Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning

0
🔎
Sign in to get full access
Overview
- The rapid growth of remote-sensing images has driven the need for object detectors that can identify objects beyond their training categories without collecting new labeled data.
- This paper proposes an "open-vocabulary object detection" (OVD) technique for aerial images that can scale up the vocabulary of detected objects.
- The performance of OVD depends on generating high-quality object proposals and pseudo-labels for novel object categories.
Plain English Explanation
The number of aerial images collected by remote sensing technologies is increasing rapidly. Researchers want to develop object detection models that can recognize a wide variety of objects, beyond just the specific objects they were trained on. This would avoid the costly process of collecting and labeling new training data every time they want to expand the set of objects the detector can find.
The key challenge is that the model needs to be able to accurately propose regions that might contain objects, and then correctly classify those objects, even if they are novel categories the model hasn't seen before.
To address this, the researchers propose a framework called "CastDet" that uses a two-part "student-teacher" approach. The student model is trained to propose regions and classify objects, while an omniscient "teacher" model called RemoteCLIP provides additional guidance to boost the student's performance, especially on novel object categories.
The researchers also developed a strategy to maintain high-quality "pseudo-labels" - educated guesses about the identity of novel objects - during the training process. This helps the student model learn to recognize a growing vocabulary of objects over time.
Technical Explanation
The core of the CastDet framework is a student-teacher architecture, where the student model is trained to perform open-vocabulary object detection (OVD) on aerial images. The key components are:
-
Region Proposal Network: The student model first generates class-agnostic region proposals that may contain objects, using techniques like anchor boxes and feature pyramids.
-
Classification and Pseudo-Labeling: The student then classifies the proposed regions, using "pseudo-labels" for novel object categories that it hasn't been trained on. These pseudo-labels come from the RemoteCLIP teacher model.
-
Dynamic Label Queue: To maintain high-quality pseudo-labels during training, the framework uses a dynamic label queue strategy that updates the pseudo-labels over time.
The researchers evaluate CastDet on multiple aerial image datasets and show it outperforms state-of-the-art open-vocabulary object detectors by a significant margin, reaching 46.5% mAP on novel categories in one dataset.
Critical Analysis
The paper makes a strong contribution by applying open-vocabulary object detection to the aerial imaging domain, which has important real-world applications. The student-teacher approach with the RemoteCLIP model as the omniscient teacher is a clever way to leverage additional knowledge to boost performance on novel object categories.
However, the paper does not address some potential limitations. For example, the RemoteCLIP model itself may have biases or blindspots that could be transferred to the student model. Additionally, the dynamic label queue strategy, while innovative, may become unstable or unreliable as the vocabulary of objects grows very large.
Further research could explore ways to make the open-vocabulary detection more robust, such as by incorporating uncertainty estimates or employing active learning techniques to selectively acquire new labeled data. Investigating the generalization of CastDet to other domains beyond aerial imaging would also be valuable.
Conclusion
This paper presents a novel framework called CastDet that advances the state-of-the-art in open-vocabulary object detection for aerial images. By leveraging a student-teacher architecture with a powerful CLIP-based teacher model, CastDet is able to generate high-quality region proposals and pseudo-labels for novel object categories, leading to substantial performance gains.
The work highlights the importance of developing scalable object detection techniques that can adapt to the ever-growing universe of visual data, without the need for costly data collection and labeling efforts. As remote sensing technologies continue to proliferate, tools like CastDet will become increasingly crucial for extracting meaningful insights from the flood of aerial imagery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Toward Open Vocabulary Aerial Object Detection with CLIP-Activated Student-Teacher Learning
Yan Li, Weiwei Guo, Xue Yang, Ning Liao, Dunyun He, Jiaqi Zhou, Wenxian Yu
An increasingly massive number of remote-sensing images spurs the development of extensible object detectors that can detect objects beyond training categories without costly collecting new labeled data. In this paper, we aim to develop open-vocabulary object detection (OVD) technique in aerial images that scales up object vocabulary size beyond training data. The performance of OVD greatly relies on the quality of class-agnostic region proposals and pseudo-labels for novel object categories. To simultaneously generate high-quality proposals and pseudo-labels, we propose CastDet, a CLIP-activated student-teacher open-vocabulary object Detection framework. Our end-to-end framework following the student-teacher self-learning mechanism employs the RemoteCLIP model as an extra omniscient teacher with rich knowledge. By doing so, our approach boosts not only novel object proposals but also classification. Furthermore, we devise a dynamic label queue strategy to maintain high-quality pseudo labels during batch training. We conduct extensive experiments on multiple existing aerial object detection datasets, which are set up for the OVD task. Experimental results demonstrate our CastDet achieving superior open-vocabulary detection performance, e.g., reaching 46.5% mAP on VisDroneZSD novel categories, which outperforms the state-of-the-art open-vocabulary detectors by 21.0% mAP. To our best knowledge, this is the first work to apply and develop the open-vocabulary object detection technique for aerial images. The code is available at https://github.com/lizzy8587/CastDet.
