TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
2404.18919
0
1
🖼️
Abstract
Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a Screenwriter, engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the Rehearsal. Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the Final Performance. With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
Create account to get full access
Overview
- This paper introduces TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to enable multi-turn image generation.
- The framework addresses the challenge of maintaining semantic and contextual consistency between images and text in multi-turn image generation scenarios.
- The paper also introduces a new benchmark, CMIGBench, for evaluating multi-turn image generation performance.
Plain English Explanation
The paper presents a new approach called TheaterGen that allows for generating high-quality images through multiple back-and-forth interactions between the user and the system. This is an important capability for real-world applications, where users often want to refine and build upon the images generated by the system.
The key idea behind TheaterGen is to use large language models (LLMs) to manage the "script" or prompts for each character in the target image, ensuring semantic consistency as the interaction progresses. Based on this script, TheaterGen then generates the individual character images and extracts guidance information to help the text-to-image (T2I) model produce the final, coherent image.
By effectively managing the prompt book and character images, TheaterGen is able to significantly improve the semantic and contextual consistency of the generated images, compared to previous multi-turn image generation approaches. The paper also introduces a new benchmark, CMIGBench, to evaluate multi-turn image generation performance in a more comprehensive way.
Technical Explanation
The paper proposes the TheaterGen framework, which consists of three main components:
- Screenwriter: An LLM that generates and manages a standardized "prompt book" that encompasses prompts and layout designs for each character in the target image.
- Rehearsal: The process of generating character images and extracting guidance information based on the prompt book.
- Final Performance: The text-to-image (T2I) diffusion model that incorporates the prompt book and guidance information to generate the final, coherent image.
By effectively managing the prompt book and character images, TheaterGen is able to maintain semantic and contextual consistency in the generated images across multiple interactive turns.
The paper also introduces a new benchmark, CMIGBench, which includes 8,000 multi-turn instructions for evaluating multi-turn image generation performance. Unlike previous benchmarks, CMIGBench does not define characters in advance, and it includes tasks for both story generation and multi-turn editing.
Extensive experiments show that TheaterGen outperforms state-of-the-art methods, including Mini DALLE 3, by a significant margin in terms of character-character similarity and text-image similarity.
Critical Analysis
While TheaterGen represents a significant advancement in multi-turn image generation, the paper does not address several potential limitations and areas for further research:
- The framework still relies on the availability of pre-trained T2I models, which may not be accessible or practical for all users.
- The performance of TheaterGen is heavily dependent on the quality and consistency of the LLM-generated prompt book, which could be challenging to maintain in more complex or open-ended scenarios.
- The paper does not explore the potential for personalized or interactive image generation, which could further enhance the user experience.
- The TextCenGen approach, which focuses on text-centric background adaptation, could potentially be integrated with TheaterGen to improve the overall image quality and coherence.
Nonetheless, the TheaterGen framework and the CMIGBench benchmark represent important contributions to the field of multi-turn image generation, and the results presented in the paper are quite promising.
Conclusion
The paper introduces TheaterGen, a training-free framework that integrates LLMs and T2I models to enable high-quality, semantically and contextually consistent multi-turn image generation. By effectively managing prompt books and character images, TheaterGen outperforms state-of-the-art methods on the new CMIGBench benchmark, raising the performance bar for this challenging task. While the framework has some limitations, it represents a significant step forward in making multi-turn image generation more practical and user-friendly for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
AutoStudio: Crafting Consistent Subjects in Multi-turn Interactive Image Generation
Junhao Cheng, Xi Lu, Hanhui Li, Khun Loun Zai, Baiqiao Yin, Yuhao Cheng, Yiqiang Yan, Xiaodan Liang
0
0
As cutting-edge Text-to-Image (T2I) generation models already excel at producing remarkable single images, an even more challenging task, i.e., multi-turn interactive image generation begins to attract the attention of related research communities. This task requires models to interact with users over multiple turns to generate a coherent sequence of images. However, since users may switch subjects frequently, current efforts struggle to maintain subject consistency while generating diverse images. To address this issue, we introduce a training-free multi-agent framework called AutoStudio. AutoStudio employs three agents based on large language models (LLMs) to handle interactions, along with a stable diffusion (SD) based agent for generating high-quality images. Specifically, AutoStudio consists of (i) a subject manager to interpret interaction dialogues and manage the context of each subject, (ii) a layout generator to generate fine-grained bounding boxes to control subject locations, (iii) a supervisor to provide suggestions for layout refinements, and (iv) a drawer to complete image generation. Furthermore, we introduce a Parallel-UNet to replace the original UNet in the drawer, which employs two parallel cross-attention modules for exploiting subject-aware features. We also introduce a subject-initialized generation method to better preserve small subjects. Our AutoStudio hereby can generate a sequence of multi-subject images interactively and consistently. Extensive experiments on the public CMIGBench benchmark and human evaluations show that AutoStudio maintains multi-subject consistency across multiple turns well, and it also raises the state-of-the-art performance by 13.65% in average Frechet Inception Distance and 2.83% in average character-character similarity.
