MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
2404.13364
0
0
Abstract
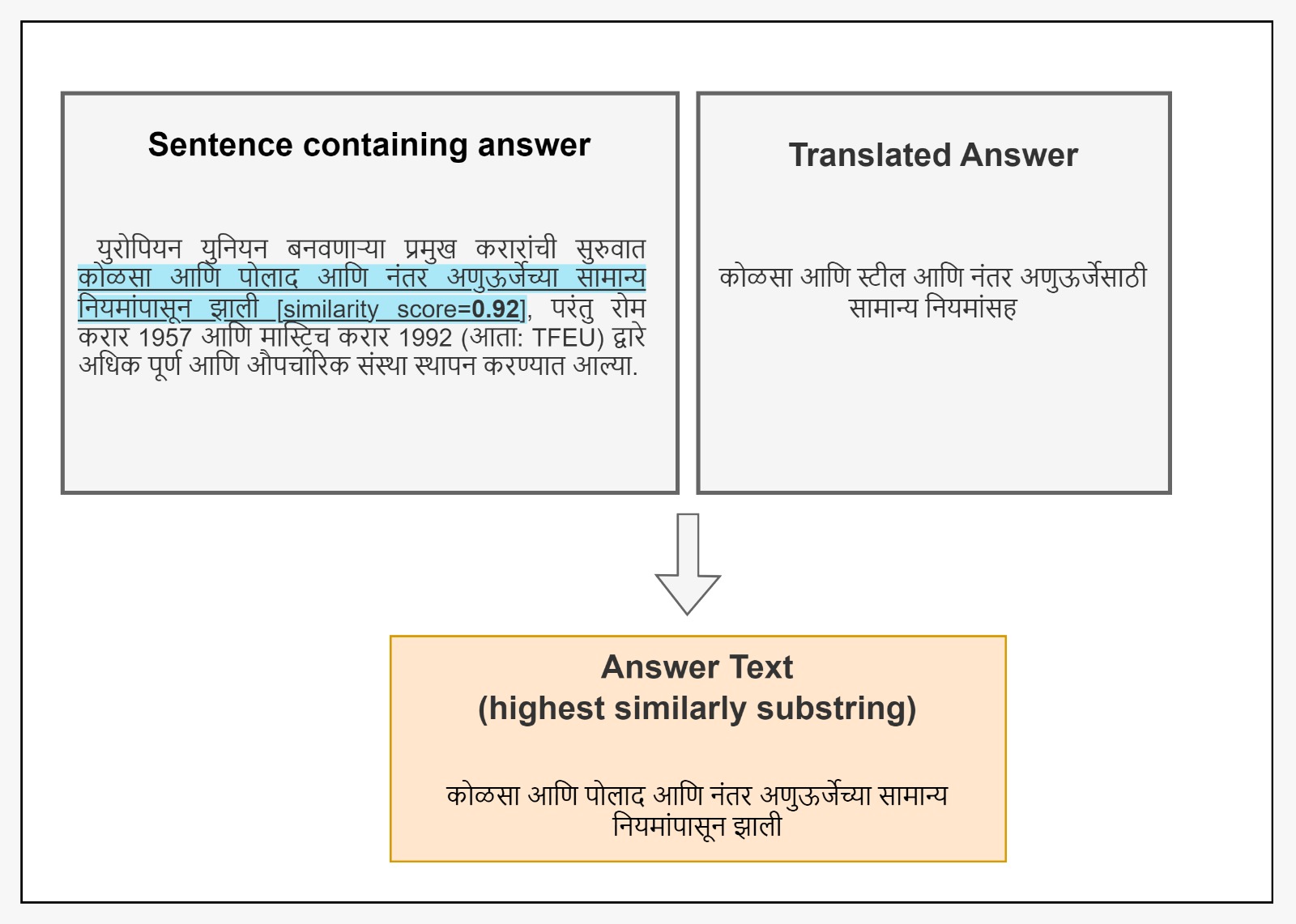
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
Create account to get full access
Overview
- This paper introduces MahaSQuAD, a large-scale question-answering dataset for Marathi, a major Indian language.
- The dataset aims to bridge the linguistic divide and facilitate the development of AI language models that can understand and respond to questions in Marathi.
- The paper describes the dataset creation process, benchmarking experiments, and key insights gained from the research.
Plain English Explanation
MahaSQuAD is a new dataset that helps computers better understand and answer questions in Marathi, a widely spoken language in India. Marathi is the official language of the state of Maharashtra and is the third most spoken language in India, but it has often been overlooked in the development of language AI.
The researchers created this dataset by collecting a large number of Marathi questions and answers, similar to the popular SQuAD dataset for English. They then used this data to train and test AI language models, measuring how well the models could understand and respond to Marathi questions.
