MultiCast: Zero-Shot Multivariate Time Series Forecasting Using LLMs
2405.14748
0
0
🎯
Abstract
Predicting future values in multivariate time series is vital across various domains. This work explores the use of large language models (LLMs) for this task. However, LLMs typically handle one-dimensional data. We introduce MultiCast, a zero-shot LLM-based approach for multivariate time series forecasting. It allows LLMs to receive multivariate time series as input, through three novel token multiplexing solutions that effectively reduce dimensionality while preserving key repetitive patterns. Additionally, a quantization scheme helps LLMs to better learn these patterns, while significantly reducing token use for practical applications. We showcase the performance of our approach in terms of RMSE and execution time against state-of-the-art approaches on three real-world datasets.
Create account to get full access
Overview
- Predicting future values in multivariate time series is crucial across many industries.
- This paper explores using large language models (LLMs) for this task.
- LLMs typically handle one-dimensional data, so the authors introduce MultiCast, a zero-shot LLM-based approach for multivariate time series forecasting.
- MultiCast uses novel token multiplexing solutions to allow LLMs to process multivariate inputs while preserving key patterns.
- It also employs a quantization scheme to help LLMs better learn these patterns and reduce token use for practical applications.
- The authors demonstrate MultiCast's performance against state-of-the-art methods on three real-world datasets.
Plain English Explanation
Predicting future values in complex, multi-variable data series (like stock prices, weather patterns, or inventory levels) is essential for decision-making in many fields. However, the powerful language models commonly used for this task are typically limited to handling one-dimensional data.
The researchers developed a new approach called MultiCast that allows these language models to work with multi-variable data. MultiCast uses clever techniques to "pack" the multiple variables into a format the models can understand, while still preserving the important repeating patterns in the data.
Additionally, MultiCast includes a "quantization" step that helps the language models better recognize and learn these patterns, while also reducing the amount of data the models need to process - making the approach more practical for real-world use.
The authors show that MultiCast outperforms other state-of-the-art methods for forecasting on three different real-world datasets, in terms of both accuracy (root mean squared error) and speed.
Technical Explanation
The authors introduce MultiCast, a zero-shot large language model (LLM)-based approach for multivariate time series forecasting. LLMs typically handle one-dimensional data, so MultiCast uses three novel token multiplexing solutions to allow them to process multivariate inputs:
- Concatenation: Concatenating all variables into a single sequence.
- Interleaving: Interleaving the variables into a single sequence.
- Parallel: Passing each variable as a separate sequence to the LLM.
These techniques effectively reduce the dimensionality of the input while preserving the key repetitive patterns. Additionally, MultiCast employs a quantization scheme to help the LLM better learn these patterns, while significantly reducing token use for practical applications.
The authors evaluate MultiCast's performance on three real-world datasets, comparing it to state-of-the-art approaches like Tiny Time Mixers (TTMs), Mixture of Linear Experts, and Decoder-Only Foundation Models. They demonstrate that MultiCast outperforms these methods in terms of root mean squared error (RMSE) and execution time.
Critical Analysis
The authors acknowledge several limitations of their work:
- The performance of MultiCast may vary depending on the specific characteristics of the dataset, such as the number of variables and the complexity of the underlying patterns.
- The quantization scheme used in MultiCast may not be optimal for all types of data, and further research is needed to explore more advanced quantization techniques.
- The authors only evaluate MultiCast on three real-world datasets, and more extensive testing on a wider range of datasets would be beneficial to fully assess the approach's generalizability.
Additionally, one potential concern is that the authors do not provide a detailed analysis of the computational and memory requirements of MultiCast compared to the baseline methods. This information would be useful for understanding the practical trade-offs and limitations of the approach, especially for real-world applications with resource constraints.
Overall, the MultiCast approach represents an interesting and potentially valuable contribution to the field of multivariate time series forecasting using large language models. However, further research and evaluation would be helpful to better understand the approach's strengths, weaknesses, and applicability across a broader range of scenarios.
Conclusion
This paper introduces MultiCast, a novel zero-shot large language model (LLM)-based approach for multivariate time series forecasting. MultiCast uses innovative token multiplexing techniques to allow LLMs to process multi-variable data while preserving key patterns, and it employs a quantization scheme to improve the models' learning and reduce computational requirements.
