EuSQuAD: Automatically Translated and Aligned SQuAD2.0 for Basque
2404.12177
0
0
👁️
Abstract
The widespread availability of Question Answering (QA) datasets in English has greatly facilitated the advancement of the Natural Language Processing (NLP) field. However, the scarcity of such resources for minority languages, such as Basque, poses a substantial challenge for these communities. In this context, the translation and alignment of existing QA datasets plays a crucial role in narrowing this technological gap. This work presents EuSQuAD, the first initiative dedicated to automatically translating and aligning SQuAD2.0 into Basque, resulting in more than 142k QA examples. We demonstrate EuSQuAD's value through extensive qualitative analysis and QA experiments supported with EuSQuAD as training data. These experiments are evaluated with a new human-annotated dataset.
Create account to get full access
Overview
- This research paper addresses the challenge of the scarcity of question-answering (QA) datasets for minority languages like Basque.
- The authors present EuSQuAD, the first initiative to automatically translate and align the SQuAD2.0 dataset into Basque, resulting in over 142,000 QA examples.
- The paper demonstrates the value of EuSQuAD through qualitative analysis and QA experiments, using a new human-annotated dataset for evaluation.
Plain English Explanation
Question-answering (QA) is an important task in natural language processing (NLP) that involves answering questions based on given text. Datasets like SQuAD have greatly advanced the field of NLP in English, but similar resources are scarce for minority languages like Basque.
To address this gap, the researchers created EuSQuAD, which automatically translates and aligns the SQuAD2.0 dataset into Basque. This resulted in over 142,000 QA examples that can be used to train and evaluate Basque language models.
The researchers demonstrate the value of EuSQuAD through extensive analysis and experiments. They show that QA models trained on EuSQuAD perform well on a new human-annotated Basque QA dataset, indicating that the translated dataset is a useful resource for the Basque NLP community.
Technical Explanation
The paper presents EuSQuAD, the first initiative to automatically translate and align the SQuAD2.0 question-answering dataset into Basque. SQuAD2.0 is a widely-used English QA dataset, but the scarcity of such resources for minority languages like Basque has hindered progress in these communities.
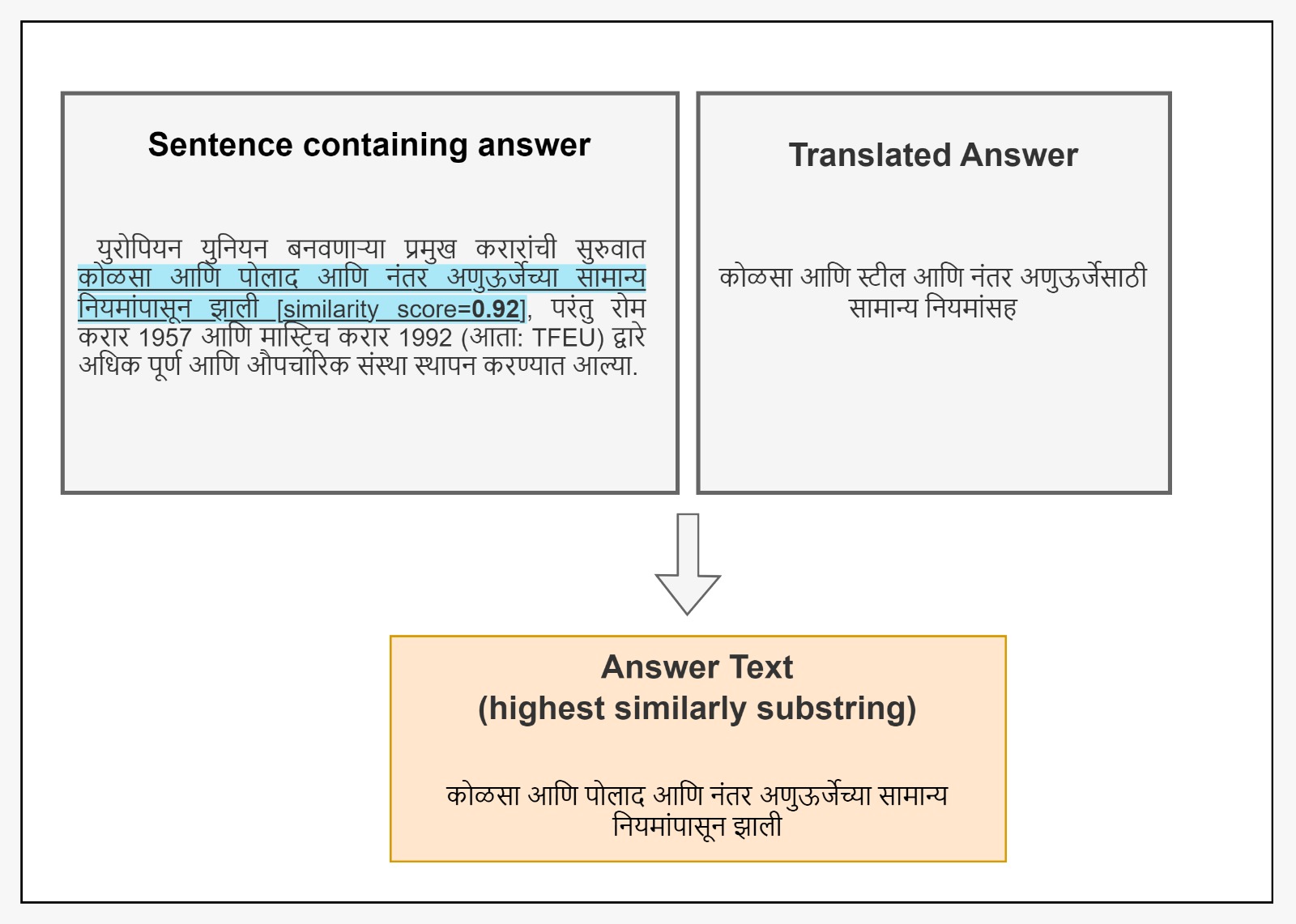
The authors used machine translation to translate the SQuAD2.0 passages and questions into Basque, and then employed automatic alignment techniques to pair the translated questions with their corresponding answers in the Basque text. This resulted in a dataset of over 142,000 QA examples.
