Total Selfie: Generating Full-Body Selfies
2308.14740
0
0
🛠️
Abstract
We present a method to generate full-body selfies from photographs originally taken at arms length. Because self-captured photos are typically taken close up, they have limited field of view and exaggerated perspective that distorts facial shapes. We instead seek to generate the photo some one else would take of you from a few feet away. Our approach takes as input four selfies of your face and body, a background image, and generates a full-body selfie in a desired target pose. We introduce a novel diffusion-based approach to combine all of this information into high-quality, well-composed photos of you with the desired pose and background.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers present a method to generate full-body selfies from close-up photographs
- The approach takes four face/body selfies, a background image, and generates a well-composed full-body selfie in a desired target pose
- They introduce a novel diffusion-based technique to combine all this information into high-quality photos
Plain English Explanation
Taking a good selfie can be tricky. When you hold the camera at arm's length, the photo often has a distorted, up-close look that doesn't capture your full body. This research offers a solution - a way to generate a more natural, full-body selfie photo from the close-up selfies you already have.
The key idea is to use a specialized AI system to combine multiple elements - your face and body captured in a few selfies, plus a background image - and create a new photo that looks like someone else took a picture of you from a few feet away. This gives you a well-composed, full-body shot with the desired pose and setting.
The researchers developed a novel "diffusion-based" approach to intelligently stitch together all these visual inputs into a high-quality final image. This allows you to get the kind of flattering, professional-looking selfie you might pay a photographer to take, but using just your existing selfies as the starting point.
Technical Explanation
The core of this approach is a diffusion model - a type of generative AI system that can take diverse inputs and learn to synthesize new, coherent outputs. In this case, the model ingests four selfie images of the user's face and body, plus a background image, and uses that information to generate a full-body selfie in a target pose.
The researchers trained this diffusion model on a large dataset of portrait, body, and background images. During inference, the model takes the provided selfies and background, and iteratively refines the output image through a diffusion process - gradually adding and removing visual details to construct the final full-body selfie.
Key innovations include using multiple selfie views to capture detailed facial and body information, and designing the diffusion process to preserve the user's identity and pose while seamlessly integrating the background. Experiments demonstrate that this approach can produce high-quality, visually coherent full-body selfies from modest input data.
Critical Analysis
The paper presents a compelling application of generative AI techniques to solve an everyday photography challenge. However, there are a few potential limitations and ethical considerations worth noting.
First, the quality of the output is still somewhat variable and may not match professional-level photography in all cases. The authors acknowledge this and suggest further research to improve the diffusion model and training data.
There are also potential privacy and consent concerns, as this technology could theoretically be used to create non-consensual images of individuals. The authors do not address these issues, so it would be important for any real-world deployment to have robust safeguards in place.
Finally, one might question whether this technology is truly empowering users or simply automating away a creative skill. While it provides an accessible way to get polished selfie photos, it could also reduce the incentive for people to learn photography techniques themselves.
Conclusion
Overall, this research offers an innovative solution to a common photography problem. By leveraging the power of generative AI, it enables users to transform their close-up selfies into well-composed, full-body shots. This has the potential to make professional-quality selfies more accessible and satisfy the growing demand for visually striking social media content.
However, the technology also raises some ethical concerns that would need to be carefully addressed. As generative AI continues to advance, it will be important to consider both the benefits and risks of these capabilities, and ensure they are developed and used responsibly.
Related Papers

A Simple Strategy for Body Estimation from Partial-View Images
Yafei Mao, Xuelu Li, Brandon Smith, Jinjin Li, Raja Bala
0
0
Virtual try-on and product personalization have become increasingly important in modern online shopping, highlighting the need for accurate body measurement estimation. Although previous research has advanced in estimating 3D body shapes from RGB images, the task is inherently ambiguous as the observed scale of human subjects in the images depends on two unknown factors: capture distance and body dimensions. This ambiguity is particularly pronounced in partial-view scenarios. To address this challenge, we propose a modular and simple height normalization solution. This solution relocates the subject skeleton to the desired position, thereby normalizing the scale and disentangling the relationship between the two variables. Our experimental results demonstrate that integrating this technique into state-of-the-art human mesh reconstruction models significantly enhances partial body measurement estimation. Additionally, we illustrate the applicability of this approach to multi-view settings, showcasing its versatility.
4/17/2024
🖼️
From Parts to Whole: A Unified Reference Framework for Controllable Human Image Generation
Zehuan Huang, Hongxing Fan, Lipeng Wang, Lu Sheng
0
0
Recent advancements in controllable human image generation have led to zero-shot generation using structural signals (e.g., pose, depth) or facial appearance. Yet, generating human images conditioned on multiple parts of human appearance remains challenging. Addressing this, we introduce Parts2Whole, a novel framework designed for generating customized portraits from multiple reference images, including pose images and various aspects of human appearance. To achieve this, we first develop a semantic-aware appearance encoder to retain details of different human parts, which processes each image based on its textual label to a series of multi-scale feature maps rather than one image token, preserving the image dimension. Second, our framework supports multi-image conditioned generation through a shared self-attention mechanism that operates across reference and target features during the diffusion process. We enhance the vanilla attention mechanism by incorporating mask information from the reference human images, allowing for the precise selection of any part. Extensive experiments demonstrate the superiority of our approach over existing alternatives, offering advanced capabilities for multi-part controllable human image customization. See our project page at https://huanngzh.github.io/Parts2Whole/.
