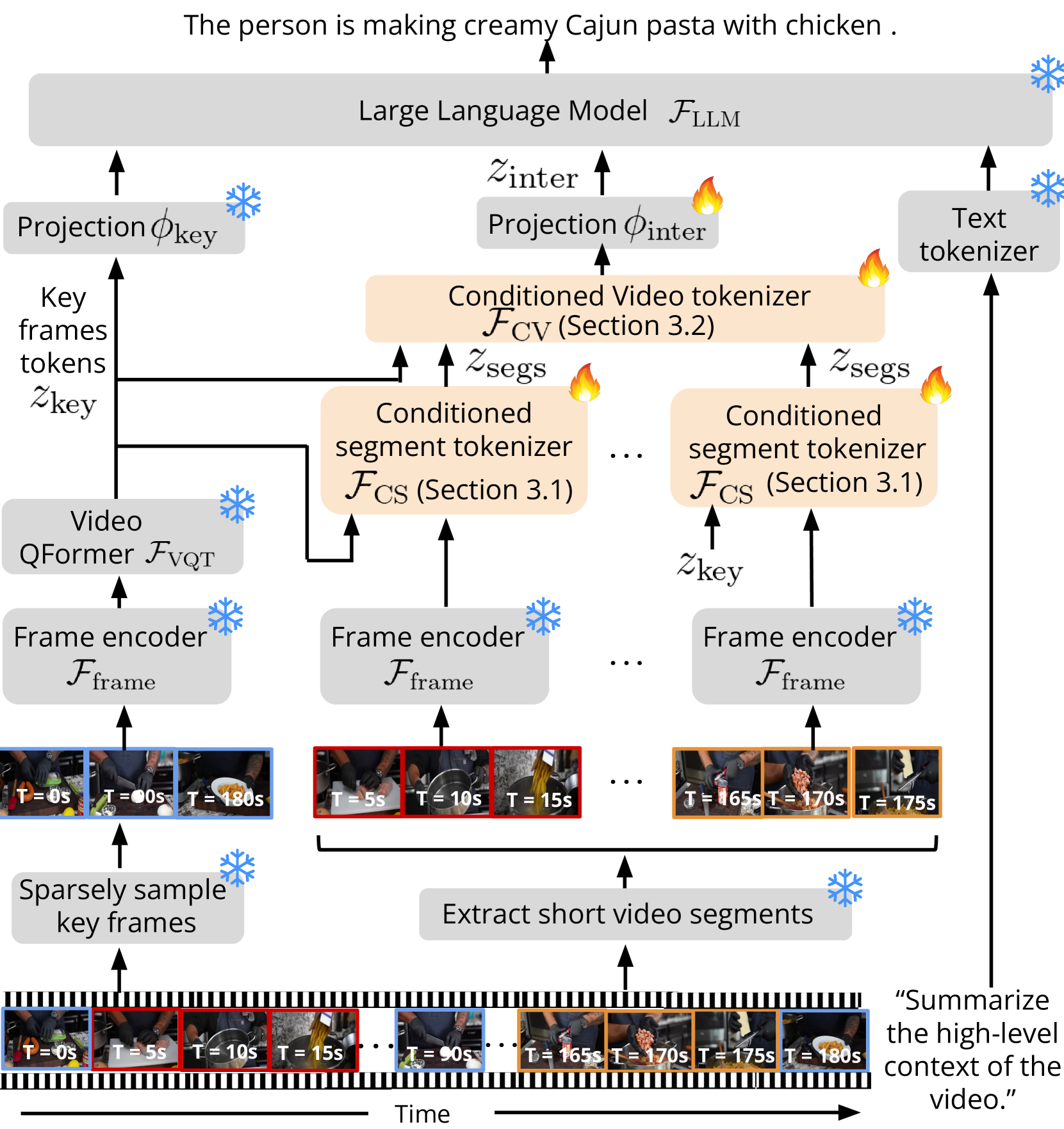
Koala: Key frame-conditioned long video-LLM
2404.04346
0
0
Abstract
Long video question answering is a challenging task that involves recognizing short-term activities and reasoning about their fine-grained relationships. State-of-the-art video Large Language Models (vLLMs) hold promise as a viable solution due to their demonstrated emergent capabilities on new tasks. However, despite being trained on millions of short seconds-long videos, vLLMs are unable to understand minutes-long videos and accurately answer questions about them. To address this limitation, we propose a lightweight and self-supervised approach, Key frame-conditioned long video-LLM (Koala), that introduces learnable spatiotemporal queries to adapt pretrained vLLMs for generalizing to longer videos. Our approach introduces two new tokenizers that condition on visual tokens computed from sparse video key frames for understanding short and long video moments. We train our proposed approach on HowTo100M and demonstrate its effectiveness on zero-shot long video understanding benchmarks, where it outperforms state-of-the-art large models by 3 - 6% in absolute accuracy across all tasks. Surprisingly, we also empirically show that our approach not only helps a pretrained vLLM to understand long videos but also improves its accuracy on short-term action recognition.
