UQA: Corpus for Urdu Question Answering
2405.01458
0
0
↗️
Abstract
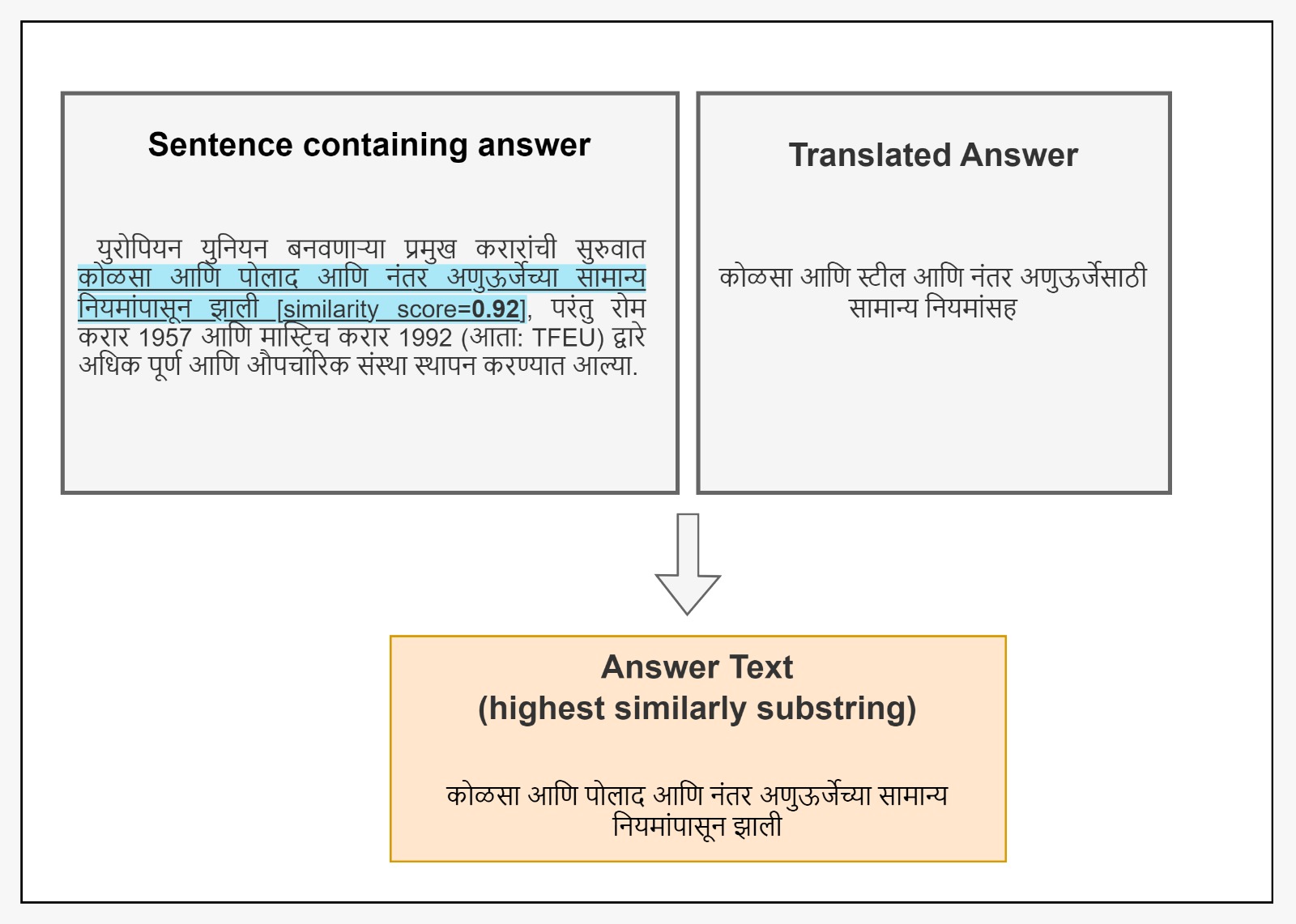
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
Create account to get full access
Overview
- This paper introduces UQA, a new dataset for question answering and text comprehension in Urdu, a language with over 70 million native speakers.
- UQA was created by translating the Stanford Question Answering Dataset (SQuAD2.0) from English to Urdu using a technique called EATS, which preserves the answer spans in the translated context paragraphs.
- The paper evaluates different translation models and benchmarks several state-of-the-art multilingual question answering models on the UQA dataset, reporting promising results.
- UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and enhancing the cross-lingual transferability of existing models.
Plain English Explanation
The paper describes the creation of a new dataset called UQA, which is designed to help computers better understand and answer questions in the Urdu language. Urdu is spoken by over 70 million people, but there aren't many large-scale datasets available for training and testing Urdu language models.
To create UQA, the researchers took an existing English question-answering dataset called SQuAD2.0 and translated it into Urdu using a special technique called EATS. This allowed them to preserve the original answer spans, making the dataset high-quality and useful for training models.
The researchers then tested several state-of-the-art multilingual question-answering models on the UQA dataset, and found that they performed well, with one model achieving an F1 score of 85.99 and an Exact Match score of 74.56. This suggests that the UQA dataset is a valuable resource for developing and improving Urdu language models.
By creating UQA, the researchers have provided a important tool for advancing natural language processing in Urdu, a language that has historically been underserved in this area of AI research. The dataset can also help enhance the ability of existing multilingual models to perform well on Urdu, bridging the gap between high-resource and low-resource languages.
