Thought-Like-Pro: Enhancing Reasoning of Large Language Models through Self-Driven Prolog-based Chain-of-Though

0

Sign in to get full access
Overview
- This paper presents a novel approach called "Thought-Like-Pro" that aims to enhance the reasoning capabilities of large language models through self-driven Prolog-based "chain-of-thought" generation.
- The key idea is to incorporate Prolog-based logical reasoning into the language model's output, enabling it to generate step-by-step explanations for its decisions.
- The paper explores how this approach can improve the model's performance on complex reasoning tasks compared to traditional language models.
Plain English Explanation
The researchers have developed a new technique called "Thought-Like-Pro" that helps large language models [like GPT-3] become better at logical reasoning and explaining their thought processes. The basic idea is to combine the language model with a Prolog-based reasoning system, which is a type of artificial intelligence that can perform logical deductions.
The language model is trained to generate a "chain-of-thought" - a step-by-step explanation of how it arrived at its final answer or conclusion. This chain-of-thought is driven by the Prolog-based reasoning system, which allows the model to break down complex problems into smaller, logical steps.
By incorporating this Prolog-based reasoning, the researchers believe the language model will be able to tackle more challenging reasoning tasks more effectively than traditional language models that don't have this extra logical reasoning capability. The key benefit is that the model can now provide transparency into its decision-making process, rather than just outputting a final answer without any explanation.
Technical Explanation
The core of the "Thought-Like-Pro" approach is the integration of a Prolog-based reasoning system with a large language model. Prolog is a programming language based on logical inference, allowing it to perform step-by-step logical deductions.
The researchers train the language model to generate a "chain-of-thought" - a sequence of logical steps that lead to the final output. This chain-of-thought is driven by the Prolog-based reasoning system, which provides the logical structure and constraints to guide the language model's generation.
Specifically, the language model is fine-tuned on a dataset of Prolog-based logical reasoning problems. During training, the model learns to generate not just the final answer, but also the intermediate reasoning steps in Prolog-style logic. This teaches the model to break down complex problems into a series of logical inferences.
At inference time, the language model takes an input problem and generates the corresponding chain-of-thought, leveraging the Prolog-based reasoning capabilities. This allows the model to provide transparency into its decision-making process, rather than just outputting a final result.
The researchers evaluate the "Thought-Like-Pro" approach on a range of reasoning tasks, including logical puzzles, multi-step math problems, and open-ended reasoning questions. The results show that the integrated Prolog-based reasoning can significantly improve the language model's performance compared to traditional approaches.
Critical Analysis
The "Thought-Like-Pro" approach is a promising step towards enhancing the reasoning capabilities of large language models. By incorporating Prolog-based logical reasoning, the model is able to generate step-by-step explanations for its decisions, which can improve transparency and trust in the model's outputs.
However, the paper does not extensively discuss the limitations or potential drawbacks of this approach. For example, it's unclear how well the Prolog-based reasoning scales to more complex, open-ended reasoning tasks beyond the specific benchmarks evaluated. Additionally, the computational overhead of integrating the Prolog system may limit the real-world applicability of the approach.
