TIGQA:An Expert Annotated Question Answering Dataset in Tigrinya
2404.17194
0
0
🌿
Abstract
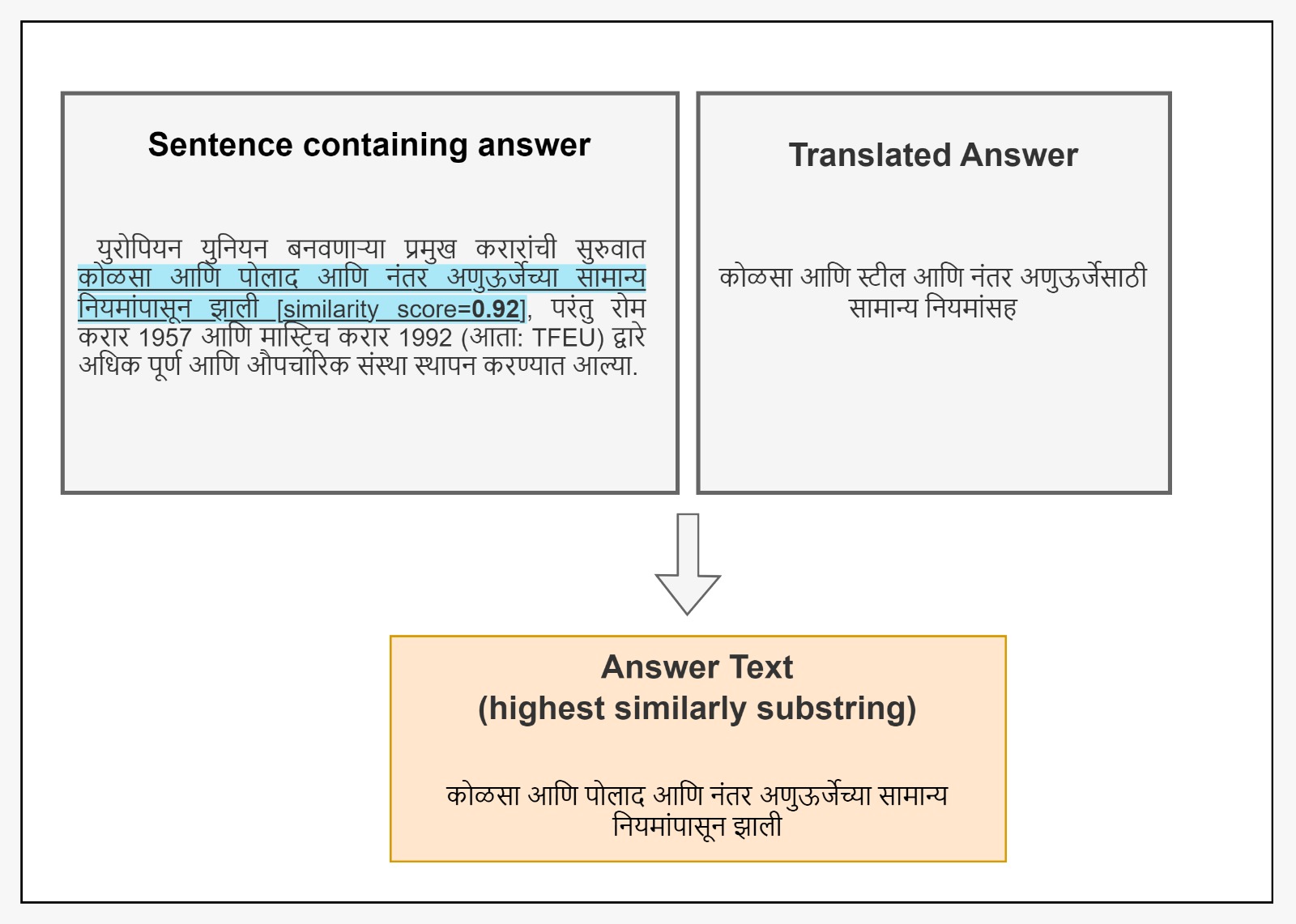
The absence of explicitly tailored, accessible annotated datasets for educational purposes presents a notable obstacle for NLP tasks in languages with limited resources.This study initially explores the feasibility of using machine translation (MT) to convert an existing dataset into a Tigrinya dataset in SQuAD format. As a result, we present TIGQA, an expert annotated educational dataset consisting of 2.68K question-answer pairs covering 122 diverse topics such as climate, water, and traffic. These pairs are from 537 context paragraphs in publicly accessible Tigrinya and Biology books. Through comprehensive analyses, we demonstrate that the TIGQA dataset requires skills beyond simple word matching, requiring both single-sentence and multiple-sentence inference abilities. We conduct experiments using state-of-the art MRC methods, marking the first exploration of such models on TIGQA. Additionally, we estimate human performance on the dataset and juxtapose it with the results obtained from pretrained models.The notable disparities between human performance and best model performance underscore the potential for further enhancements to TIGQA through continued research. Our dataset is freely accessible via the provided link to encourage the research community to address the challenges in the Tigrinya MRC.
