Too Many Frames, not all Useful:Efficient Strategies for Long-Form Video QA
2406.09396
0
0

Abstract
Long-form videos that span across wide temporal intervals are highly information redundant and contain multiple distinct events or entities that are often loosely-related. Therefore, when performing long-form video question answering (LVQA),all information necessary to generate a correct response can often be contained within a small subset of frames. Recent literature explore the use of large language models (LLMs) in LVQA benchmarks, achieving exceptional performance, while relying on vision language models (VLMs) to convert all visual content within videos into natural language. Such VLMs often independently caption a large number of frames uniformly sampled from long videos, which is not efficient and can mostly be redundant. Questioning these decision choices, we explore optimal strategies for key-frame selection and sequence-aware captioning, that can significantly reduce these redundancies. We propose two novel approaches that improve each of aspects, namely Hierarchical Keyframe Selector and Sequential Visual LLM. Our resulting framework termed LVNet achieves state-of-the-art performance across three benchmark LVQA datasets. Our code will be released publicly.
Create account to get full access
Overview
- This paper introduces a new approach called "Hierarchical Vision-Language Prompting for Long-form Video Understanding" that aims to improve the ability of language models to understand and process long-form video content.
- The key idea is to use a hierarchical prompting strategy that breaks down the video into smaller, more manageable segments, and then uses language models to understand and summarize the content of each segment.
- The paper presents experimental results showing that this hierarchical approach outperforms traditional end-to-end video understanding models on a variety of benchmarks, particularly for longer and more complex videos.
Plain English Explanation
The paper proposes a new way to help computers better understand long videos. The problem is that current AI models can struggle to comprehend the full context and meaning of lengthy video content. To address this, the researchers developed a "hierarchical" approach that breaks down the video into smaller, more manageable pieces.
The idea is to use language models - the same type of AI that powers chatbots and text generation - to analyze each short segment of the video, and then piece together the insights from all the segments to get a comprehensive understanding of the full video. This hierarchical approach allows the language models to focus on the details of each part, rather than trying to process the entire video at once, which can be overwhelming.
The researchers tested this method on a variety of video understanding tasks, and found that it outperformed traditional end-to-end video AI models, particularly for longer and more complex videos. This suggests that the hierarchical vision-language prompting approach could be a valuable tool for applications like video summarization, video retrieval, and video question answering.
Technical Explanation
The paper introduces a new "Hierarchical Vision-Language Prompting" (HVLP) approach for long-form video understanding. The key idea is to break down the video into a hierarchy of semantically-meaningful segments, and then use large language models to analyze the content of each segment individually.
At the top level, the video is divided into a sequence of "key frames" that capture the high-level structure and flow of the video. Each key frame is then associated with a natural language prompt that summarizes the key events and semantics of that video segment. These prompts are fed into a language model, which generates a concise textual summary of the content.
The language model outputs are then aggregated and used to guide the analysis of the lower-level video segments between the key frames. Here, finer-grained prompts are used to extract more detailed information about the activities, objects, and relationships present in each sub-segment of the video.
The researchers evaluated HVLP on a range of long-form video understanding benchmarks, including video question answering, video summarization, and video retrieval tasks. Compared to end-to-end video models like KOALA and EnCoGS, the hierarchical prompting approach demonstrated superior performance, especially for longer and more complex videos.
The authors attribute this to the ability of HVLP to better capture the rich semantic structure of long videos, without becoming overwhelmed by the sheer volume of low-level visual and temporal information. The hierarchical organization and language-based prompting allows the model to reason about the video content at multiple levels of abstraction.
Critical Analysis
The HVLP approach presented in this paper is a promising step forward in addressing the challenges of long-form video understanding. By breaking down the video into a hierarchy of semantically meaningful segments and using language models to analyze the content, the method is able to overcome some of the limitations of traditional end-to-end video models.
However, the paper does not fully explore the limitations and potential issues with this approach. For example, the hierarchical structure and prompting strategy rely heavily on the quality and accuracy of the key frame extraction and text summarization. If these lower-level components fail to capture the essential semantics of the video segments, it could lead to cascading errors in the overall understanding.
Additionally, the paper does not address the potential computational and memory overhead of the hierarchical approach, particularly for very long videos with many levels of abstraction. This could be a concern for real-world applications where efficiency and scalability are important.
Further research is also needed to understand the generalization capabilities of HVLP, and how it might perform on a wider range of video understanding tasks and datasets. The experiments in this paper, while promising, are relatively limited in scope.
