ThinkGrasp: A Vision-Language System for Strategic Part Grasping in Clutter

0

Sign in to get full access
Overview
- This paper presents ThinkGrasp, a vision-language system for strategic part grasping in cluttered environments.
- The system combines computer vision and natural language processing to enable a robotic arm to identify and grasp target objects in complex scenes.
- Key aspects include using language to guide the grasping process and learning from human demonstrations to improve performance.
Plain English Explanation
ThinkGrasp is a robotic system that can identify and pick up specific objects from a cluttered, messy environment. It does this by using both computer vision (to see the objects) and natural language processing (to understand instructions about which object to grab).
The core idea is to have the system "think" about the grasping task before acting. It uses language-based guidance to determine the best way to grasp the target object, rather than just randomly trying different grasping motions. This makes the grasping more strategic and effective, especially in complex, cluttered scenes where there are many objects.
The system also learns from examples of humans grasping objects. By observing these demonstrations, it can refine its own grasping techniques to become more skilled and reliable over time. This combination of vision, language, and learning allows ThinkGrasp to grasp objects in challenging real-world settings where previous robotic systems may have struggled.
Technical Explanation
The paper introduces the ThinkGrasp system, which integrates computer vision and natural language processing to enable strategic part grasping in cluttered environments. The key aspects include:
-
Using language-based guidance to inform the grasping process, rather than relying solely on vision-based heuristics. This allows the system to reason about the task and select more strategic grasping motions.
-
Incorporating learning from human demonstrations to improve the system's grasping capabilities over time. By observing examples of successful human grasping, ThinkGrasp can refine its own techniques.
-
Leveraging large language models and vision-language pretraining to build a multimodal system that can understand both the visual scene and the linguistic instructions about the target object.
The paper describes the overall system architecture, including the computer vision and language modules, as well as the training process that allows the system to learn effective grasping strategies. Experiments show that ThinkGrasp outperforms previous state-of-the-art grasping systems, particularly in cluttered scenes where strategic reasoning is required.
Critical Analysis
The paper presents a compelling approach to robotic grasping that combines vision and language in an innovative way. However, the authors acknowledge several limitations and areas for future work:
- The current system is primarily focused on grasping individual target objects, and does not yet handle more complex tasks like rearranging or manipulating multiple objects in a cluttered scene.
- The language understanding capabilities, while advanced, are still limited compared to human-level reasoning. More sophisticated language models or interaction techniques may be needed to fully leverage language for strategic grasping.
- The training process relies heavily on simulated data and human demonstrations, which may not fully capture the nuances of real-world grasping. More robust techniques for transferring the learned skills to physical robot platforms could be explored.
Additionally, the paper does not address potential ethical considerations around the deployment of such robotic systems, such as their impact on human labor or the risks of unintended behaviors. Further research on the societal implications of advanced robotic grasping systems would be valuable.
Conclusion
The ThinkGrasp system represents a significant step forward in the field of robotic grasping, demonstrating the power of combining computer vision and natural language processing to enable more strategic and adaptable part manipulation in cluttered environments. By incorporating language-based guidance and learning from human demonstrations, the system can grasp objects more effectively than previous approaches.
While the current implementation has some limitations, the core ideas behind ThinkGrasp suggest promising avenues for future research in robotic manipulation, with potential applications in areas like logistics, manufacturing, and household assistance. As the technology continues to evolve, it will be important to also consider the broader societal implications and ensure that these advancements are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ThinkGrasp: A Vision-Language System for Strategic Part Grasping in Clutter
Yaoyao Qian, Xupeng Zhu, Ondrej Biza, Shuo Jiang, Linfeng Zhao, Haojie Huang, Yu Qi, Robert Platt
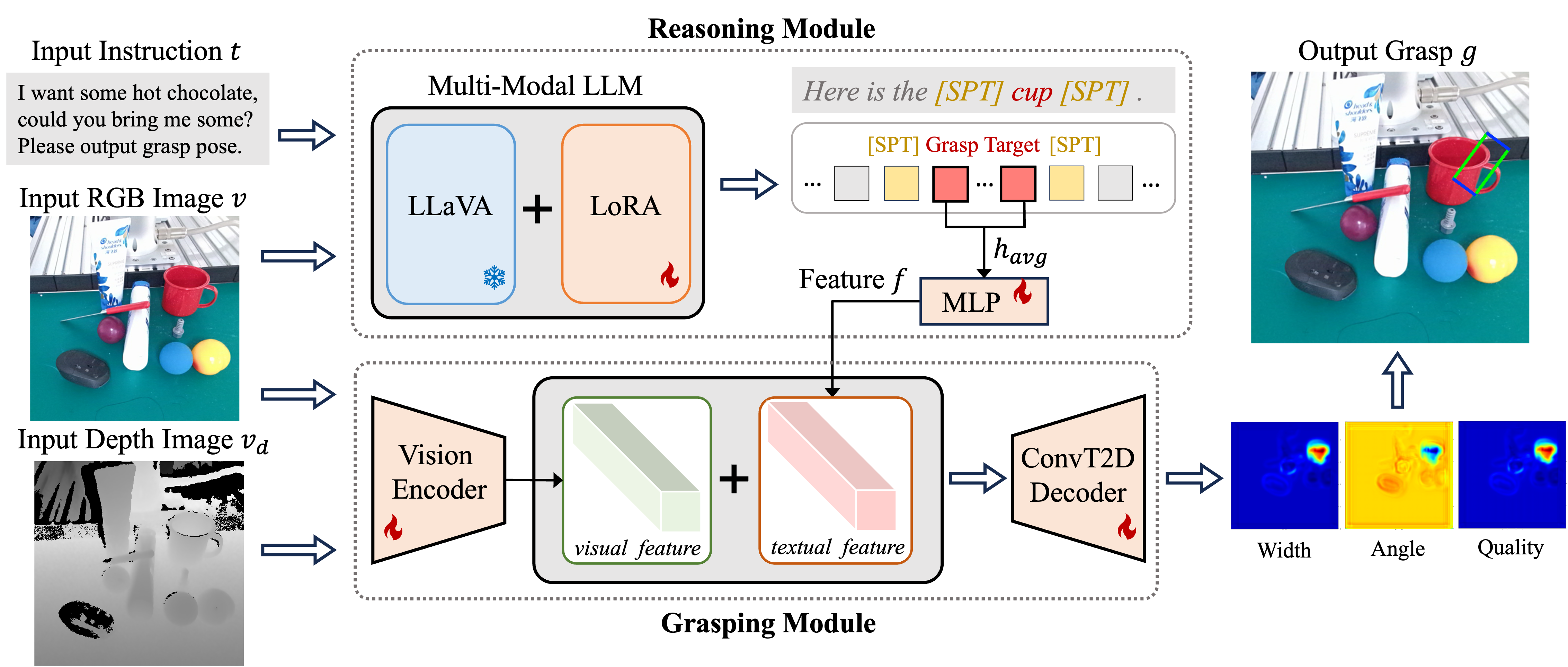
Robotic grasping in cluttered environments remains a significant challenge due to occlusions and complex object arrangements. We have developed ThinkGrasp, a plug-and-play vision-language grasping system that makes use of GPT-4o's advanced contextual reasoning for heavy clutter environment grasping strategies. ThinkGrasp can effectively identify and generate grasp poses for target objects, even when they are heavily obstructed or nearly invisible, by using goal-oriented language to guide the removal of obstructing objects. This approach progressively uncovers the target object and ultimately grasps it with a few steps and a high success rate. In both simulated and real experiments, ThinkGrasp achieved a high success rate and significantly outperformed state-of-the-art methods in heavily cluttered environments or with diverse unseen objects, demonstrating strong generalization capabilities.
Read more7/17/2024
0
Reasoning Grasping via Multimodal Large Language Model
Shiyu Jin, Jinxuan Xu, Yutian Lei, Liangjun Zhang
Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
Read more4/29/2024