Create account to get full access
Overview
- Introduces a novel approach called "Koala" for efficient long-form video understanding using large language models (LLMs)
- Leverages key frames to condition the LLM, enabling it to capture the full context of long videos
- Proposed model demonstrates state-of-the-art performance on various long video understanding tasks
Plain English Explanation
Koala: Key frame-conditioned long video-LLM is a new method that aims to help computers better understand and process long videos. The key idea is to use "key frames" - important or representative frames from the video - to provide context and guidance to a large language model (LLM).
Traditional approaches to video understanding often struggle with long videos, as it can be challenging for the model to keep track of all the relevant details and context. Koala tries to address this by having the LLM focus on the key frames, which capture the essential information, rather than trying to process the entire video at once. This allows the model to maintain a better understanding of the video's narrative and content.
The researchers demonstrate that Koala outperforms other state-of-the-art methods on a variety of long video understanding tasks, such as video summarization and question answering. This suggests that Koala's key frame-based approach is an effective way to leverage the power of LLMs for understanding and analyzing lengthy video content.
Technical Explanation
Koala: Key frame-conditioned long video-LLM introduces a novel architecture that combines computer vision and natural language processing techniques to enable efficient long-form video understanding using large language models (LLMs).
The core idea is to leverage key frames - important or representative frames extracted from the video - to condition the LLM. This allows the model to focus on the essential information in the video, rather than trying to process the entire video sequence at once. The authors propose various key frame selection strategies, such as uniformly sampling key frames or using saliency-based approaches, and show that these methods outperform simply using the first or middle frame of the video.
The Koala model consists of three main components: a video encoder, a key frame selector, and an LLM-based video understanding module. The video encoder extracts visual features from the input video, the key frame selector identifies the most relevant key frames, and the LLM-based module uses these key frames to generate relevant outputs for tasks like video summarization, question answering, and video captioning.
The authors evaluate Koala on a range of long-form video understanding benchmarks and demonstrate significant performance improvements over existing methods, particularly on tasks that require maintaining long-term context and reasoning about complex video content.
Critical Analysis
The Koala approach presented in the paper Koala: Key frame-conditioned long video-LLM is a promising step towards more efficient and effective long-form video understanding using large language models.
One potential limitation of the approach is that the selection of key frames is a critical component, and the authors acknowledge that more advanced key frame selection strategies could further improve performance. Additionally, the model is evaluated on a limited set of tasks, and it would be valuable to see how it generalizes to a wider range of long-form video understanding challenges.
Another area for further research could be exploring the integration of memory-augmented language models or other techniques to help the LLM better maintain long-term context and reasoning capabilities when processing lengthy video content.
Overall, the Koala approach represents an important step forward in the field of long-form video understanding, and the authors' findings suggest that leveraging key frames to condition large language models is a promising direction for future research and development in this area.
Conclusion
Koala: Key frame-conditioned long video-LLM introduces a novel approach to long-form video understanding that uses key frames to condition large language models (LLMs). By focusing the LLM on the most salient information in the video, the Koala model is able to maintain better context and achieve state-of-the-art performance on a variety of long video understanding tasks.