The authors demonstrate that MultiCast outperforms state-of-the-art methods in terms of accuracy and execution time on three real-world datasets. This research represents an important step towards leveraging the power of large language models for more complex, multi-dimensional forecasting tasks, with potential applications across a wide range of industries and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Language Models Are Zero-Shot Time Series Forecasters
Nate Gruver, Marc Finzi, Shikai Qiu, Andrew Gordon Wilson
0
0
By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks. To facilitate this performance, we propose procedures for effectively tokenizing time series data and converting discrete distributions over tokens into highly flexible densities over continuous values. We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends. We also show how LLMs can naturally handle missing data without imputation through non-numerical text, accommodate textual side information, and answer questions to help explain predictions. While we find that increasing model size generally improves performance on time series, we show GPT-4 can perform worse than GPT-3 because of how it tokenizes numbers, and poor uncertainty calibration, which is likely the result of alignment interventions such as RLHF.
6/19/2024
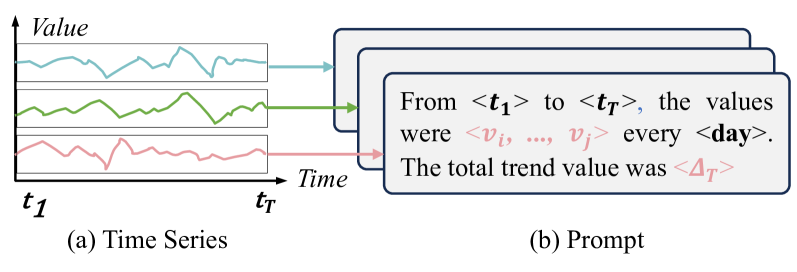
TimeCMA: Towards LLM-Empowered Time Series Forecasting via Cross-Modality Alignment
Chenxi Liu, Qianxiong Xu, Hao Miao, Sun Yang, Lingzheng Zhang, Cheng Long, Ziyue Li, Rui Zhao
0
0
The widespread adoption of scalable mobile sensing has led to large amounts of time series data for real-world applications. A fundamental application is multivariate time series forecasting (MTSF), which aims to predict future time series values based on historical observations. Existing MTSF methods suffer from limited parameterization and small-scale training data. Recently, Large language models (LLMs) have been introduced in time series, which achieve promising forecasting performance but incur heavy computational costs. To solve these challenges, we propose TimeCMA, an LLM-empowered framework for time series forecasting with cross-modality alignment. We design a dual-modality encoding module with two branches, where the time series encoding branch extracts relatively low-quality yet pure embeddings of time series through an inverted Transformer. In addition, the LLM-empowered encoding branch wraps the same time series as prompts to obtain high-quality yet entangled prompt embeddings via a Pre-trained LLM. Then, we design a cross-modality alignment module to retrieve high-quality and pure time series embeddings from the prompt embeddings. Moreover, we develop a time series forecasting module to decode the aligned embeddings while capturing dependencies among multiple variables for forecasting. Notably, we tailor the prompt to encode sufficient temporal information into a last token and design the last token embedding storage to reduce computational costs. Extensive experiments on real data offer insight into the accuracy and efficiency of the proposed framework.
6/17/2024
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024
💬
AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, Mingsheng Long
0
0
Foundation models of time series have not been fully developed due to the limited availability of time series corpora and the underexploration of scalable pre-training. Based on the similar sequential formulation of time series and natural language, increasing research demonstrates the feasibility of leveraging large language models (LLM) for time series. Nevertheless, the inherent autoregressive property and decoder-only architecture of LLMs have not been fully considered, resulting in insufficient utilization of LLM abilities. To further exploit the general-purpose token transition and multi-step generation ability of large language models, we propose AutoTimes to repurpose LLMs as autoregressive time series forecasters, which independently projects time series segments into the embedding space and autoregressively generates future predictions with arbitrary lengths. Compatible with any decoder-only LLMs, the consequent forecaster exhibits the flexibility of the lookback length and scalability of the LLM size. Further, we formulate time series as prompts, extending the context for prediction beyond the lookback window, termed in-context forecasting. By adopting textual timestamps as position embeddings, AutoTimes integrates multimodality for multivariate scenarios. Empirically, AutoTimes achieves state-of-the-art with 0.1% trainable parameters and over 5 times training/inference speedup compared to advanced LLM-based forecasters.
5/24/2024