There is more to graphs than meets the eye: Learning universal features with self-supervision

0
📉
Sign in to get full access
Overview
- The paper explores learning features through self-supervision that are generalizable across multiple graphs.
- Current graph self-supervision is limited to a single graph, resulting in graph-specific models that don't work well on other graphs.
- The researchers hypothesize that training on multiple graphs from the same family can improve representation quality.
- However, learning universal features from diverse node/edge features in different graphs is challenging.
Plain English Explanation
The researchers are looking to develop a way to train graph neural networks that can work well on multiple related graphs, rather than just a single graph.
Current approaches to training these models, called self-supervision, only use a single graph during training. This results in models that are specialized for that particular graph and don't perform as well when applied to other, similar graphs.
The researchers think that if you train the model on multiple graphs that are part of the same "family" of related graphs, it will learn more generalized features that can be reused across those graphs. This could lead to better performance, more efficient training, and more compact models.
However, getting the model to learn these universal features is tricky, since the different graphs may have very different node and edge features. To address this, the researchers first use graph-specific encoders to transform the features into a common space. Then a universal representation learning module can learn the generalized features on top of this shared feature space.
Technical Explanation
The key technical components of the researchers' approach are:
-
Graph-specific encoders: These transform the diverse node and edge features in each graph into a common feature space, so the downstream model doesn't have to deal with the heterogeneity.
-
Universal representation learning: This module learns generalized features that can be applied to multiple graphs, building on the homogenized features from the encoders.
-
End-to-end training: The entire system, including the encoders and universal representation module, is trained jointly in an end-to-end fashion.
The researchers show that this approach leads to several benefits compared to traditional single-graph self-supervision:
- Better downstream performance: The learned features result in higher accuracy on node classification tasks.
- Reusability: The features can be effectively transferred to unseen graphs in the same family.
- Efficiency: The training is more efficient, requiring fewer resources.
- Compactness: The final model is more compact while still maintaining high performance.
The researchers also demonstrate the ability of their framework to scale to relatively larger graphs.
Critical Analysis
The researchers acknowledge several limitations and areas for future work:
- The homogenization of features through the graph-specific encoders may lose important information, which could limit the quality of the learned representations.
- The performance gains were demonstrated on relatively small graphs, so the scalability to larger graphs needs further investigation.
- The framework was tested on a specific set of graph families, so its generalizability to other types of graphs is unclear.
Additionally, the paper does not discuss potential issues around the computational complexity of the end-to-end training process, which could be a concern for very large graphs or graph families.
Overall, this is a promising approach that could lead to more generalized and efficient graph neural network models. However, further research is needed to fully understand its capabilities and limitations.
Conclusion
This paper presents a novel framework for learning generalized features from multiple graphs, rather than being limited to a single graph. By first homogenizing the diverse features across graphs and then learning universal representations, the researchers demonstrate improvements in downstream performance, feature reusability, training efficiency, and model compactness.
While there are still some open questions and limitations to address, this work represents an important step towards developing more robust and versatile graph neural network models that can be effectively applied across a variety of related graphs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
There is more to graphs than meets the eye: Learning universal features with self-supervision
Laya Das, Sai Munikoti, Nrushad Joshi, Mahantesh Halappanavar
We study the problem of learning features through self-supervision that are generalisable to multiple graphs. State-of-the-art graph self-supervision restricts training to only one graph, resulting in graph-specific models that are incompatible with different but related graphs. We hypothesize that training with more than one graph that belong to the same family can improve the quality of the learnt representations. However, learning universal features from disparate node/edge features in different graphs is non-trivial. To address this challenge, we first homogenise the disparate features with graph-specific encoders that transform the features into a common space. A universal representation learning module then learns generalisable features on this common space. We show that compared to traditional self-supervision with one graph, our approach results in (1) better performance on downstream node classification, (2) learning features that can be re-used for unseen graphs of the same family, (3) more efficient training and (4) compact yet generalisable models. We also show ability of the proposed framework to deliver these benefits for relatively larger graphs. In this paper, we present a principled way to design foundation graph models that learn from more than one graph in an end-to-end manner, while bridging the gap between self-supervised and supervised performance.