The goal of this work is to help bridge the "linguistic divide" - the gap between the languages that are well-supported by language AI, like English, and those that are not, like Marathi. By creating high-quality datasets and benchmarks for Marathi, the researchers hope to spur the development of AI systems that can communicate fluently in this important Indian language.
Technical Explanation
The paper presents the MahaSQuAD dataset, a large-scale question-answering dataset for the Marathi language. The dataset contains over 45,000 context-question-answer triplets, covering a diverse range of topics.
To create the dataset, the researchers first collected a large corpus of Marathi text from various sources, including news articles, Wikipedia pages, and other online resources. They then used crowdsourcing to generate questions and answers based on the collected text. The questions cover a variety of question types, including factual, inferential, and open-ended questions.
The researchers benchmarked the performance of several state-of-the-art language models, including BERT and RoBERTa, on the MahaSQuAD dataset. The results showed that while the models performed reasonably well, there is still a significant performance gap compared to their performance on English-language datasets. This highlights the need for continued research and development to improve the language understanding capabilities of AI systems for low-resource languages like Marathi.
Critical Analysis
The MahaSQuAD dataset represents an important step forward in addressing the linguistic divide in language AI, particularly for the Marathi language. The researchers have done a commendable job in creating a large-scale, high-quality dataset that can serve as a valuable resource for the research community.
One potential limitation of the dataset is that it may not capture the full diversity of Marathi language usage, as the text sources were primarily from formal, written sources. It would be valuable to also include more colloquial or spoken Marathi language in future iterations of the dataset.
Additionally, the benchmarking experiments showed that current state-of-the-art language models still struggle to achieve human-level performance on the MahaSQuAD dataset. This suggests that there is significant room for improvement in developing AI systems that can truly understand and engage with Marathi language.
Future research could explore techniques such as data augmentation, transfer learning, or multilingual modeling approaches to further enhance the language understanding capabilities of AI systems for low-resource languages like Marathi.
Conclusion
The MahaSQuAD dataset represents an important contribution to the field of language AI, particularly in the context of bridging the linguistic divide for Marathi, a major Indian language. By creating a high-quality dataset and benchmarking the performance of state-of-the-art language models, the researchers have laid the groundwork for further advancements in Marathi language understanding and question-answering.
This work has the potential to have a significant impact, as it can help drive the development of AI-powered applications and services that can effectively communicate with Marathi-speaking users, ultimately improving access to information and services for this large and underserved population.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
UQA: Corpus for Urdu Question Answering
Samee Arif, Sualeha Farid, Awais Athar, Agha Ali Raza
0
0
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
5/3/2024
👁️
EuSQuAD: Automatically Translated and Aligned SQuAD2.0 for Basque
Aitor Garc'ia-Pablos, Naiara Perez, Montse Cuadros, Jaione Bengoetxea
0
0
The widespread availability of Question Answering (QA) datasets in English has greatly facilitated the advancement of the Natural Language Processing (NLP) field. However, the scarcity of such resources for minority languages, such as Basque, poses a substantial challenge for these communities. In this context, the translation and alignment of existing QA datasets plays a crucial role in narrowing this technological gap. This work presents EuSQuAD, the first initiative dedicated to automatically translating and aligning SQuAD2.0 into Basque, resulting in more than 142k QA examples. We demonstrate EuSQuAD's value through extensive qualitative analysis and QA experiments supported with EuSQuAD as training data. These experiments are evaluated with a new human-annotated dataset.
6/5/2024
🌀
Suvach -- Generated Hindi QA benchmark
Vaishak Narayanan, Prabin Raj KP, Saifudheen Nouphal
0
0
Current evaluation benchmarks for question answering (QA) in Indic languages often rely on machine translation of existing English datasets. This approach suffers from bias and inaccuracies inherent in machine translation, leading to datasets that may not reflect the true capabilities of EQA models for Indic languages. This paper proposes a new benchmark specifically designed for evaluating Hindi EQA models and discusses the methodology to do the same for any task. This method leverages large language models (LLMs) to generate a high-quality dataset in an extractive setting, ensuring its relevance for the target language. We believe this new resource will foster advancements in Hindi NLP research by providing a more accurate and reliable evaluation tool.
