TOPICAL: TOPIC Pages AutomagicaLly

0
🎯
Sign in to get full access
Overview
- This paper presents a novel approach to automatically generate high-quality "topic pages" for scientific and biomedical concepts.
- Topic pages aggregate relevant information about an entity or concept into a single, accessible article, providing an alternative to traditional web search.
- The authors developed a pipeline called TOPICAL that combines retrieval, clustering, and language modeling to create these topic pages in a fully automated way.
- The tool was evaluated by humans and found to generate relevant, accurate, and coherent topic pages with appropriate citations.
Plain English Explanation
The paper describes a system called TOPICAL that can automatically create detailed "topic pages" for scientific and medical concepts. Topic pages are articles that gather all the key information about a particular subject in one place, making it easy for people to quickly learn about that topic.
Traditionally, if someone wants to learn about a scientific or medical concept, they might search for it on the web and have to sift through many different websites to piece together the relevant information. TOPICAL aims to streamline this process by automatically generating high-quality topic pages for a wide range of biomedical topics.
The automated process works by first retrieving relevant information about the topic from various online sources. It then organizes this information into coherent sections using clustering techniques. Finally, it generates fluent paragraphs to summarize the key points about the topic using an advanced language model.
The authors tested TOPICAL by having humans evaluate 150 of the automatically generated topic pages. They found that the vast majority were considered relevant, accurate, and well-written, with appropriate citations to support the information provided. This suggests that TOPICAL could be a powerful tool for rapidly creating high-quality educational resources about scientific and medical subjects.
Technical Explanation
The paper presents a fully automated pipeline called TOPICAL for generating topic pages about biomedical concepts. The process involves three key steps:
-
Retrieval: TOPICAL first retrieves relevant textual content about the target concept from a variety of online sources, including scientific publications, encyclopedias, and web pages.
-
Clustering: The retrieved content is then organized into coherent sections using unsupervised clustering techniques. This groups related information together to create a structured topic page.
-
Prompting: Finally, a large language model is used to generate fluent, human-readable paragraphs that summarize the key points about the target concept based on the retrieved and clustered information.
The authors evaluated TOPICAL by generating 150 topic pages for a diverse set of biomedical entities and having them assessed by human raters. The results showed that the majority of the generated topic pages were considered relevant, accurate, and coherent, with appropriate citations provided.
This work builds on prior research on automated construction of knowledge graphs and automated text generation for scientific domains. It also leverages advancements in biomedical text mining and neural topical representations to enable the fully automated creation of high-quality topic pages.
Critical Analysis
The paper presents a compelling approach to automating the creation of topic pages for biomedical concepts. The authors have demonstrated the feasibility and effectiveness of their TOPICAL system through rigorous human evaluation.
One potential limitation is the reliance on retrieving information from existing online sources, which may introduce biases or omit some relevant content. The authors acknowledge this and suggest that future work could explore incorporating structured knowledge bases or other data sources to further improve the comprehensiveness of the generated topic pages.
Additionally, while the human evaluation results were positive overall, the paper does not provide detailed analysis on the specific areas where the topic pages excelled or fell short. Deeper insights into the strengths and weaknesses of the approach could help guide future improvements.
It's also worth considering the potential societal implications of such automated knowledge generation systems. While they could greatly accelerate the creation of educational resources, there are valid concerns about the spread of misinformation or the privileging of certain perspectives. Careful consideration of these issues will be important as this technology continues to develop.
Conclusion
This paper presents a novel and promising approach to automatically generating high-quality topic pages for scientific and biomedical concepts. The TOPICAL system combines retrieval, clustering, and language modeling techniques to create comprehensive and coherent articles that can serve as valuable educational resources.
The positive human evaluation results suggest that TOPICAL could be a powerful tool for rapidly curating information about a wide range of scientific and medical topics. As the authors note, this has the potential to provide an alternative to traditional web search and make important knowledge more accessible to the public.
