Toward In-Context Teaching: Adapting Examples to Students' Misconceptions

0

Sign in to get full access
Overview
- The paper "Toward In-Context Teaching: Adapting Examples to Students' Misconceptions" explores how to improve educational content by adapting examples to address students' existing misconceptions.
- The key idea is to leverage language models to identify common student misconceptions and then modify examples to address those issues, creating more effective in-context teaching.
- This research has the potential to enhance the learning experience by tailoring educational materials to the specific needs of students, as opposed to a one-size-fits-all approach.
Plain English Explanation
The paper looks at ways to make educational examples more effective by adapting them to address common mistakes or misunderstandings that students often have. The researchers propose using language models - powerful AI systems that can understand and generate human-like text - to identify the typical misconceptions that students have about a topic. Then, they can modify the examples to directly address those misconceptions, creating a more personalized and effective learning experience.
For example, if the language model identifies that students often get confused about a certain math concept, the researchers could adjust the example problems to focus on that specific issue. By tailoring the examples to the students' needs, rather than using a generic one-size-fits-all approach, the hope is that the students will better understand the material and learn more effectively.
This approach could be particularly useful in areas like online learning or large classrooms, where it's difficult for instructors to individualize the content for each student. By leveraging language models to identify and address common stumbling blocks, the educational materials can be optimized to support student learning in a more personalized way.
Technical Explanation
The paper proposes a framework for "in-context teaching" that adapts educational examples to address students' common misconceptions. The key components are:
-
Misconception Identification: The researchers use a language model, such as BERT, to analyze a corpus of student responses and identify common misconceptions about a topic.
-
Example Adaptation: Based on the identified misconceptions, the examples are then modified to directly address those issues. This could involve changing the wording, the structure, or the context of the example to better align with the students' needs.
-
Evaluation: The researchers then test the effectiveness of the adapted examples by comparing student learning outcomes to those from using the original, unmodified examples.
The paper presents the results of several experiments demonstrating the potential of this approach. For example, they show that adapting math examples to address common student mistakes can lead to significant improvements in performance on related problems.
Critical Analysis
The paper provides a promising direction for enhancing educational content through the use of language models. By incorporating an understanding of student misconceptions, the examples can be tailored to better support learning and address common stumbling blocks.
However, the research also acknowledges some limitations and areas for further exploration. For instance, the approach relies on the language model accurately identifying the most common and impactful misconceptions, which may not always be the case. Additionally, the specific modifications made to the examples could introduce new issues or unintended consequences that would need to be carefully evaluated.
Further research is also needed to understand the broader applicability of this approach, as the experiments were focused on specific domains like math and chemistry. Expanding the study to other subjects and learning contexts would help validate the generalizability of the findings.
Overall, this paper represents an important step towards more personalized and effective educational content, leveraging the capabilities of large language models. By adapting examples to address students' misconceptions, the learning experience can be optimized to better support student understanding and achievement.
Conclusion
The paper "Toward In-Context Teaching: Adapting Examples to Students' Misconceptions" presents a novel approach to enhancing educational content by tailoring examples to address common student misconceptions. By using language models to identify typical misunderstandings, the researchers demonstrate how examples can be modified to directly support student learning.
This research has the potential to significantly improve the effectiveness of educational materials, particularly in areas like online learning or large classrooms where individualized instruction can be challenging. By leveraging language models to create more personalized learning experiences, students may be able to better grasp concepts and achieve higher levels of understanding and success.
While the research has some limitations and areas for further exploration, the findings represent an important step towards more adaptive and effective educational content. As language models continue to advance, the opportunities to enhance teaching and learning through personalized, in-context examples are likely to grow, benefiting students and educators alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Toward In-Context Teaching: Adapting Examples to Students' Misconceptions
Alexis Ross, Jacob Andreas
When a teacher provides examples for a student to study, these examples must be informative, enabling a student to progress from their current state toward a target concept or skill. Good teachers must therefore simultaneously infer what students already know and adapt their teaching to students' changing state of knowledge. There is increasing interest in using computational models, particularly large language models, as pedagogical tools. As students, language models in particular have shown a remarkable ability to adapt to new tasks given small numbers of examples. But how effectively can these models adapt as teachers to students of different types? To study this question, we introduce a suite of models and evaluation methods we call AdapT. AdapT has two components: (1) a collection of simulated Bayesian student models that can be used for evaluation of automated teaching methods; (2) a platform for evaluation with human students, to characterize the real-world effectiveness of these methods. We additionally introduce (3) AToM, a new probabilistic model for adaptive teaching that jointly infers students' past beliefs and optimizes for the correctness of future beliefs. In evaluations of simulated students across three learning domains (fraction arithmetic, English morphology, function learning), AToM systematically outperforms LLM-based and standard Bayesian teaching models. In human experiments, both AToM and LLMs outperform non-adaptive random example selection. Our results highlight both the difficulty of the adaptive teaching task and the potential of learned adaptive models for solving it.