Overall, the HVLP method represents an interesting and valuable contribution to the field of long-form video understanding. However, as with any new technique, it will be important to continue exploring its limitations, tradeoffs, and potential areas for improvement through additional research and experimentation.
Conclusion
This paper introduces a new "Hierarchical Vision-Language Prompting" approach for improving the ability of language models to understand and process long-form video content. By breaking down the video into a hierarchy of semantically meaningful segments and using language models to analyze each segment individually, the method is able to capture the rich structure and semantics of lengthy videos more effectively than traditional end-to-end video models.
The experimental results demonstrate the potential of this hierarchical approach, showing improvements on a variety of video understanding benchmarks, particularly for longer and more complex videos. While the paper does not fully explore the limitations and tradeoffs of the HVLP method, it represents an important step forward in addressing the challenges of long-form video understanding.
As AI systems continue to play a larger role in processing and interpreting video content, techniques like HVLP will become increasingly important for enabling machines to truly comprehend the full context and meaning of lengthy, real-world video data. This could have significant implications for applications ranging from video summarization and retrieval to video-based question answering and reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
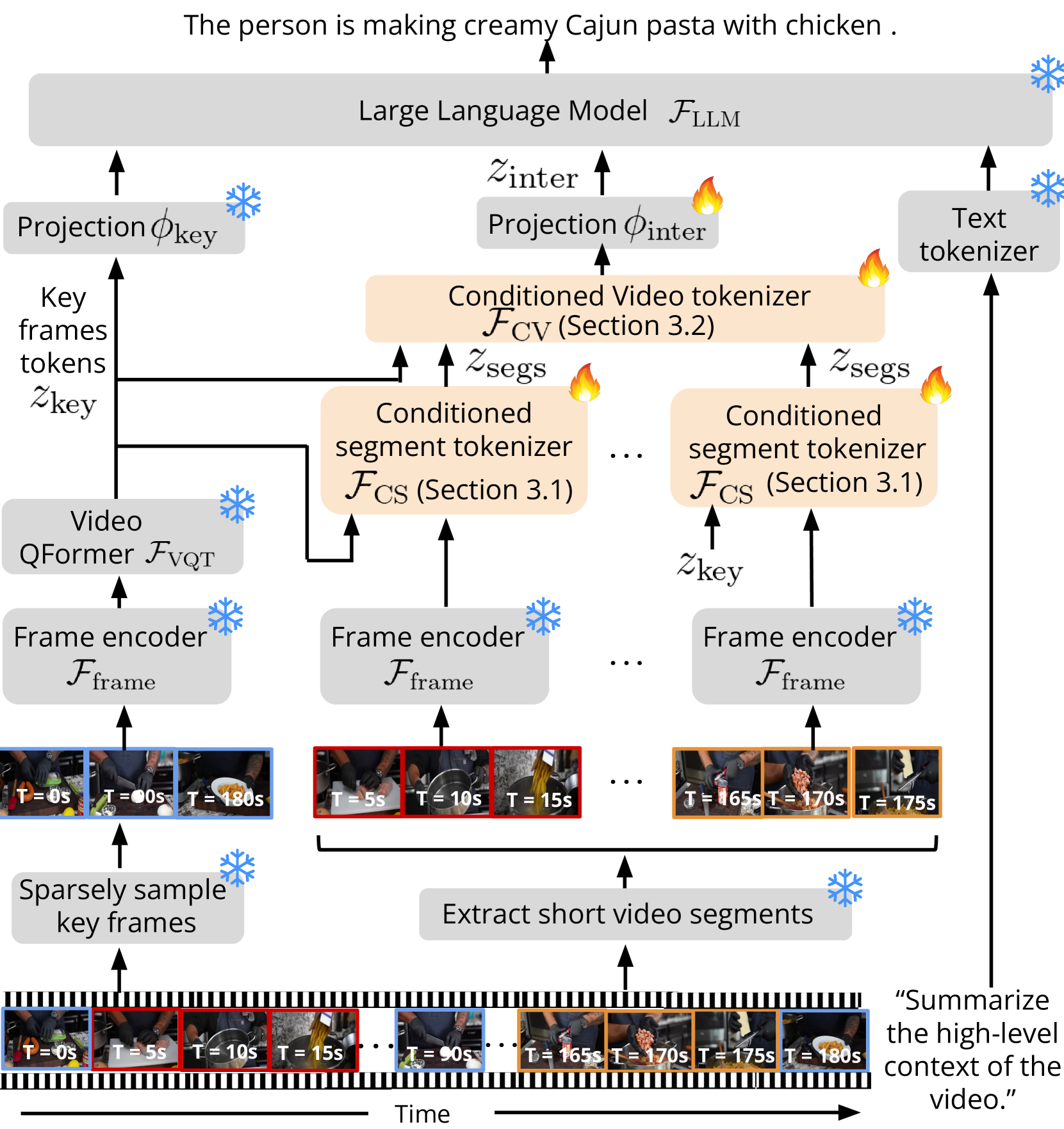
Koala: Key frame-conditioned long video-LLM
Reuben Tan, Ximeng Sun, Ping Hu, Jui-hsien Wang, Hanieh Deilamsalehy, Bryan A. Plummer, Bryan Russell, Kate Saenko
0
0
Long video question answering is a challenging task that involves recognizing short-term activities and reasoning about their fine-grained relationships. State-of-the-art video Large Language Models (vLLMs) hold promise as a viable solution due to their demonstrated emergent capabilities on new tasks. However, despite being trained on millions of short seconds-long videos, vLLMs are unable to understand minutes-long videos and accurately answer questions about them. To address this limitation, we propose a lightweight and self-supervised approach, Key frame-conditioned long video-LLM (Koala), that introduces learnable spatiotemporal queries to adapt pretrained vLLMs for generalizing to longer videos. Our approach introduces two new tokenizers that condition on visual tokens computed from sparse video key frames for understanding short and long video moments. We train our proposed approach on HowTo100M and demonstrate its effectiveness on zero-shot long video understanding benchmarks, where it outperforms state-of-the-art large models by 3 - 6% in absolute accuracy across all tasks. Surprisingly, we also empirically show that our approach not only helps a pretrained vLLM to understand long videos but also improves its accuracy on short-term action recognition.
5/7/2024

Encoding and Controlling Global Semantics for Long-form Video Question Answering
Thong Thanh Nguyen, Zhiyuan Hu, Xiaobao Wu, Cong-Duy T Nguyen, See-Kiong Ng, Anh Tuan Luu
0
0