Further research is needed to explore the generalizability of "Thought-Like-Pro" to a wider range of reasoning domains, as well as potential ways to optimize the integration of logical reasoning with language modeling for efficiency and scalability. Addressing these challenges could help unlock the full potential of this hybrid approach to enhance the reasoning capabilities of large language models.
Conclusion
The "Thought-Like-Pro" approach presented in this paper represents an important step forward in improving the reasoning capabilities of large language models. By incorporating Prolog-based logical reasoning into the language model's output generation, the researchers have enabled the model to provide transparent, step-by-step explanations for its decisions.
This enhanced reasoning ability has the potential to improve the model's performance on complex, multi-step reasoning tasks, as well as increase trust and transparency in the model's outputs. While further research is needed to address the limitations and scale the approach, "Thought-Like-Pro" demonstrates a promising direction for advancing the state-of-the-art in large language model reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Thought-Like-Pro: Enhancing Reasoning of Large Language Models through Self-Driven Prolog-based Chain-of-Though
Xiaoyu Tan (INF Technology), Yongxin Deng (Shanghai University of Engineering Science), Xihe Qiu (Shanghai University of Engineering Science), Weidi Xu (INF Technology), Chao Qu (INF Technology), Wei Chu (INF Technology), Yinghui Xu (Fudan University), Yuan Qi (Fudan University)
Large language models (LLMs) have shown exceptional performance as general-purpose assistants, excelling across a variety of reasoning tasks. This achievement represents a significant step toward achieving artificial general intelligence (AGI). Despite these advancements, the effectiveness of LLMs often hinges on the specific prompting strategies employed, and there remains a lack of a robust framework to facilitate learning and generalization across diverse reasoning tasks. To address these challenges, we introduce a novel learning framework, THOUGHT-LIKE-PRO In this framework, we utilize imitation learning to imitate the Chain-of-Thought (CoT) process which is verified and translated from reasoning trajectories generated by a symbolic Prolog logic engine. This framework proceeds in a self-driven manner, that enables LLMs to formulate rules and statements from given instructions and leverage the symbolic Prolog engine to derive results. Subsequently, LLMs convert Prolog-derived successive reasoning trajectories into natural language CoT for imitation learning. Our empirical findings indicate that our proposed approach substantially enhances the reasoning abilities of LLMs and demonstrates robust generalization across out-of-distribution reasoning tasks.
Read more8/13/2024
0
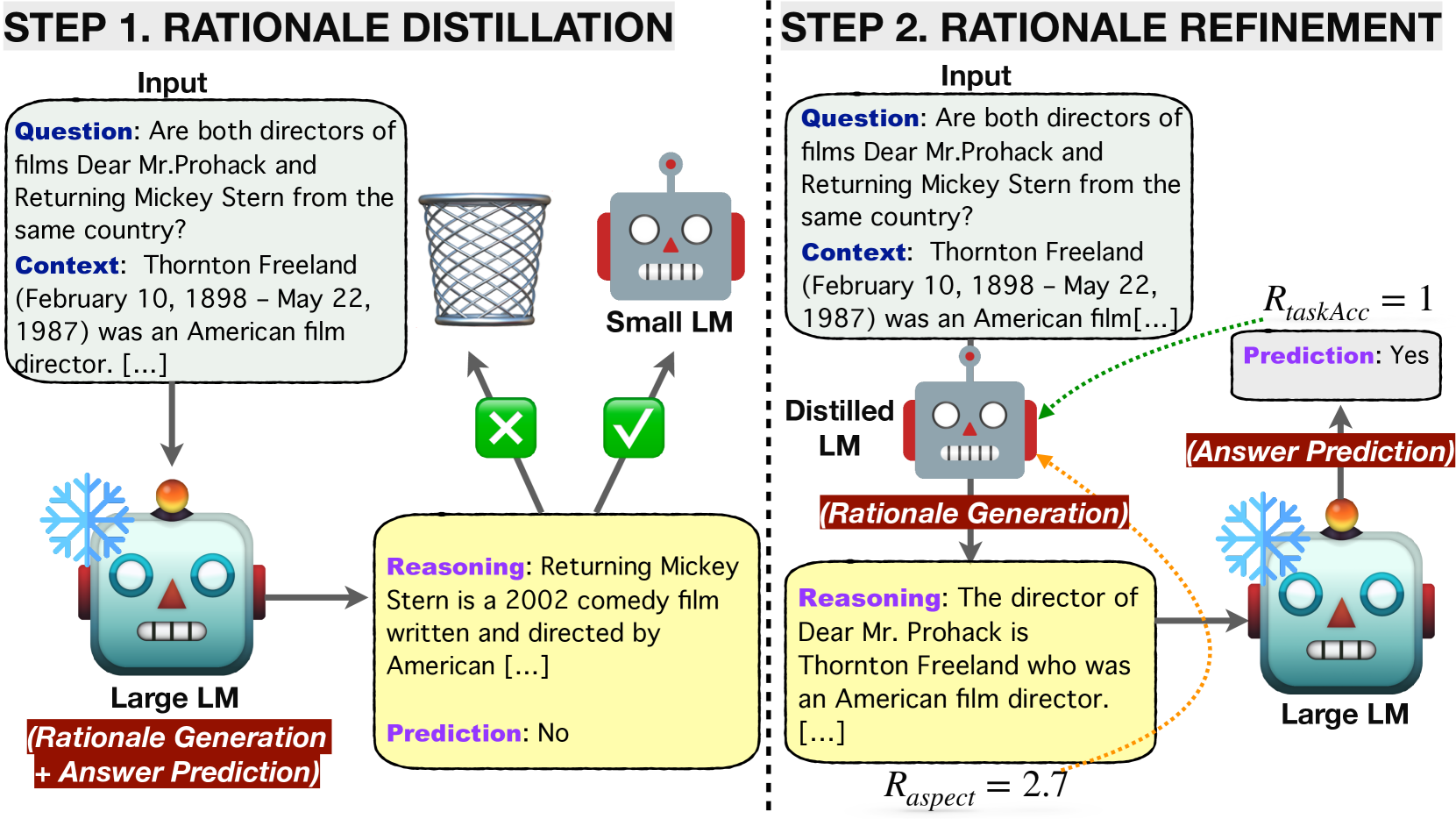
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
Read more4/5/2024
💬
0
Why Can Large Language Models Generate Correct Chain-of-Thoughts?
Rasul Tutunov, Antoine Grosnit, Juliusz Ziomek, Jun Wang, Haitham Bou-Ammar
This paper delves into the capabilities of large language models (LLMs), specifically focusing on advancing the theoretical comprehension of chain-of-thought prompting. We investigate how LLMs can be effectively induced to generate a coherent chain of thoughts. To achieve this, we introduce a two-level hierarchical graphical model tailored for natural language generation. Within this framework, we establish a compelling geometrical convergence rate that gauges the likelihood of an LLM-generated chain of thoughts compared to those originating from the true language. Our findings provide a theoretical justification for the ability of LLMs to produce the correct sequence of thoughts (potentially) explaining performance gains in tasks demanding reasoning skills.
Read more6/7/2024

0
General Purpose Verification for Chain of Thought Prompting
Robert Vacareanu, Anurag Pratik, Evangelia Spiliopoulou, Zheng Qi, Giovanni Paolini, Neha Anna John, Jie Ma, Yassine Benajiba, Miguel Ballesteros
Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
Read more5/2/2024