4/24/2024
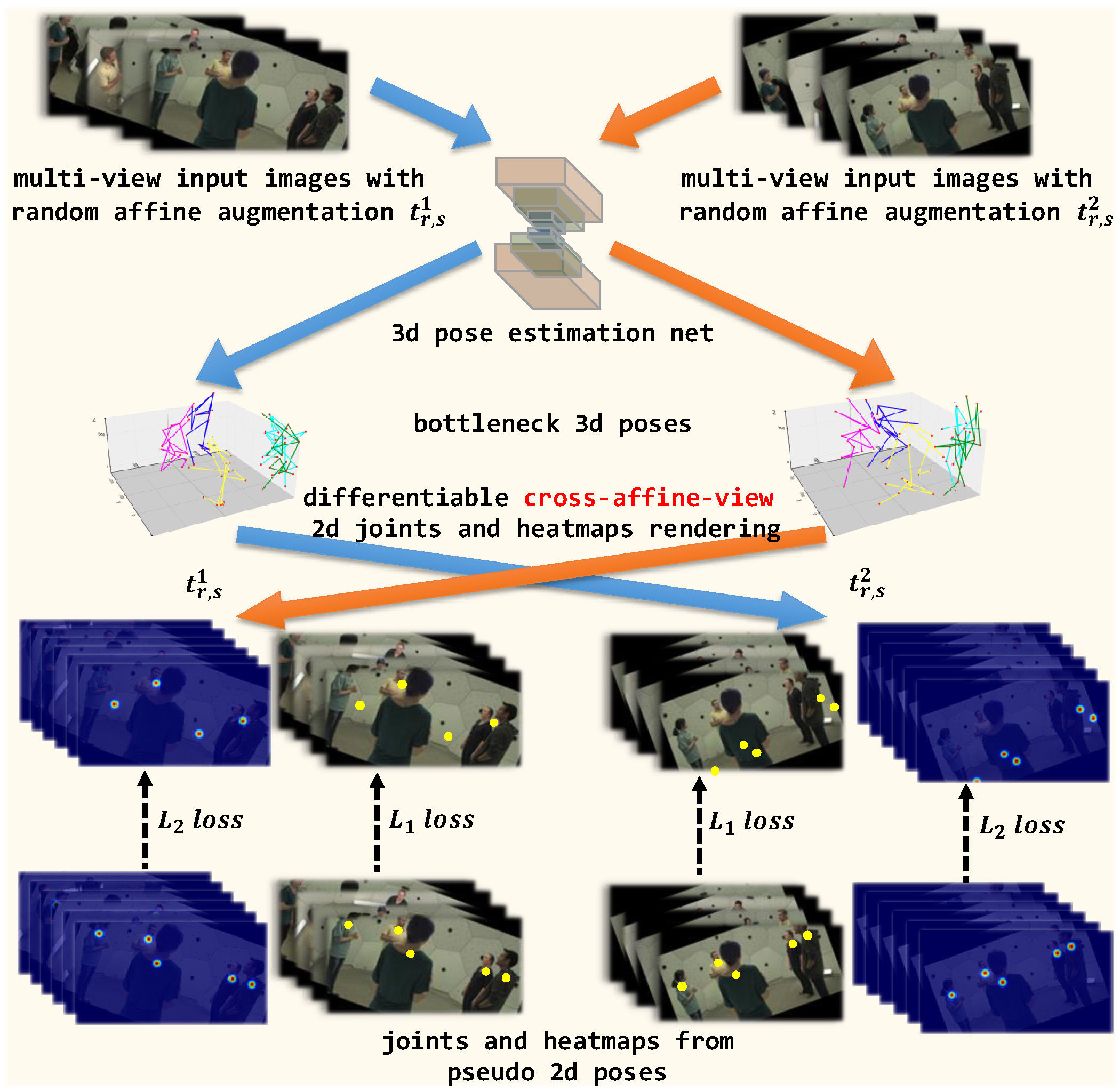
SelfPose3d: Self-Supervised Multi-Person Multi-View 3d Pose Estimation
Vinkle Srivastav, Keqi Chen, Nicolas Padoy
0
0
We present a new self-supervised approach, SelfPose3d, for estimating 3d poses of multiple persons from multiple camera views. Unlike current state-of-the-art fully-supervised methods, our approach does not require any 2d or 3d ground-truth poses and uses only the multi-view input images from a calibrated camera setup and 2d pseudo poses generated from an off-the-shelf 2d human pose estimator. We propose two self-supervised learning objectives: self-supervised person localization in 3d space and self-supervised 3d pose estimation. We achieve self-supervised 3d person localization by training the model on synthetically generated 3d points, serving as 3d person root positions, and on the projected root-heatmaps in all the views. We then model the 3d poses of all the localized persons with a bottleneck representation, map them onto all views obtaining 2d joints, and render them using 2d Gaussian heatmaps in an end-to-end differentiable manner. Afterwards, we use the corresponding 2d joints and heatmaps from the pseudo 2d poses for learning. To alleviate the intrinsic inaccuracy of the pseudo labels, we propose an adaptive supervision attention mechanism to guide the self-supervision. Our experiments and analysis on three public benchmark datasets, including Panoptic, Shelf, and Campus, show the effectiveness of our approach, which is comparable to fully-supervised methods. Code is available at url{https://github.com/CAMMA-public/SelfPose3D}
4/3/2024
🛸
Towards a Simultaneous and Granular Identity-Expression Control in Personalized Face Generation
Renshuai Liu, Bowen Ma, Wei Zhang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding, Xuan Cheng
0
0
In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions. This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.
4/9/2024