Seeking answers effectively for long videos is essential to build video question answering (videoQA) systems. Previous methods adaptively select frames and regions from long videos to save computations. However, this fails to reason over the whole sequence of video, leading to sub-optimal performance. To address this problem, we introduce a state space layer (SSL) into multi-modal Transformer to efficiently integrate global semantics of the video, which mitigates the video information loss caused by frame and region selection modules. Our SSL includes a gating unit to enable controllability over the flow of global semantics into visual representations. To further enhance the controllability, we introduce a cross-modal compositional congruence (C^3) objective to encourage global semantics aligned with the question. To rigorously evaluate long-form videoQA capacity, we construct two new benchmarks Ego-QA and MAD-QA featuring videos of considerably long length, i.e. 17.5 minutes and 1.9 hours, respectively. Extensive experiments demonstrate the superiority of our framework on these new as well as existing datasets.
5/31/2024
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
0
0
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
4/11/2024

VideoTree: Adaptive Tree-based Video Representation for LLM Reasoning on Long Videos
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, Mohit Bansal
0
0
Video-language understanding tasks have focused on short video clips, often struggling with long-form video understanding tasks. Recently, many long video-language understanding approaches have leveraged the reasoning capabilities of Large Language Models (LLMs) to perform long video QA, transforming videos into densely sampled frame captions, and asking LLMs to respond to text queries over captions. However, the frames used for captioning are often redundant and contain irrelevant information, making dense sampling inefficient, and ignoring the fact that video QA requires varying levels of granularity, with some video segments being highly relevant to the question (needing more fine-grained detail) while others being less relevant. Thus, these LLM-based approaches are prone to missing information and operate on large numbers of irrelevant captions, lowering both performance and efficiency. To address these issues, we introduce VideoTree, a query-adaptive and hierarchical framework for long-video understanding with LLMs. VideoTree dynamically extracts query-related information from a video and builds a tree-based representation for LLM reasoning. First, VideoTree adaptively selects frames for captioning by iteratively clustering frames based on their visual features and scoring clusters using their relevance to the query. Second, it organizes visual clusters into a query-adaptive and hierarchical tree structure; the tree encodes varying levels of granularity, with higher resolution on relevant segments. Finally, VideoTree produces an answer by traversing the tree's keyframes and passing their captions to an LLM answerer. Our method improves both reasoning accuracy and efficiency compared to existing methods: VideoTree achieves a 7.0%, 2.2%, and 2.7% accuracy gain over baselines on the EgoSchema, NExT-QA, and IntentQA benchmarks, respectively, while reducing inference time by 40%.
5/30/2024