To evaluate the quality and usefulness of EuSQuAD, the researchers conducted both qualitative analysis and QA experiments. The qualitative analysis involved human evaluation of the translations, while the QA experiments trained models on EuSQuAD and tested them on a new human-annotated Basque QA dataset. The results demonstrate the value of EuSQuAD as a resource for the Basque NLP community.
Critical Analysis
The paper provides a valuable contribution by addressing the lack of QA datasets for minority languages like Basque. The authors acknowledge the limitations of their automatic translation and alignment approach, which may introduce some noise or errors into the EuSQuAD dataset.
Further research could explore more sophisticated techniques for translating and aligning QA datasets, potentially involving human curation or cross-lingual transfer learning. Additionally, the authors suggest that the EuSQuAD dataset could be expanded by incorporating other Basque language resources.
Overall, the paper presents a solid approach for creating a useful QA dataset for the Basque language, and the experiments demonstrate its value as a training and evaluation resource. The work serves as an important step in narrowing the technological gap for minority language communities.
Conclusion
This research paper introduces EuSQuAD, the first initiative to automatically translate and align the SQuAD2.0 question-answering dataset into Basque. The resulting dataset of over 142,000 QA examples represents a valuable resource for the Basque NLP community, as demonstrated through extensive qualitative and quantitative analyses.
By addressing the scarcity of QA datasets for minority languages, this work contributes to the advancement of natural language processing in underrepresented communities. The EuSQuAD dataset can be used to train and evaluate Basque language models, helping to bridge the technological gap and unlock new opportunities for Basque NLP research and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
Ruturaj Ghatage, Aditya Kulkarni, Rajlaxmi Patil, Sharvi Endait, Raviraj Joshi
0
0
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
4/23/2024
↗️
UQA: Corpus for Urdu Question Answering
Samee Arif, Sualeha Farid, Awais Athar, Agha Ali Raza
0
0
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
5/3/2024
📈
Datasets for Multilingual Answer Sentence Selection
Matteo Gabburo, Stefano Campese, Federico Agostini, Alessandro Moschitti
0
0
Answer Sentence Selection (AS2) is a critical task for designing effective retrieval-based Question Answering (QA) systems. Most advancements in AS2 focus on English due to the scarcity of annotated datasets for other languages. This lack of resources prevents the training of effective AS2 models in different languages, creating a performance gap between QA systems in English and other locales. In this paper, we introduce new high-quality datasets for AS2 in five European languages (French, German, Italian, Portuguese, and Spanish), obtained through supervised Automatic Machine Translation (AMT) of existing English AS2 datasets such as ASNQ, WikiQA, and TREC-QA using a Large Language Model (LLM). We evaluated our approach and the quality of the translated datasets through multiple experiments with different Transformer architectures. The results indicate that our datasets are pivotal in producing robust and powerful multilingual AS2 models, significantly contributing to closing the performance gap between English and other languages.
6/17/2024

Building Efficient and Effective OpenQA Systems for Low-Resource Languages
Emrah Budur, R{i}za Ozc{c}elik, Dilara Soylu, Omar Khattab, Tunga Gungor, Christopher Potts
0
0
Question answering (QA) is the task of answering questions posed in natural language with free-form natural language answers extracted from a given passage. In the OpenQA variant, only a question text is given, and the system must retrieve relevant passages from an unstructured knowledge source and use them to provide answers, which is the case in the mainstream QA systems on the Web. QA systems currently are mostly limited to the English language due to the lack of large-scale labeled QA datasets in non-English languages. In this paper, we show that effective, low-cost OpenQA systems can be developed for low-resource contexts. The key ingredients are (1) weak supervision using machine-translated labeled datasets and (2) a relevant unstructured knowledge source in the target language context. Furthermore, we show that only a few hundred gold assessment examples are needed to reliably evaluate these systems. We apply our method to Turkish as a challenging case study, since English and Turkish are typologically very distinct and Turkish has limited resources for QA. We present SQuAD-TR, a machine translation of SQuAD2.0, and we build our OpenQA system by adapting ColBERT-QA and retraining it over Turkish resources and SQuAD-TR using two versions of Wikipedia dumps spanning two years. We obtain a performance improvement of 24-32% in the Exact Match (EM) score and 22-29% in the F1 score compared to the BM25-based and DPR-based baseline QA reader models. Our results show that SQuAD-TR makes OpenQA feasible for Turkish, which we hope encourages researchers to build OpenQA systems in other low-resource languages. We make all the code, models, and the dataset publicly available at https://github.com/boun-tabi/SQuAD-TR.
6/6/2024