5/1/2024
mCSQA: Multilingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans
Yusuke Sakai, Hidetaka Kamigaito, Taro Watanabe
0
0
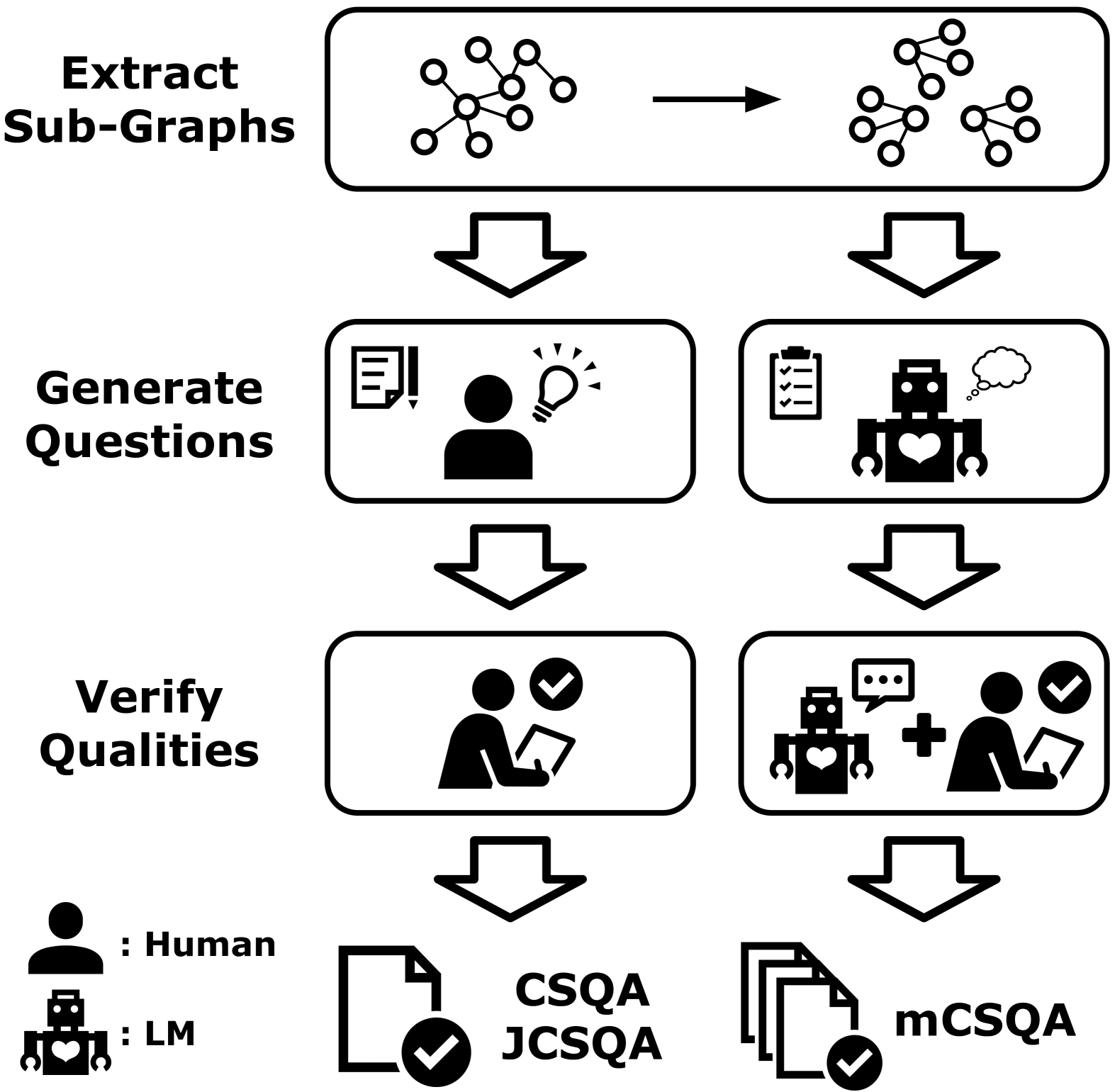
It is very challenging to curate a dataset for language-specific knowledge and common sense in order to evaluate natural language understanding capabilities of language models. Due to the limitation in the availability of annotators, most current multilingual datasets are created through translation, which cannot evaluate such language-specific aspects. Therefore, we propose Multilingual CommonsenseQA (mCSQA) based on the construction process of CSQA but leveraging language models for a more efficient construction, e.g., by asking LM to generate questions/answers, refine answers and verify QAs followed by reduced human efforts for verification. Constructed dataset is a benchmark for cross-lingual language-transfer capabilities of multilingual LMs, and experimental results showed high language-transfer capabilities for questions that LMs could easily solve, but lower transfer capabilities for questions requiring deep knowledge or commonsense. This highlights the necessity of language-specific datasets for evaluation and training. Finally, our method demonstrated that multilingual LMs could create QA including language-specific knowledge, significantly reducing the dataset creation cost compared to manual creation. The datasets are available at https://huggingface.co/datasets/yusuke1997/mCSQA.
6/7/2024