Encoding and Controlling Global Semantics for Long-form Video Question Answering
2405.19723
0
0

Abstract
Seeking answers effectively for long videos is essential to build video question answering (videoQA) systems. Previous methods adaptively select frames and regions from long videos to save computations. However, this fails to reason over the whole sequence of video, leading to sub-optimal performance. To address this problem, we introduce a state space layer (SSL) into multi-modal Transformer to efficiently integrate global semantics of the video, which mitigates the video information loss caused by frame and region selection modules. Our SSL includes a gating unit to enable controllability over the flow of global semantics into visual representations. To further enhance the controllability, we introduce a cross-modal compositional congruence (C^3) objective to encourage global semantics aligned with the question. To rigorously evaluate long-form videoQA capacity, we construct two new benchmarks Ego-QA and MAD-QA featuring videos of considerably long length, i.e. 17.5 minutes and 1.9 hours, respectively. Extensive experiments demonstrate the superiority of our framework on these new as well as existing datasets.
Create account to get full access
Overview
- This paper proposes a novel method for long-form video question answering that aims to capture global semantics and control them during the question answering process.
- The authors introduce a new model architecture and training approach to address the challenges of long-form video understanding, which is crucial for real-world applications like intelligent assistants and educational tools.
- The model leverages large-scale video-text pretraining and novel contrastive objectives to learn rich representations that can be effectively used for question answering.
Plain English Explanation
The paper focuses on the task of answering questions about long video clips, which can be quite challenging. When watching a lengthy video, it can be difficult to remember all the important details and understand the overall meaning. The researchers developed a new AI model that tries to address this problem.
The key idea is to have the model learn a deep understanding of the global semantics or overall meaning of the video, not just the details of individual scenes. This allows the model to better answer questions that require reasoning about the big picture, rather than just recalling specific events.
To achieve this, the model uses a specialized architecture and training approach. It leverages large datasets of video and text to pre-train powerful representations of the video content. Then, it uses novel "contrastive" training objectives to ensure the model captures the global semantics in a way that is useful for question answering.
The end result is a model that can more effectively answer questions about long videos, going beyond just remembering the video's details. This has important applications in areas like intelligent assistants and educational tools, where being able to deeply understand video content is crucial.
Technical Explanation
The paper introduces a new model architecture and training approach for long-form video question answering. The key components are:
-
Multimodal Video-Text Encoder: The model uses a transformer-based encoder to jointly represent the video and question, leveraging [object Object] and [object Object] pretraining to capture rich multimodal semantics.
-
Global Semantics Encoding: To capture the overall meaning of the video, the model uses a [object Object]-inspired key-frame conditioned mechanism to model global video semantics.
-
Contrastive Training Objectives: The model is trained using novel contrastive losses that encourage the learned representations to be useful for question answering, building on ideas from [object Object].
Through this architecture and training approach, the model is able to effectively encode and control the global semantics of long videos, leading to strong performance on video question answering benchmarks.
Critical Analysis
The paper presents a compelling approach to the challenging problem of long-form video question answering. The authors' focus on capturing global semantics is well-motivated, as this is a key limitation of many existing models.
However, the paper does not fully address the potential downsides or limitations of the proposed approach. For example, the high computational cost of the key-frame conditioned mechanism may limit the scalability of the model, and the reliance on extensive pretraining may make the approach difficult to apply in low-resource settings.
Additionally, the paper does not discuss potential social or ethical implications of deploying such a powerful video understanding model in real-world applications. Issues around bias, privacy, and responsible AI development should be carefully considered.
Overall, the technical innovations presented in the paper are promising, but more research is needed to fully understand the tradeoffs and limitations of the approach.
Conclusion
This paper tackles the important problem of long-form video question answering by introducing a novel model architecture and training approach focused on capturing and controlling global video semantics. The key innovations include a multimodal video-text encoder, a global semantics encoding mechanism, and contrastive training objectives.
The proposed model demonstrates strong performance on video question answering benchmarks, suggesting that the emphasis on global understanding is a valuable direction for this task. If successfully deployed, such models could significantly improve the capabilities of intelligent assistants, educational tools, and other applications that rely on deep video comprehension.