Read more5/8/2024
0
Aligning Teacher with Student Preferences for Tailored Training Data Generation
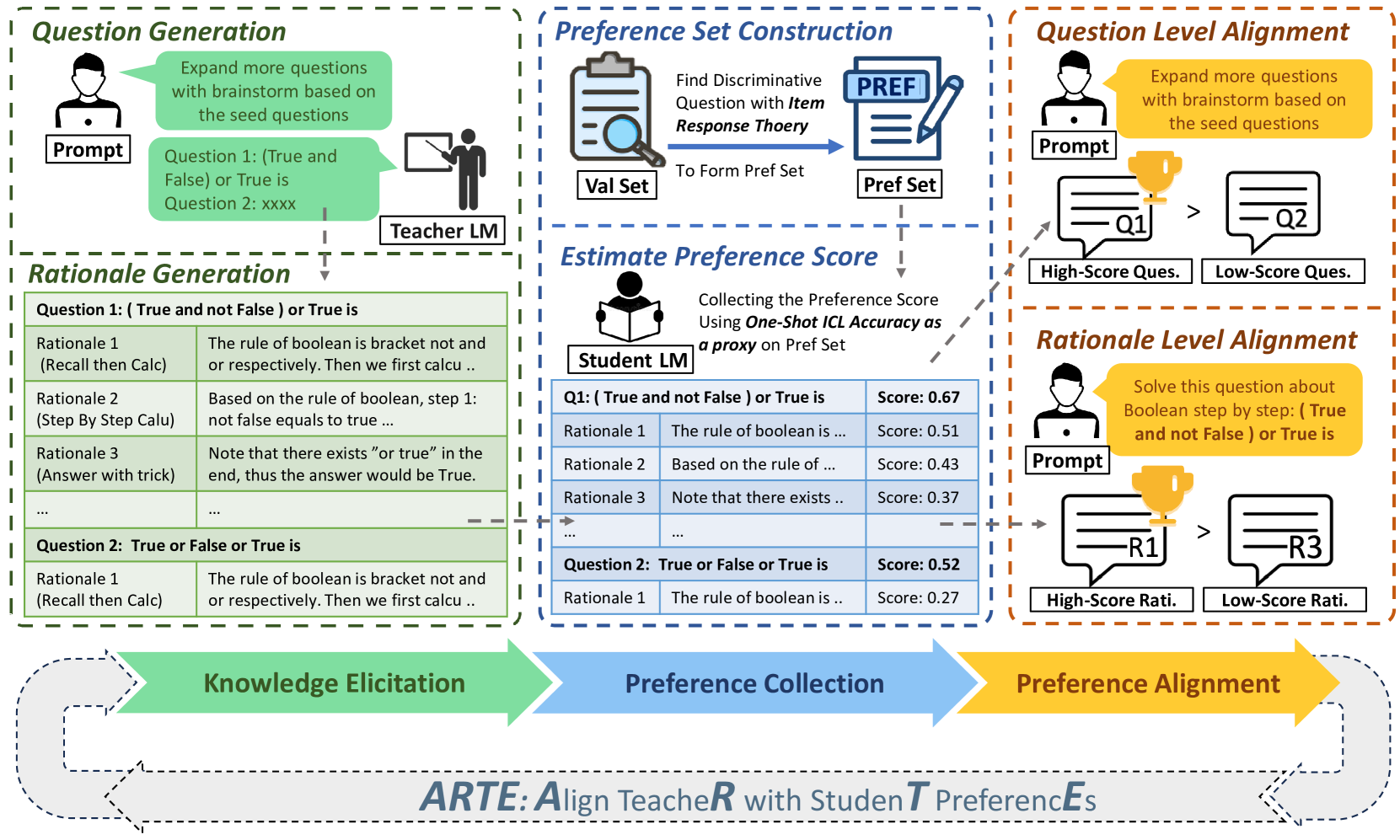
Yantao Liu, Zhao Zhang, Zijun Yao, Shulin Cao, Lei Hou, Juanzi Li
Large Language Models (LLMs) have shown significant promise as copilots in various tasks. Local deployment of LLMs on edge devices is necessary when handling privacy-sensitive data or latency-sensitive tasks. The computational constraints of such devices make direct deployment of powerful large-scale LLMs impractical, necessitating the Knowledge Distillation from large-scale models to lightweight models. Lots of work has been done to elicit diversity and quality training examples from LLMs, but little attention has been paid to aligning teacher instructional content based on student preferences, akin to responsive teaching in pedagogy. Thus, we propose ARTE, dubbed Aligning TeacheR with StudenT PreferencEs, a framework that aligns the teacher model with student preferences to generate tailored training examples for Knowledge Distillation. Specifically, we elicit draft questions and rationales from the teacher model, then collect student preferences on these questions and rationales using students' performance with in-context learning as a proxy, and finally align the teacher model with student preferences. In the end, we repeat the first step with the aligned teacher model to elicit tailored training examples for the student model on the target task. Extensive experiments on academic benchmarks demonstrate the superiority of ARTE over existing instruction-tuning datasets distilled from powerful LLMs. Moreover, we thoroughly investigate the generalization of ARTE, including the generalization of fine-tuned student models in reasoning ability and the generalization of aligned teacher models to generate tailored training data across tasks and students. In summary, our contributions lie in proposing a novel framework for tailored training example generation, demonstrating its efficacy in experiments, and investigating the generalization of both student & aligned teacher models in ARTE.
Read more6/28/2024

0
Teaching-Assistant-in-the-Loop: Improving Knowledge Distillation from Imperfect Teacher Models in Low-Budget Scenarios
Yuhang Zhou, Wei Ai