The researchers' findings highlight the potential of leveraging LLMs for complex video analysis, and the Koala architecture demonstrates how targeted conditioning strategies can help these models overcome the challenges of processing lengthy, information-rich video content. As the field of video understanding continues to evolve, approaches like Koala may play an increasingly important role in enabling more efficient and effective long-form video analysis and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LongVLM: Efficient Long Video Understanding via Large Language Models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
0
0
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
4/11/2024

Too Many Frames, not all Useful:Efficient Strategies for Long-Form Video QA
Jongwoo Park, Kanchana Ranasinghe, Kumara Kahatapitiya, Wonjeong Ryoo, Donghyun Kim, Michael S. Ryoo
0
0
Long-form videos that span across wide temporal intervals are highly information redundant and contain multiple distinct events or entities that are often loosely-related. Therefore, when performing long-form video question answering (LVQA),all information necessary to generate a correct response can often be contained within a small subset of frames. Recent literature explore the use of large language models (LLMs) in LVQA benchmarks, achieving exceptional performance, while relying on vision language models (VLMs) to convert all visual content within videos into natural language. Such VLMs often independently caption a large number of frames uniformly sampled from long videos, which is not efficient and can mostly be redundant. Questioning these decision choices, we explore optimal strategies for key-frame selection and sequence-aware captioning, that can significantly reduce these redundancies. We propose two novel approaches that improve each of aspects, namely Hierarchical Keyframe Selector and Sequential Visual LLM. Our resulting framework termed LVNet achieves state-of-the-art performance across three benchmark LVQA datasets. Our code will be released publicly.
6/18/2024
MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, Gaoang Wang
0
0
Recently, integrating video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks. Yet, existing methods either employ complex spatial-temporal modules or rely heavily on additional perception models to extract temporal features for video understanding, and they only perform well on short videos. For long videos, the computational complexity and memory costs associated with long-term temporal connections are significantly increased, posing additional challenges.Taking advantage of the Atkinson-Shiffrin memory model, with tokens in Transformers being employed as the carriers of memory in combination with our specially designed memory mechanism, we propose MovieChat to overcome these challenges. We lift pre-trained multi-modal large language models for understanding long videos without incorporating additional trainable temporal modules, employing a zero-shot approach. MovieChat achieves state-of-the-art performance in long video understanding, along with the released MovieChat-1K benchmark with 1K long video, 2K temporal grounding labels, and 14K manual annotations for validation of the effectiveness of our method. The code along with the dataset can be accessed via the following https://github.com/rese1f/MovieChat.
4/29/2024

Streaming Long Video Understanding with Large Language Models
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, Jiaqi Wang
0
0
This paper presents VideoStreaming, an advanced vision-language large model (VLLM) for video understanding, that capably understands arbitrary-length video with a constant number of video tokens streamingly encoded and adaptively selected. The challenge of video understanding in the vision language area mainly lies in the significant computational burden caused by the great number of tokens extracted from long videos. Previous works rely on sparse sampling or frame compression to reduce tokens. However, such approaches either disregard temporal information in a long time span or sacrifice spatial details, resulting in flawed compression. To address these limitations, our VideoStreaming has two core designs: Memory-Propagated Streaming Encoding and Adaptive Memory Selection. The Memory-Propagated Streaming Encoding architecture segments long videos into short clips and sequentially encodes each clip with a propagated memory. In each iteration, we utilize the encoded results of the preceding clip as historical memory, which is integrated with the current clip to distill a condensed representation that encapsulates the video content up to the current timestamp. After the encoding process, the Adaptive Memory Selection strategy selects a constant number of question-related memories from all the historical memories and feeds them into the LLM to generate informative responses. The question-related selection reduces redundancy within the memories, enabling efficient and precise video understanding. Meanwhile, the disentangled video extraction and reasoning design allows the LLM to answer different questions about a video by directly selecting corresponding memories, without the need to encode the whole video for each question. Our model achieves superior performance and higher efficiency on long video benchmarks, showcasing precise temporal comprehension for detailed question answering.
5/28/2024