Create account to get full access
Overview
- This study explores the feasibility of using machine translation to create a Tigrinya question-answering dataset for educational purposes.
- The researchers present TIGQA, an expert-annotated dataset of 2.68K question-answer pairs covering diverse topics like climate, water, and traffic.
- The dataset is designed to require skills beyond simple word matching, testing both single-sentence and multiple-sentence inference abilities.
- Experiments with state-of-the-art reading comprehension models mark the first exploration of such models on the TIGQA dataset.
- The study compares model performance to human performance, highlighting the potential for further enhancements to the dataset through continued research.
Plain English Explanation
The researchers in this study recognized a notable obstacle for natural language processing (NLP) tasks in languages with limited resources: the lack of accessible, annotated datasets tailored for educational purposes. To address this, they explored using machine translation to convert an existing dataset into a Tigrinya dataset in the SQuAD format, which is a popular question-answering dataset.
The result of their work is TIGQA, a new dataset that contains 2.68K question-answer pairs covering a wide range of topics, such as climate, water, and traffic. These pairs were extracted from publicly available Tigrinya and Biology books. The researchers designed the dataset to require skills beyond simple word matching, testing both the ability to make inferences from single sentences and multiple sentences.
To better understand the capabilities of TIGQA, the researchers conducted experiments using state-of-the-art machine reading comprehension models. This marked the first time these advanced models were evaluated on the TIGQA dataset. The researchers also estimated human performance on the dataset and compared it to the model results.
The notable differences between human performance and the best model performance highlighted the potential for further improvements to the TIGQA dataset through continued research. The researchers made the dataset freely available to encourage the research community to take on the challenge of addressing the needs of the Tigrinya language in machine reading comprehension.
Technical Explanation
The researchers in this study leveraged machine translation to create a Tigrinya question-answering dataset, as the absence of such resources for languages with limited data presented a significant obstacle for NLP tasks. They developed TIGQA, an expert-annotated dataset containing 2.68K question-answer pairs extracted from 537 context paragraphs in publicly accessible Tigrinya and Biology books.
The dataset was designed to require skills beyond simple word matching, testing both single-sentence and multiple-sentence inference abilities. The researchers conducted experiments using state-of-the-art machine reading comprehension (MRC) methods, marking the first exploration of such models on the TIGQA dataset. They also estimated human performance on the dataset and compared it to the results obtained from pretrained models.
The disparities between human performance and the best model performance underscored the potential for further enhancements to TIGQA through continued research. The dataset is freely accessible to encourage the research community to address the challenges in Tigrinya MRC, as highlighted by the MAHASQUAD, Can Multi-Choice Dataset be Repurposed for Extractive Question, Synthetic Dataset Creation for Fine-Tuning Transformer Models, EUSQuAD: Automatically Translated and Aligned SQuAD 2.0 in Basque, and EMRQA: An Extractive QA Dataset for Medical Text studies.
Critical Analysis
The researchers have taken a commendable step in addressing the lack of accessible, annotated datasets for educational NLP tasks in low-resource languages like Tigrinya. By leveraging machine translation, they were able to create a novel dataset, TIGQA, that goes beyond simple word matching and tests more complex inference abilities.
However, the reliance on machine translation introduces potential limitations, as the quality of the translated content may not fully capture the nuances and subtleties of the original Tigrinya text. Additionally, the dataset's size, while substantial, may still be relatively small compared to the vast amounts of data typically required for training state-of-the-art models.