Read more7/31/2024
0
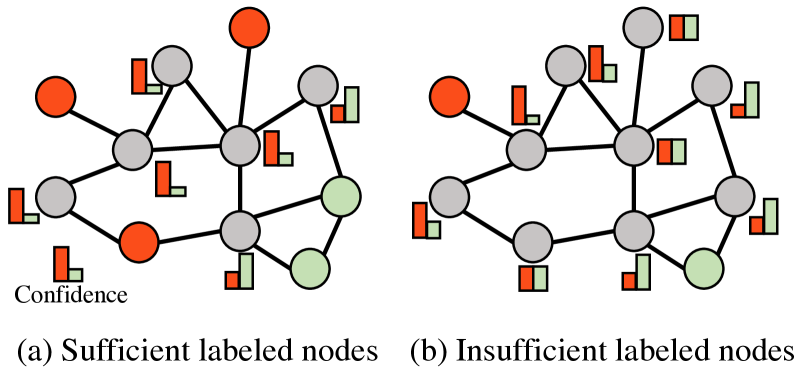
Multi-View Subgraph Neural Networks: Self-Supervised Learning with Scarce Labeled Data
Zhenzhong Wang, Qingyuan Zeng, Wanyu Lin, Min Jiang, Kay Chen Tan
While graph neural networks (GNNs) have become the de-facto standard for graph-based node classification, they impose a strong assumption on the availability of sufficient labeled samples. This assumption restricts the classification performance of prevailing GNNs on many real-world applications suffering from low-data regimes. Specifically, features extracted from scarce labeled nodes could not provide sufficient supervision for the unlabeled samples, leading to severe over-fitting. In this work, we point out that leveraging subgraphs to capture long-range dependencies can augment the representation of a node with homophily properties, thus alleviating the low-data regime. However, prior works leveraging subgraphs fail to capture the long-range dependencies among nodes. To this end, we present a novel self-supervised learning framework, called multi-view subgraph neural networks (Muse), for handling long-range dependencies. In particular, we propose an information theory-based identification mechanism to identify two types of subgraphs from the views of input space and latent space, respectively. The former is to capture the local structure of the graph, while the latter captures the long-range dependencies among nodes. By fusing these two views of subgraphs, the learned representations can preserve the topological properties of the graph at large, including the local structure and long-range dependencies, thus maximizing their expressiveness for downstream node classification tasks. Experimental results show that Muse outperforms the alternative methods on node classification tasks with limited labeled data.
Read more4/22/2024

0
Node Level Graph Autoencoder: Unified Pretraining for Textual Graph Learning
Wenbin Hu, Huihao Jing, Qi Hu, Haoran Li, Yangqiu Song
Textual graphs are ubiquitous in real-world applications, featuring rich text information with complex relationships, which enables advanced research across various fields. Textual graph representation learning aims to generate low-dimensional feature embeddings from textual graphs that can improve the performance of downstream tasks. A high-quality feature embedding should effectively capture both the structural and the textual information in a textual graph. However, most textual graph dataset benchmarks rely on word2vec techniques to generate feature embeddings, which inherently limits their capabilities. Recent works on textual graph representation learning can be categorized into two folds: supervised and unsupervised methods. Supervised methods finetune a language model on labeled nodes, which have limited capabilities when labeled data is scarce. Unsupervised methods, on the other hand, extract feature embeddings by developing complex training pipelines. To address these limitations, we propose a novel unified unsupervised learning autoencoder framework, named Node Level Graph AutoEncoder (NodeGAE). We employ language models as the backbone of the autoencoder, with pretraining on text reconstruction. Additionally, we add an auxiliary loss term to make the feature embeddings aware of the local graph structure. Our method maintains simplicity in the training process and demonstrates generalizability across diverse textual graphs and downstream tasks. We evaluate our method on two core graph representation learning downstream tasks: node classification and link prediction. Comprehensive experiments demonstrate that our approach substantially enhances the performance of diverse graph neural networks (GNNs) across multiple textual graph datasets.
Read more8/22/2024
👨🏫
0
Towards Generalised Pre-Training of Graph Models
Alex O. Davies, Riku W. Green, Nirav S. Ajmeri, Telmo M. Silva Filho
The principal benefit of unsupervised representation learning is that a pre-trained model can be fine-tuned where data or labels are scarce. Existing approaches for graph representation learning are domain specific, maintaining consistent node and edge features across the pre-training and target datasets. This has precluded transfer to multiple domains. In this work we present Topology Only Pre-Training, a graph pre-training method based on node and edge feature exclusion. Separating graph learning into two stages, topology and features, we use contrastive learning to pre-train models over multiple domains. These models show positive transfer on evaluation datasets from multiple domains, including domains not present in pre-training data. On 75% of experiments, ToP models perform significantly ($P leq 0.01$) better than a supervised baseline. These results include when node and edge features are used in evaluation, where performance is significantly better on 85.7% of tasks compared to single-domain or non-pre-trained models. We further show that out-of-domain topologies can produce more useful pre-training than in-domain. We show better transfer from non-molecule pre-training, compared to molecule pre-training, on 79% of molecular benchmarks.
Read more5/15/2024