While the paper highlights some areas for potential improvement, the overall work represents an exciting advancement in the field of automated knowledge generation. As research synthesis and large language models continue to evolve, systems like TOPICAL may play an increasingly important role in democratizing access to scientific and medical information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
TOPICAL: TOPIC Pages AutomagicaLly
John Giorgi, Amanpreet Singh, Doug Downey, Sergey Feldman, Lucy Lu Wang
Topic pages aggregate useful information about an entity or concept into a single succinct and accessible article. Automated creation of topic pages would enable their rapid curation as information resources, providing an alternative to traditional web search. While most prior work has focused on generating topic pages about biographical entities, in this work, we develop a completely automated process to generate high-quality topic pages for scientific entities, with a focus on biomedical concepts. We release TOPICAL, a web app and associated open-source code, comprising a model pipeline combining retrieval, clustering, and prompting, that makes it easy for anyone to generate topic pages for a wide variety of biomedical entities on demand. In a human evaluation of 150 diverse topic pages generated using TOPICAL, we find that the vast majority were considered relevant, accurate, and coherent, with correct supporting citations. We make all code publicly available and host a free-to-use web app at: https://s2-topical.apps.allenai.org
Read more5/6/2024

0
PATopics: An automatic framework to extract useful information from pharmaceutical patents documents
Pablo Cecilio, Ant^onio Perreira, Juliana Santos Rosa Viegas, Washington Cunha, Felipe Viegas, Elisa Tuler, Fabiana Testa Moura de Carvalho Vicentini, Leonardo Rocha
Pharmaceutical patents play an important role by protecting the innovation from copies but also drive researchers to innovate, create new products, and promote disruptive innovations focusing on collective health. The study of patent management usually refers to an exhaustive manual search. This happens, because patent documents are complex with a lot of details regarding the claims and methodology/results explanation of the invention. To mitigate the manual search, we proposed PATopics, a framework specially designed to extract relevant information for Pharmaceutical patents. PATopics is composed of four building blocks that extract textual information from the patents, build relevant topics that are capable of summarizing the patents, correlate these topics with useful patent characteristics and then, summarize the information in a friendly web interface to final users. The general contributions of PATopics are its ability to centralize patents and to manage patents into groups based on their similarities. We extensively analyzed the framework using 4,832 pharmaceutical patents concerning 809 molecules patented by 478 companies. In our analysis, we evaluate the use of the framework considering the demands of three user profiles -- researchers, chemists, and companies. We also designed four real-world use cases to evaluate the framework's applicability. Our analysis showed how practical and helpful PATopics are in the pharmaceutical scenario.
Read more8/20/2024
💬
0
Topics as Entity Clusters: Entity-based Topics from Large Language Models and Graph Neural Networks
Manuel V. Loureiro, Steven Derby, Tri Kurniawan Wijaya
Topic models aim to reveal latent structures within a corpus of text, typically through the use of term-frequency statistics over bag-of-words representations from documents. In recent years, conceptual entities -- interpretable, language-independent features linked to external knowledge resources -- have been used in place of word-level tokens, as words typically require extensive language processing with a minimal assurance of interpretability. However, current literature is limited when it comes to exploring purely entity-driven neural topic modeling. For instance, despite the advantages of using entities for eliciting thematic structure, it is unclear whether current techniques are compatible with these sparsely organised, information-dense conceptual units. In this work, we explore entity-based neural topic modeling and propose a novel topic clustering approach using bimodal vector representations of entities. Concretely, we extract these latent representations from large language models and graph neural networks trained on a knowledge base of symbolic relations, in order to derive the most salient aspects of these conceptual units. Analysis of coherency metrics confirms that our approach is better suited to working with entities in comparison to state-of-the-art models, particularly when using graph-based embeddings trained on a knowledge base.
