Thinking Forward: Memory-Efficient Federated Finetuning of Language Models
2405.15551
0
0

Abstract
Finetuning large language models (LLMs) in federated learning (FL) settings has become important as it allows resource-constrained devices to finetune a model using private data. However, finetuning LLMs using backpropagation requires excessive memory (especially from intermediate activations) for resource-constrained devices. While Forward-mode Auto-Differentiation (AD) can reduce memory footprint from activations, we observe that directly applying it to LLM finetuning results in slow convergence and poor accuracy. This work introduces Spry, an FL algorithm that splits trainable weights of an LLM among participating clients, such that each client computes gradients using Forward-mode AD that are closer estimates of the true gradients. Spry achieves a low memory footprint, high accuracy, and fast convergence. We theoretically show that the global gradients in Spry are unbiased estimates of true global gradients for homogeneous data distributions across clients, while heterogeneity increases bias of the estimates. We also derive Spry's convergence rate, showing that the gradients decrease inversely proportional to the number of FL rounds, indicating the convergence up to the limits of heterogeneity. Empirically, Spry reduces the memory footprint during training by 1.4-7.1$times$ in contrast to backpropagation, while reaching comparable accuracy, across a wide range of language tasks, models, and FL settings. Spry reduces the convergence time by 1.2-20.3$times$ and achieves 5.2-13.5% higher accuracy against state-of-the-art zero-order methods. When finetuning Llama2-7B with LoRA, compared to the peak memory usage of 33.9GB of backpropagation, Spry only consumes 6.2GB of peak memory. For OPT13B, the reduction is from 76.5GB to 10.8GB. Spry makes feasible previously impossible FL deployments on commodity mobile and edge devices. Source code is available at https://github.com/Astuary/Spry.
Create account to get full access
Overview
- This paper introduces a novel approach called "Forward-mode Automatic Differentiation" (FmAD) for memory-efficient federated finetuning of large language models (LLMs).
- The proposed method allows for the finetuning of LLMs on the edge with a significantly reduced memory footprint compared to traditional methods.
- The paper also explores the application of FmAD to other federated learning scenarios, such as federated full-parameter tuning of billion-sized language models and zeroth-order optimization for federated learning.
Plain English Explanation
The paper introduces a new technique called "Forward-mode Automatic Differentiation" (FmAD) that enables the finetuning of large language models (LLMs) on edge devices, such as smartphones or IoT sensors, in a memory-efficient way. Traditional finetuning methods can be memory-intensive, making them challenging to deploy on resource-constrained devices.
FmAD works by reversing the typical workflow of training machine learning models. Instead of the more common "backward-mode" differentiation, which computes gradients by working backward from the output to the input, FmAD computes gradients by working forward from the input to the output. This forward-mode approach significantly reduces the memory required for finetuning, making it possible to update large language models on edge devices with limited resources.
The paper also demonstrates how FmAD can be applied to other federated learning scenarios, such as federated full-parameter tuning of billion-sized language models and zeroth-order optimization for federated learning. These applications showcase the versatility of the FmAD approach and its potential to enable more efficient and accessible federated learning on a wide range of devices.
Technical Explanation
The key innovation presented in the paper is the "Forward-mode Automatic Differentiation" (FmAD) technique for memory-efficient federated finetuning of large language models (LLMs). Traditional backpropagation-based finetuning can be memory-intensive, as it requires storing intermediate activations during the backward pass. FmAD addresses this issue by reversing the typical workflow of training machine learning models.
Instead of the more common "backward-mode" differentiation, which computes gradients by working backward from the output to the input, FmAD computes gradients by working forward from the input to the output. This forward-mode approach significantly reduces the memory required for finetuning, as it only needs to store the final activations and gradients, rather than the entire computation graph.
The paper demonstrates the effectiveness of FmAD in two main scenarios:
- Federated finetuning of LLMs on the edge: FmAD enables the finetuning of large language models on resource-constrained edge devices, such as smartphones or IoT sensors, by reducing the memory footprint of the finetuning process.
- Federated full-parameter tuning of billion-sized language models: The paper shows how FmAD can be applied to enable the federated finetuning of even larger language models, including billion-parameter models, by further reducing the memory requirements.
Additionally, the paper explores the application of FmAD to zeroth-order optimization for federated learning, demonstrating the versatility of the proposed approach.
