the LLMs interpret and reason linguistic information from correlations between word embeddings. Experimental results show that VLAP achieves substantial improvements over the previous linear transformation-based approaches across a range of vision-language tasks, including image captioning, visual question answering, and cross-modal retrieval. We also demonstrate the learned visual representations hold a semantic taxonomy of LLMs, making visual semantic arithmetic possible.
Read more4/16/2024