Furthermore, the researchers' experiments with the TIGQA dataset are just the beginning, and there is ample room for further research and improvements. Exploring more advanced model architectures, incorporating domain-specific knowledge, and expanding the dataset's coverage of diverse topics could lead to significant advancements in Tigrinya machine reading comprehension.
Despite these potential limitations, the TIGQA dataset represents a valuable contribution to the research community and a step towards addressing the challenges faced in low-resource language NLP tasks. The researchers' commitment to making the dataset freely accessible is commendable and will undoubtedly foster further exploration and collaboration in this important area of study.
Conclusion
This study presents a novel approach to addressing the lack of accessible, annotated datasets for educational NLP tasks in low-resource languages. By leveraging machine translation, the researchers created TIGQA, a Tigrinya question-answering dataset that requires skills beyond simple word matching.
The TIGQA dataset is a significant step forward in the field of machine reading comprehension, as it provides a valuable testbed for evaluating state-of-the-art models on a challenging task in a low-resource language. The researchers' experiments and the comparison of model performance to human performance highlight the potential for further enhancements to the dataset through continued research.
The free availability of the TIGQA dataset is a crucial aspect of this work, as it encourages the research community to tackle the challenges in Tigrinya machine reading comprehension. This study serves as a model for similar efforts to bridge linguistic divides and expand the reach of NLP technologies to underserved languages and communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
TANQ: An open domain dataset of table answered questions
Mubashara Akhtar, Chenxi Pang, Andreea Marzoca, Yasemin Altun, Julian Martin Eisenschlos
0
0
Language models, potentially augmented with tool usage such as retrieval are becoming the go-to means of answering questions. Understanding and answering questions in real-world settings often requires retrieving information from different sources, processing and aggregating data to extract insights, and presenting complex findings in form of structured artifacts such as novel tables, charts, or infographics. In this paper, we introduce TANQ, the first open domain question answering dataset where the answers require building tables from information across multiple sources. We release the full source attribution for every cell in the resulting table and benchmark state-of-the-art language models in open, oracle, and closed book setups. Our best-performing baseline, GPT4 reaches an overall F1 score of 29.1, lagging behind human performance by 19.7 points. We analyse baselines' performance across different dataset attributes such as different skills required for this task, including multi-hop reasoning, math operations, and unit conversions. We further discuss common failures in model-generated answers, suggesting that TANQ is a complex task with many challenges ahead.
5/14/2024
↗️
UQA: Corpus for Urdu Question Answering
Samee Arif, Sualeha Farid, Awais Athar, Agha Ali Raza
0
0
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
5/3/2024
MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
Ruturaj Ghatage, Aditya Kulkarni, Rajlaxmi Patil, Sharvi Endait, Raviraj Joshi
0
0
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
4/23/2024
🌐
Can a Multichoice Dataset be Repurposed for Extractive Question Answering?
Teresa Lynn, Malik H. Altakrori, Samar Mohamed Magdy, Rocktim Jyoti Das, Chenyang Lyu, Mohamed Nasr, Younes Samih, Alham Fikri Aji, Preslav Nakov, Shantanu Godbole, Salim Roukos, Radu Florian, Nizar Habash
0
0
The rapid evolution of Natural Language Processing (NLP) has favored major languages such as English, leaving a significant gap for many others due to limited resources. This is especially evident in the context of data annotation, a task whose importance cannot be underestimated, but which is time-consuming and costly. Thus, any dataset for resource-poor languages is precious, in particular when it is task-specific. Here, we explore the feasibility of repurposing existing datasets for a new NLP task: we repurposed the Belebele dataset (Bandarkar et al., 2023), which was designed for multiple-choice question answering (MCQA), to enable extractive QA (EQA) in the style of machine reading comprehension. We present annotation guidelines and a parallel EQA dataset for English and Modern Standard Arabic (MSA). We also present QA evaluation results for several monolingual and cross-lingual QA pairs including English, MSA, and five Arabic dialects. Our aim is to enable others to adapt our approach for the 120+ other language variants in Belebele, many of which are deemed under-resourced. We also conduct a thorough analysis and share our insights from the process, which we hope will contribute to a deeper understanding of the challenges and the opportunities associated with task reformulation in NLP research.
4/29/2024