Critical Analysis
The paper presents a compelling solution to the memory-efficiency challenge in federated finetuning of large language models. The FmAD approach is a significant advancement, as it enables the finetuning of LLMs on resource-constrained edge devices, which was previously not feasible with traditional methods.
One potential limitation of the FmAD approach is that it may not be as computationally efficient as backward-mode differentiation in certain scenarios. The paper acknowledges this and suggests that future work could explore hybrid methods that combine the strengths of both forward-mode and backward-mode differentiation.
Additionally, the paper does not provide a comprehensive comparison of FmAD with other memory-efficient finetuning techniques, such as informed pruning for automated federated learning or personalized wireless federated learning for large language models. A deeper analysis of the trade-offs and relative performance of these different approaches would further strengthen the paper's contribution.
Overall, the paper makes a significant contribution to the field of federated learning by introducing a novel and practical technique for memory-efficient finetuning of large language models on the edge. The potential applications of FmAD, as demonstrated in the paper, suggest that it could have a substantial impact on the accessibility and deployment of advanced language models in resource-constrained environments.
Conclusion
The paper introduces a novel approach called "Forward-mode Automatic Differentiation" (FmAD) that enables memory-efficient federated finetuning of large language models (LLMs). By reversing the typical workflow of training machine learning models, FmAD significantly reduces the memory requirements for finetuning, making it possible to update large language models on resource-constrained edge devices.
The paper demonstrates the effectiveness of FmAD in two key scenarios: federated finetuning of LLMs on the edge and federated full-parameter tuning of billion-sized language models. The versatility of the FmAD approach is further highlighted by its application to zeroth-order optimization for federated learning.
While the paper acknowledges potential limitations in computational efficiency compared to backward-mode differentiation, the overall contribution of the FmAD technique is significant. By enabling the federated finetuning of large language models on the edge, this research paves the way for more accessible and personalized language-based AI applications across a wide range of devices and use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SpaFL: Communication-Efficient Federated Learning with Sparse Models and Low computational Overhead
Minsu Kim, Walid Saad, Merouane Debbah, Choong Seon Hong
0
0
The large communication and computation overhead of federated learning (FL) is one of the main challenges facing its practical deployment over resource-constrained clients and systems. In this work, SpaFL: a communication-efficient FL framework is proposed to optimize sparse model structures with low computational overhead. In SpaFL, a trainable threshold is defined for each filter/neuron to prune its all connected parameters, thereby leading to structured sparsity. To optimize the pruning process itself, only thresholds are communicated between a server and clients instead of parameters, thereby learning how to prune. Further, global thresholds are used to update model parameters by extracting aggregated parameter importance. The generalization bound of SpaFL is also derived, thereby proving key insights on the relation between sparsity and performance. Experimental results show that SpaFL improves accuracy while requiring much less communication and computing resources compared to sparse baselines.
6/4/2024
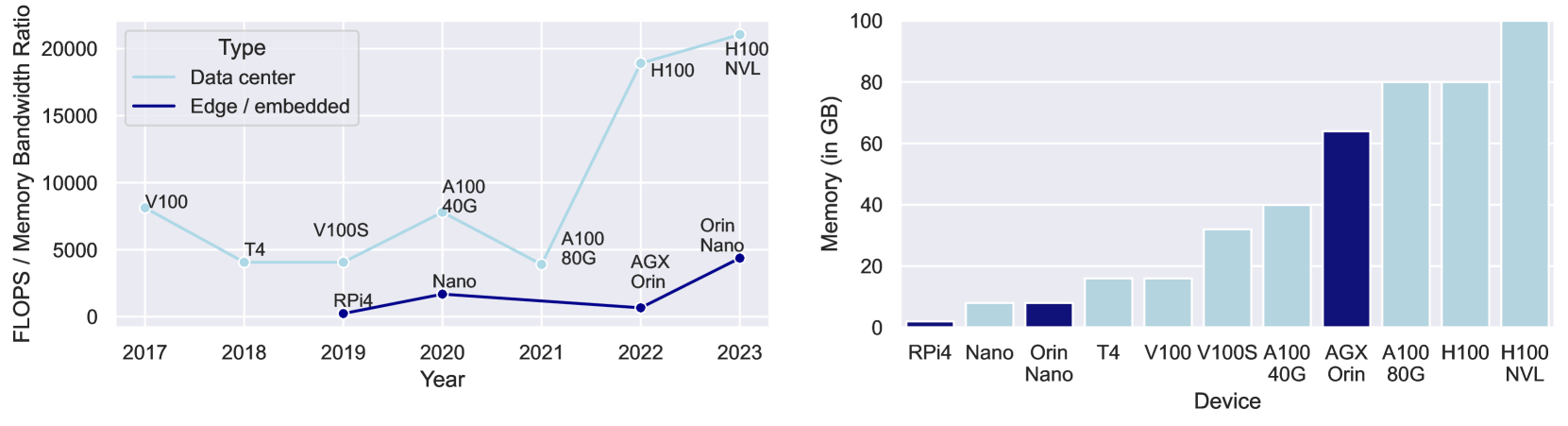
Federated Fine-Tuning of LLMs on the Very Edge: The Good, the Bad, the Ugly
Herbert Woisetschlager, Alexander Isenko, Shiqiang Wang, Ruben Mayer, Hans-Arno Jacobsen
0
0