6/12/2024
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Alicia Golden, Samuel Hsia, Fei Sun, Bilge Acun, Basil Hosmer, Yejin Lee, Zachary DeVito, Jeff Johnson, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
0
0
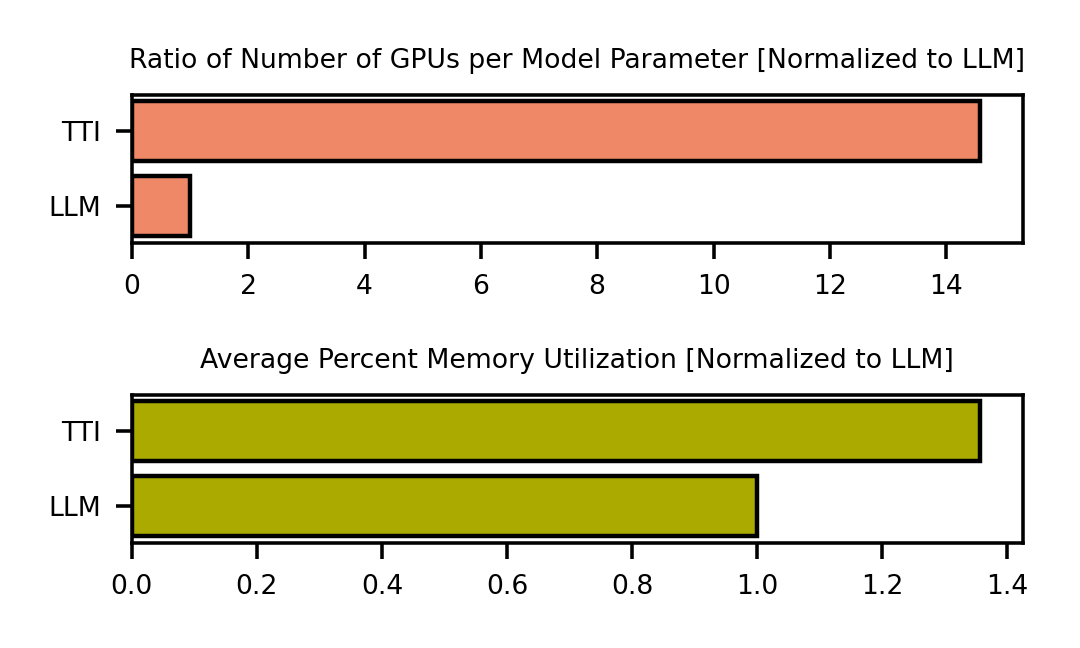
As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
5/7/2024

ORACLE: Leveraging Mutual Information for Consistent Character Generation with LoRAs in Diffusion Models
Kiymet Akdemir, Pinar Yanardag
0
0
Text-to-image diffusion models have recently taken center stage as pivotal tools in promoting visual creativity across an array of domains such as comic book artistry, children's literature, game development, and web design. These models harness the power of artificial intelligence to convert textual descriptions into vivid images, thereby enabling artists and creators to bring their imaginative concepts to life with unprecedented ease. However, one of the significant hurdles that persist is the challenge of maintaining consistency in character generation across diverse contexts. Variations in textual prompts, even if minor, can yield vastly different visual outputs, posing a considerable problem in projects that require a uniform representation of characters throughout. In this paper, we introduce a novel framework designed to produce consistent character representations from a single text prompt across diverse settings. Through both quantitative and qualitative analyses, we demonstrate that our framework outperforms existing methods in generating characters with consistent visual identities, underscoring its potential to transform creative industries. By addressing the critical challenge of character consistency, we not only enhance the practical utility of these models but also broaden the horizons for artistic and creative expression.
6/6/2024
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
0
0
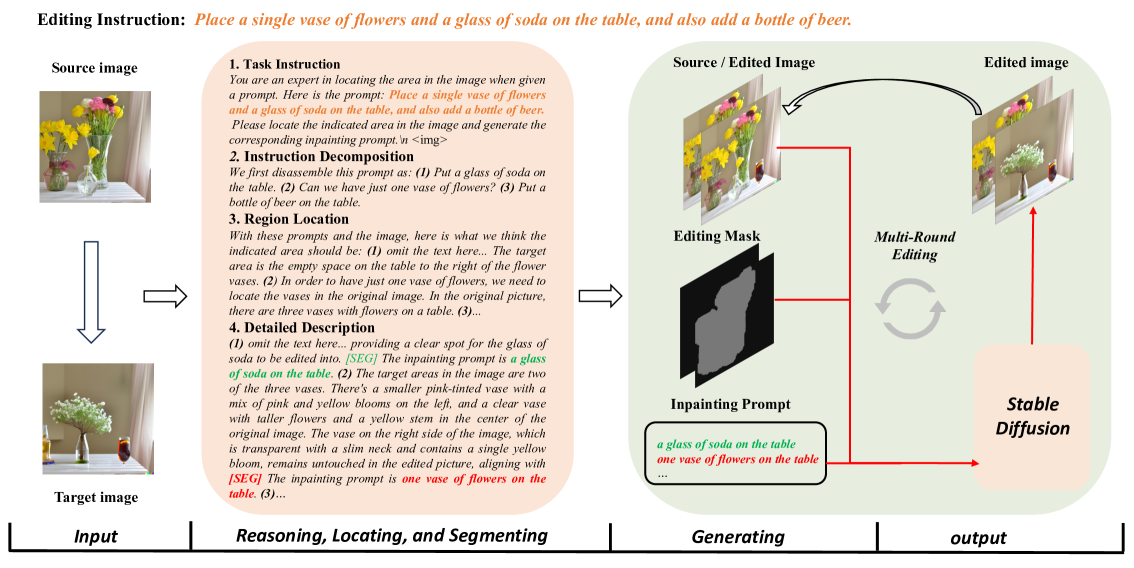
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
5/28/2024