0
Towards Open-World Grasping with Large Vision-Language Models
Georgios Tziafas, Hamidreza Kasaei
The ability to grasp objects in-the-wild from open-ended language instructions constitutes a fundamental challenge in robotics. An open-world grasping system should be able to combine high-level contextual with low-level physical-geometric reasoning in order to be applicable in arbitrary scenarios. Recent works exploit the web-scale knowledge inherent in large language models (LLMs) to plan and reason in robotic context, but rely on external vision and action models to ground such knowledge into the environment and parameterize actuation. This setup suffers from two major bottlenecks: a) the LLM's reasoning capacity is constrained by the quality of visual grounding, and b) LLMs do not contain low-level spatial understanding of the world, which is essential for grasping in contact-rich scenarios. In this work we demonstrate that modern vision-language models (VLMs) are capable of tackling such limitations, as they are implicitly grounded and can jointly reason about semantics and geometry. We propose OWG, an open-world grasping pipeline that combines VLMs with segmentation and grasp synthesis models to unlock grounded world understanding in three stages: open-ended referring segmentation, grounded grasp planning and grasp ranking via contact reasoning, all of which can be applied zero-shot via suitable visual prompting mechanisms. We conduct extensive evaluation in cluttered indoor scene datasets to showcase OWG's robustness in grounding from open-ended language, as well as open-world robotic grasping experiments in both simulation and hardware that demonstrate superior performance compared to previous supervised and zero-shot LLM-based methods.
Read more7/16/2024

0
Sim-Grasp: Learning 6-DOF Grasp Policies for Cluttered Environments Using a Synthetic Benchmark
Juncheng Li, David J. Cappelleri
In this paper, we present Sim-Grasp, a robust 6-DOF two-finger grasping system that integrates advanced language models for enhanced object manipulation in cluttered environments. We introduce the Sim-Grasp-Dataset, which includes 1,550 objects across 500 scenarios with 7.9 million annotated labels, and develop Sim-GraspNet to generate grasp poses from point clouds. The Sim-Grasp-Polices achieve grasping success rates of 97.14% for single objects and 87.43% and 83.33% for mixed clutter scenarios of Levels 1-2 and Levels 3-4 objects, respectively. By incorporating language models for target identification through text and box prompts, Sim-Grasp enables both object-agnostic and target picking, pushing the boundaries of intelligent robotic systems.
Read more7/18/2024