There is increasing interest in distilling task-specific knowledge from large language models (LLM) to smaller student models. Nonetheless, LLM distillation presents a dual challenge: 1) there is a high cost associated with querying the teacher LLM, such as GPT-4, for gathering an ample number of demonstrations; 2) the teacher LLM might provide imperfect outputs with a negative impact on the student's learning process. To enhance sample efficiency within resource-constrained, imperfect teacher scenarios, we propose a three-component framework leveraging three signal types. The first signal is the student's self-consistency (consistency of student multiple outputs), which is a proxy of the student's confidence. Specifically, we introduce a ``teaching assistant'' (TA) model to assess the uncertainty of both the student's and the teacher's outputs via confidence scoring, which serves as another two signals for student training. Furthermore, we propose a two-stage training schema to first warm up the student with a small proportion of data to better utilize student's signal. Experiments have shown the superiority of our proposed framework for four complex reasoning tasks. On average, our proposed two-stage framework brings a relative improvement of up to 20.79% compared to fine-tuning without any signals across datasets.
Read more6/11/2024

0
AutoTutor meets Large Language Models: A Language Model Tutor with Rich Pedagogy and Guardrails
Sankalan Pal Chowdhury, Vil'em Zouhar, Mrinmaya Sachan
Large Language Models (LLMs) have found several use cases in education, ranging from automatic question generation to essay evaluation. In this paper, we explore the potential of using Large Language Models (LLMs) to author Intelligent Tutoring Systems. A common pitfall of LLMs is their straying from desired pedagogical strategies such as leaking the answer to the student, and in general, providing no guarantees. We posit that while LLMs with certain guardrails can take the place of subject experts, the overall pedagogical design still needs to be handcrafted for the best learning results. Based on this principle, we create a sample end-to-end tutoring system named MWPTutor, which uses LLMs to fill in the state space of a pre-defined finite state transducer. This approach retains the structure and the pedagogy of traditional tutoring systems that has been developed over the years by learning scientists but brings in additional flexibility of LLM-based approaches. Through a human evaluation study on two datasets based on math word problems, we show that our hybrid approach achieves a better overall tutoring score than an instructed, but otherwise free-form, GPT-4. MWPTutor is completely modular and opens up the scope for the community to improve its performance by improving individual modules or using different teaching strategies that it can follow.
Read more4/26/2024