Large Language Models (LLM) and foundation models are popular as they offer new opportunities for individuals and businesses to improve natural language processing, interact with data, and retrieve information faster. However, training or fine-tuning LLMs requires a vast amount of data, which can be challenging to access due to legal or technical restrictions and may require private computing resources. Federated Learning (FL) is a solution designed to overcome these challenges and expand data access for deep learning applications. This paper takes a hardware-centric approach to explore how LLMs can be brought to modern edge computing systems. Our study fine-tunes the FLAN-T5 model family, ranging from 80M to 3B parameters, using FL for a text summarization task. We provide a micro-level hardware benchmark, compare the model FLOP utilization to a state-of-the-art data center GPU, and study the network utilization in realistic conditions. Our contribution is twofold: First, we evaluate the current capabilities of edge computing systems and their potential for LLM FL workloads. Second, by comparing these systems with a data-center GPU, we demonstrate the potential for improvement and the next steps toward achieving greater computational efficiency at the edge.
5/3/2024
💬
Federated Fine-tuning of Large Language Models under Heterogeneous Tasks and Client Resources
Jiamu Bai, Daoyuan Chen, Bingchen Qian, Liuyi Yao, Yaliang Li
0
0
Federated Learning (FL) has recently been applied to the parameter-efficient fine-tuning of Large Language Models (LLMs). While promising, it raises significant challenges due to the heterogeneous resources and data distributions of clients. This study introduces FlexLoRA, a simple yet effective aggregation scheme for LLM fine-tuning, which mitigates the ``bucket effect'' in traditional FL that restricts the potential of clients with ample resources by tying them to the capabilities of the least-resourced participants. FlexLoRA allows for dynamic adjustment of local LoRA ranks, fostering the development of a global model imbued with broader, less task-specific knowledge. By synthesizing a full-size LoRA weight from individual client contributions and employing Singular Value Decomposition (SVD) for weight redistribution, FlexLoRA fully leverages heterogeneous client resources. Involving thousands of clients performing heterogeneous NLP tasks and client resources, our experiments validate the efficacy of FlexLoRA, with the federated global model achieving consistently better improvement over SOTA FL methods in downstream NLP task performance across various heterogeneous distributions. FlexLoRA's practicality is further underscored by our theoretical analysis and its seamless integration with existing LoRA-based FL methods, offering a path toward cross-device, privacy-preserving federated tuning for LLMs.
5/31/2024

Save It All: Enabling Full Parameter Tuning for Federated Large Language Models via Cycle Black Gradient Descent
Lin Wang, Zhichao Wang, Xiaoying Tang
0
0
The advent of large language models (LLMs) has revolutionized the deep learning paradigm, yielding impressive results across a wide array of tasks. However, the pre-training or fine-tuning of LLMs within a federated learning (FL) framework poses substantial challenges, including considerable computational and memory resource demands, as well as communication bottlenecks between servers and clients. Existing solutions either make the unrealistic assumption that the entire model is exchanged for training, or apply parameter-effective fine-tuning methods from centralized learning to train LLMs in FL which tend to underperform during training or fine-tuning stages due to the limited search subspace of parameter updating. In this paper, we introduce a novel method for the efficient training and fine-tuning of LLMs in FL, with minimal resource consumption. Our approach, termed FedCyBGD, utilizes Cycle Block Gradient Descent to periodically update the model. In particular, we design a compression scheme for FedCyBGD, aiming to further decrease the model download cost. It enables full parameter training in FL with only selected block updates and uploads, thereby reducing communication, computation, and memory costs. Our method achieves state-of-the-art performance for FL LLM training, while significantly reducing associated costs. Codes are provided here.
6/18/2024