However, the paper also highlights the need for further research to address the potential limitations and social implications of this technology. By continuing to advance the state of the art in long-form video understanding while also considering the broader societal impact, the field can work towards developing AI systems that are both technically sophisticated and responsibly designed.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Too Many Frames, not all Useful:Efficient Strategies for Long-Form Video QA
Jongwoo Park, Kanchana Ranasinghe, Kumara Kahatapitiya, Wonjeong Ryoo, Donghyun Kim, Michael S. Ryoo
0
0
Long-form videos that span across wide temporal intervals are highly information redundant and contain multiple distinct events or entities that are often loosely-related. Therefore, when performing long-form video question answering (LVQA),all information necessary to generate a correct response can often be contained within a small subset of frames. Recent literature explore the use of large language models (LLMs) in LVQA benchmarks, achieving exceptional performance, while relying on vision language models (VLMs) to convert all visual content within videos into natural language. Such VLMs often independently caption a large number of frames uniformly sampled from long videos, which is not efficient and can mostly be redundant. Questioning these decision choices, we explore optimal strategies for key-frame selection and sequence-aware captioning, that can significantly reduce these redundancies. We propose two novel approaches that improve each of aspects, namely Hierarchical Keyframe Selector and Sequential Visual LLM. Our resulting framework termed LVNet achieves state-of-the-art performance across three benchmark LVQA datasets. Our code will be released publicly.
6/18/2024

Weakly Supervised Gaussian Contrastive Grounding with Large Multimodal Models for Video Question Answering
Haibo Wang, Chenghang Lai, Yixuan Sun, Weifeng Ge
0
0
Video Question Answering (VideoQA) aims to answer natural language questions based on the information observed in videos. Despite the recent success of Large Multimodal Models (LMMs) in image-language understanding and reasoning, they deal with VideoQA insufficiently, by simply taking uniformly sampled frames as visual inputs, which ignores question-relevant visual clues. Moreover, there are no human annotations for question-critical timestamps in existing VideoQA datasets. In light of this, we propose a novel weakly supervised framework to enforce the LMMs to reason out the answers with question-critical moments as visual inputs. Specifically, we first fuse the question and answer pairs as event descriptions to find multiple keyframes as target moments and pseudo-labels, with the visual-language alignment capability of the CLIP models. With these pseudo-labeled keyframes as additionally weak supervision, we devise a lightweight Gaussian-based Contrastive Grounding (GCG) module. GCG learns multiple Gaussian functions to characterize the temporal structure of the video, and sample question-critical frames as positive moments to be the visual inputs of LMMs. Extensive experiments on several benchmarks verify the effectiveness of our framework, and we achieve substantial improvements compared to previous state-of-the-art methods.
4/29/2024
🗣️
WorldQA: Multimodal World Knowledge in Videos through Long-Chain Reasoning
Yuanhan Zhang, Kaichen Zhang, Bo Li, Fanyi Pu, Christopher Arif Setiadharma, Jingkang Yang, Ziwei Liu
0
0
Multimodal information, together with our knowledge, help us to understand the complex and dynamic world. Large language models (LLM) and large multimodal models (LMM), however, still struggle to emulate this capability. In this paper, we present WorldQA, a video understanding dataset designed to push the boundaries of multimodal world models with three appealing properties: (1) Multimodal Inputs: The dataset comprises 1007 question-answer pairs and 303 videos, necessitating the analysis of both auditory and visual data for successful interpretation. (2) World Knowledge: We identify five essential types of world knowledge for question formulation. This approach challenges models to extend their capabilities beyond mere perception. (3) Long-Chain Reasoning: Our dataset introduces an average reasoning step of 4.45, notably surpassing other videoQA datasets. Furthermore, we introduce WorldRetriever, an agent designed to synthesize expert knowledge into a coherent reasoning chain, thereby facilitating accurate responses to WorldQA queries. Extensive evaluations of 13 prominent LLMs and LMMs reveal that WorldRetriever, although being the most effective model, achieved only 70% of humanlevel performance in multiple-choice questions. This finding highlights the necessity for further advancement in the reasoning and comprehension abilities of models. Our experiments also yield several key insights. For instance, while humans tend to perform better with increased frames, current LMMs, including WorldRetriever, show diminished performance under similar conditions. We hope that WorldQA,our methodology, and these insights could contribute to the future development of multimodal world models.