Read more8/26/2024
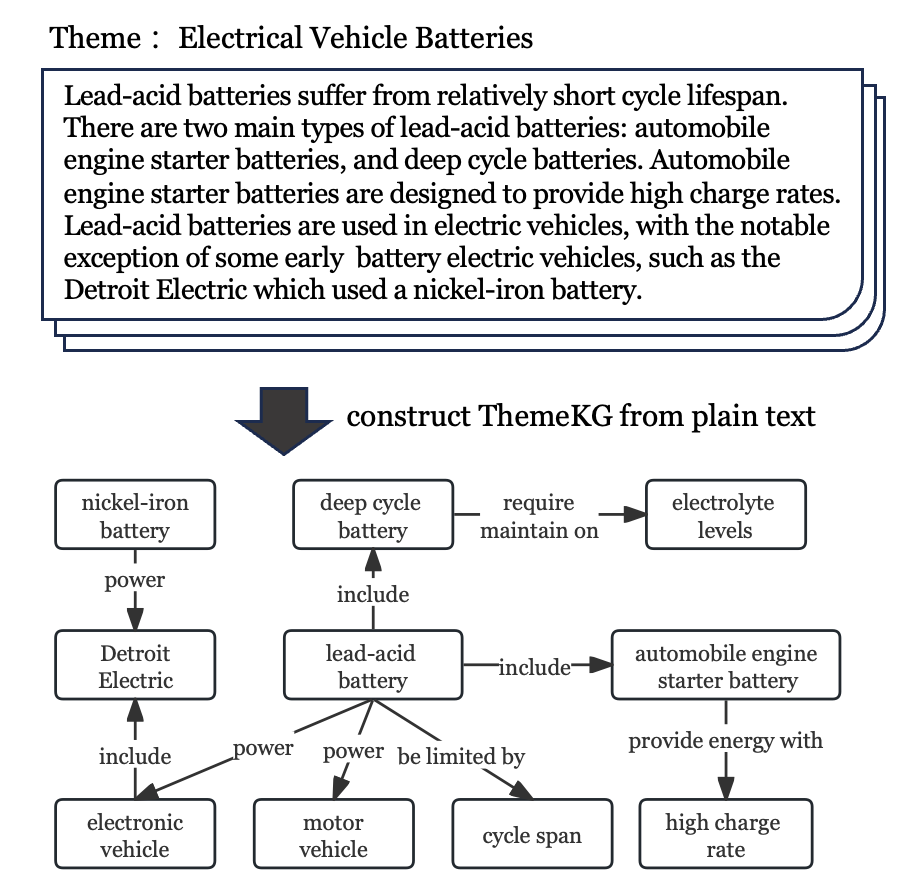
0
Automated Construction of Theme-specific Knowledge Graphs
Linyi Ding, Sizhe Zhou, Jinfeng Xiao, Jiawei Han
Despite widespread applications of knowledge graphs (KGs) in various tasks such as question answering and intelligent conversational systems, existing KGs face two major challenges: information granularity and deficiency in timeliness. These hinder considerably the retrieval and analysis of in-context, fine-grained, and up-to-date knowledge from KGs, particularly in highly specialized themes (e.g., specialized scientific research) and rapidly evolving contexts (e.g., breaking news or disaster tracking). To tackle such challenges, we propose a theme-specific knowledge graph (i.e., ThemeKG), a KG constructed from a theme-specific corpus, and design an unsupervised framework for ThemeKG construction (named TKGCon). The framework takes raw theme-specific corpus and generates a high-quality KG that includes salient entities and relations under the theme. Specifically, we start with an entity ontology of the theme from Wikipedia, based on which we then generate candidate relations by Large Language Models (LLMs) to construct a relation ontology. To parse the documents from the theme corpus, we first map the extracted entity pairs to the ontology and retrieve the candidate relations. Finally, we incorporate the context and ontology to consolidate the relations for entity pairs. We observe that directly prompting GPT-4 for theme-specific KG leads to inaccurate entities (such as two main types as one entity in the query result) and unclear (such as is, has) or wrong relations (such as have due to, to start). In contrast, by constructing the theme-specific KG step by step, our model outperforms GPT-4 and could consistently identify accurate entities and relations. Experimental results also show that our framework excels in evaluations compared with various KG construction baselines.
Read more5/1/2024