Technical Explanation
The researchers used a technique called EATS (Enclose to Anchor, Translate, Seek) to translate the English SQuAD2.0 dataset into Urdu, preserving the answer spans in the translated context paragraphs. They evaluated two translation models, Google Translator and Seamless M4T, and selected the one that produced the best results.
The paper then benchmarks several state-of-the-art multilingual question answering models on the UQA dataset, including mBERT, XLM-RoBERTa, and mT5. They report promising results, with XLM-RoBERTa-XL achieving an F1 score of 85.99 and an Exact Match score of 74.56 on the UQA dataset.
The UQA dataset and the code used to create it are publicly available, making it a valuable resource for developing and testing multilingual NLP systems for Urdu and enhancing the cross-lingual transferability of existing models.
Critical Analysis
The paper provides a thorough explanation of the process used to create the UQA dataset and the evaluation of various multilingual question answering models on it. However, the paper does not discuss any potential limitations or caveats of the dataset or the translation process.
For example, it would be helpful to know how well the EATS technique performed in preserving the original meaning and nuance of the questions and answers during the translation process. Additionally, the paper does not address potential biases or inconsistencies that may have been introduced in the translated dataset.
Further research could explore the performance of the UQA dataset on a wider range of Urdu language models, including those specifically developed for the Urdu language, rather than focusing solely on multilingual models. This could provide deeper insights into the strengths and weaknesses of the dataset.
Overall, the UQA dataset is a valuable contribution to the field of multilingual natural language processing, but additional analysis and exploration of its limitations and potential use cases could strengthen the impact of this research.
Conclusion
The UQA dataset introduced in this paper is a significant contribution to the field of Urdu language processing. By creating a high-quality question-answering dataset for Urdu, the researchers have provided a valuable resource for developing and testing multilingual NLP models, as well as for enhancing the cross-lingual capabilities of existing models.
The promising results reported for state-of-the-art models on the UQA dataset suggest that it can be a useful tool for advancing Urdu language processing and bridging the gap between high-resource and low-resource languages in the field of natural language processing. The public availability of the dataset and code further enhances its potential impact on the research community.
While the paper could have delved deeper into the limitations and potential biases of the dataset, the UQA dataset represents an important step forward in making Urdu, a language with over 70 million native speakers, more accessible and useful for AI-powered applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
Ruturaj Ghatage, Aditya Kulkarni, Rajlaxmi Patil, Sharvi Endait, Raviraj Joshi
0
0
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
4/23/2024

Building Efficient and Effective OpenQA Systems for Low-Resource Languages
Emrah Budur, R{i}za Ozc{c}elik, Dilara Soylu, Omar Khattab, Tunga Gungor, Christopher Potts
0
0
Question answering (QA) is the task of answering questions posed in natural language with free-form natural language answers extracted from a given passage. In the OpenQA variant, only a question text is given, and the system must retrieve relevant passages from an unstructured knowledge source and use them to provide answers, which is the case in the mainstream QA systems on the Web. QA systems currently are mostly limited to the English language due to the lack of large-scale labeled QA datasets in non-English languages. In this paper, we show that effective, low-cost OpenQA systems can be developed for low-resource contexts. The key ingredients are (1) weak supervision using machine-translated labeled datasets and (2) a relevant unstructured knowledge source in the target language context. Furthermore, we show that only a few hundred gold assessment examples are needed to reliably evaluate these systems. We apply our method to Turkish as a challenging case study, since English and Turkish are typologically very distinct and Turkish has limited resources for QA. We present SQuAD-TR, a machine translation of SQuAD2.0, and we build our OpenQA system by adapting ColBERT-QA and retraining it over Turkish resources and SQuAD-TR using two versions of Wikipedia dumps spanning two years. We obtain a performance improvement of 24-32% in the Exact Match (EM) score and 22-29% in the F1 score compared to the BM25-based and DPR-based baseline QA reader models. Our results show that SQuAD-TR makes OpenQA feasible for Turkish, which we hope encourages researchers to build OpenQA systems in other low-resource languages. We make all the code, models, and the dataset publicly available at https://github.com/boun-tabi/SQuAD-TR.
6/6/2024
📈
Question-Answering (QA) Model for a Personalized Learning Assistant for Arabic Language
Mohammad Sammoudi, Ahmad Habaybeh, Huthaifa I. Ashqar, Mohammed Elhenawy
0
0
This paper describes the creation, optimization, and assessment of a question-answering (QA) model for a personalized learning assistant that uses BERT transformers customized for the Arabic language. The model was particularly finetuned on science textbooks in Palestinian curriculum. Our approach uses BERT's brilliant capabilities to automatically produce correct answers to questions in the field of science education. The model's ability to understand and extract pertinent information is improved by finetuning it using 11th and 12th grade biology book in Palestinian curriculum. This increases the model's efficacy in producing enlightening responses. Exact match (EM) and F1 score metrics are used to assess the model's performance; the results show an EM score of 20% and an F1 score of 51%. These findings show that the model can comprehend and react to questions in the context of Palestinian science book. The results demonstrate the potential of BERT-based QA models to support learning and understanding Arabic students questions.
6/14/2024
💬
LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yanfeng Wang, Yu Wang
0
0
While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.
4/19/2024