5/7/2024
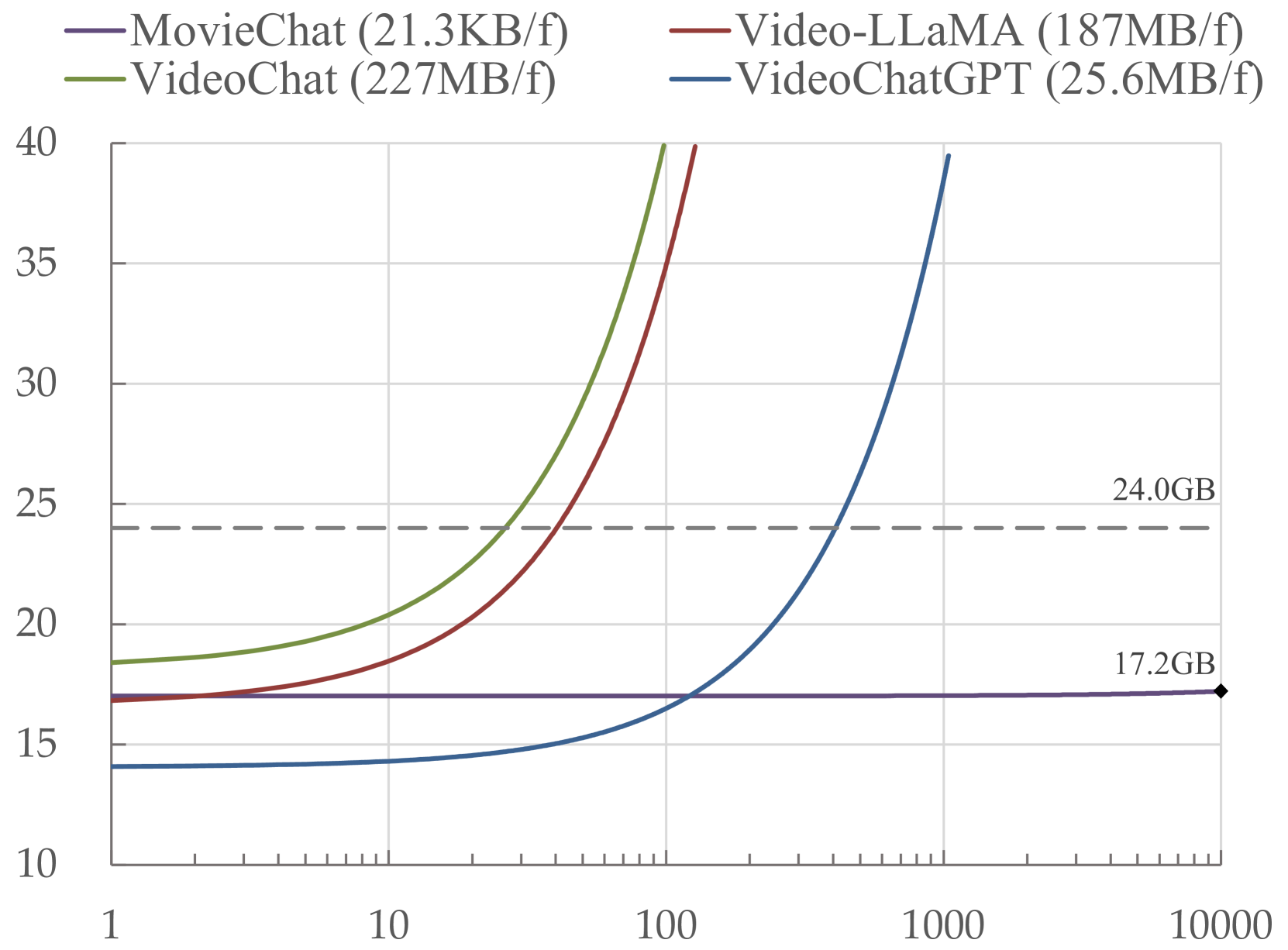
MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, Gaoang Wang
0
0
Recently, integrating video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks. Yet, existing methods either employ complex spatial-temporal modules or rely heavily on additional perception models to extract temporal features for video understanding, and they only perform well on short videos. For long videos, the computational complexity and memory costs associated with long-term temporal connections are significantly increased, posing additional challenges.Taking advantage of the Atkinson-Shiffrin memory model, with tokens in Transformers being employed as the carriers of memory in combination with our specially designed memory mechanism, we propose MovieChat to overcome these challenges. We lift pre-trained multi-modal large language models for understanding long videos without incorporating additional trainable temporal modules, employing a zero-shot approach. MovieChat achieves state-of-the-art performance in long video understanding, along with the released MovieChat-1K benchmark with 1K long video, 2K temporal grounding labels, and 14K manual annotations for validation of the effectiveness of our method. The code along with the dataset can be accessed via the following https://github.com/rese1f/MovieChat.
4/29/2024