Read more8/13/2024

0
OVA-DETR: Open Vocabulary Aerial Object Detection Using Image-Text Alignment and Fusion
Guoting Wei, Xia Yuan, Yu Liu, Zhenhao Shang, Kelu Yao, Chao Li, Qingsen Yan, Chunxia Zhao, Haokui Zhang, Rong Xiao
Aerial object detection has been a hot topic for many years due to its wide application requirements. However, most existing approaches can only handle predefined categories, which limits their applicability for the open scenarios in real-world. In this paper, we extend aerial object detection to open scenarios by exploiting the relationship between image and text, and propose OVA-DETR, a high-efficiency open-vocabulary detector for aerial images. Specifically, based on the idea of image-text alignment, we propose region-text contrastive loss to replace the category regression loss in the traditional detection framework, which breaks the category limitation. Then, we propose Bidirectional Vision-Language Fusion (Bi-VLF), which includes a dual-attention fusion encoder and a multi-level text-guided Fusion Decoder. The dual-attention fusion encoder enhances the feature extraction process in the encoder part. The multi-level text-guided Fusion Decoder is designed to improve the detection ability for small objects, which frequently appear in aerial object detection scenarios. Experimental results on three widely used benchmark datasets show that our proposed method significantly improves the mAP and recall, while enjoying faster inference speed. For instance, in zero shot detection experiments on DIOR, the proposed OVA-DETR outperforms DescReg and YOLO-World by 37.4% and 33.1%, respectively, while achieving 87 FPS inference speed, which is 7.9x faster than DescReg and 3x faster than YOLO-world. The code is available at https://github.com/GT-Wei/OVA-DETR.
Read more8/23/2024
🔎
0
LP-OVOD: Open-Vocabulary Object Detection by Linear Probing
Chau Pham, Truong Vu, Khoi Nguyen
This paper addresses the challenging problem of open-vocabulary object detection (OVOD) where an object detector must identify both seen and unseen classes in test images without labeled examples of the unseen classes in training. A typical approach for OVOD is to use joint text-image embeddings of CLIP to assign box proposals to their closest text label. However, this method has a critical issue: many low-quality boxes, such as over- and under-covered-object boxes, have the same similarity score as high-quality boxes since CLIP is not trained on exact object location information. To address this issue, we propose a novel method, LP-OVOD, that discards low-quality boxes by training a sigmoid linear classifier on pseudo labels retrieved from the top relevant region proposals to the novel text. Experimental results on COCO affirm the superior performance of our approach over the state of the art, achieving $textbf{40.5}$ in $text{AP}_{novel}$ using ResNet50 as the backbone and without external datasets or knowing novel classes during training. Our code will be available at https://github.com/VinAIResearch/LP-OVOD.
Read more6/4/2024
0
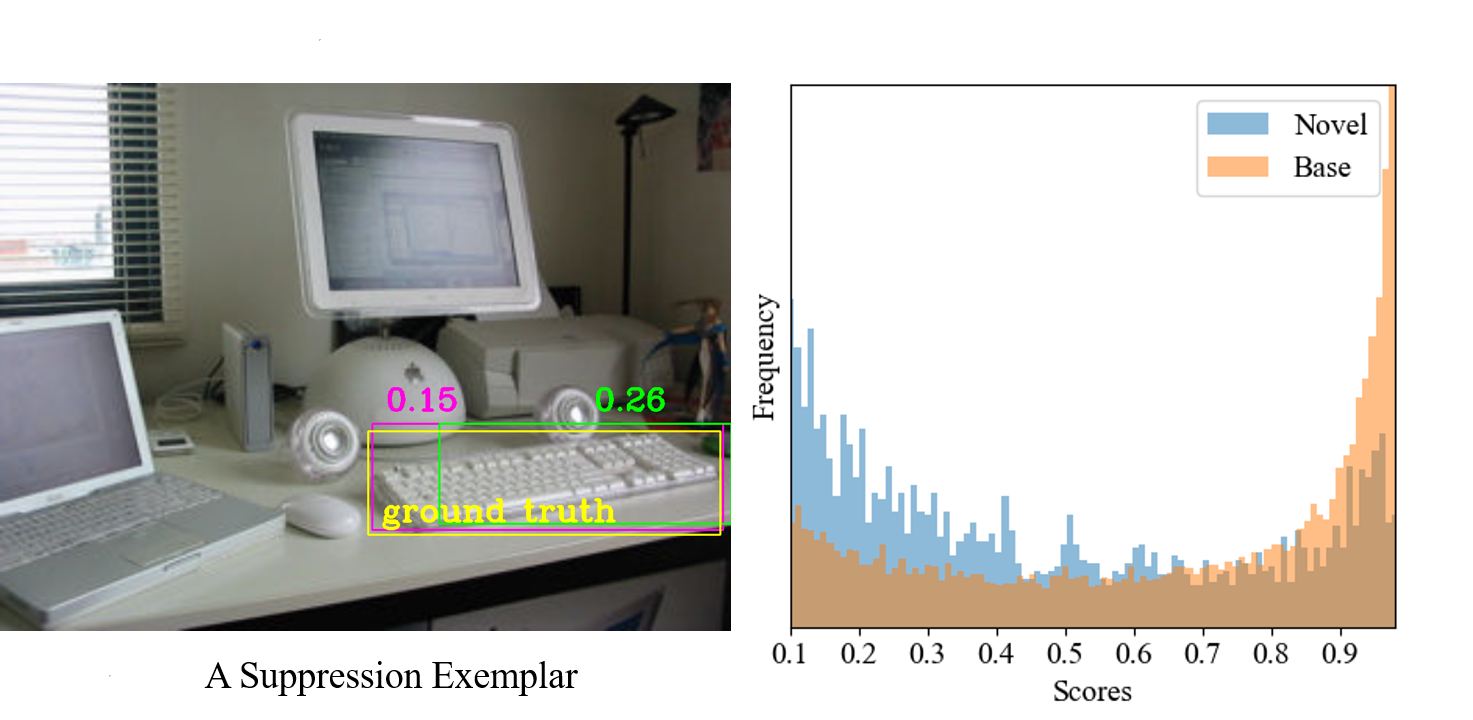
Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation
Yanhao Zheng, Kai Liu
Open-vocabulary object detection (OVOD) aims at localizing and recognizing visual objects from novel classes unseen at the training time. Whereas, empirical studies reveal that advanced detectors generally assign lower scores to those novel instances, which are inadvertently suppressed during inference by commonly adopted greedy strategies like Non-Maximum Suppression (NMS), leading to sub-optimal detection performance for novel classes. This paper systematically investigates this problem with the commonly-adopted two-stage OVOD paradigm. Specifically, in the region-proposal stage, proposals that contain novel instances showcase lower objectness scores, since they are treated as background proposals during the training phase. Meanwhile, in the object-classification stage, novel objects share lower region-text similarities (i.e., classification scores) due to the biased visual-language alignment by seen training samples. To alleviate this problem, this paper introduces two advanced measures to adjust confidence scores and conserve erroneously dismissed objects: (1) a class-agnostic localization quality estimate via overlap degree of region/object proposals, and (2) a text-guided visual similarity estimate with proxy prototypes for novel classes. Integrated with adjusting techniques specifically designed for the region-proposal and object-classification stages, this paper derives the aggregated confidence estimate for the open-vocabulary object detection paradigm (AggDet). Our AggDet is a generic and training-free post-processing scheme, which consistently bolsters open-vocabulary detectors across model scales and architecture designs. For instance, AggDet receives 3.3% and 1.5% gains on OV-COCO and OV-LVIS benchmarks respectively, without any training cost.
Read more4/15/2024