Towards Assessing Data Replication in Music Generation with Music Similarity Metrics on Raw Audio

0

Sign in to get full access
Overview
- This paper explores ways to assess data replication in music generation models using music similarity metrics on raw audio.
- The goal is to develop better evaluation methods for music generation models beyond just listening tests.
- The researchers propose using music similarity metrics like Demucs and Chroma to compare generated music to the original data.
Plain English Explanation
The paper is looking at how to better evaluate music generation models, which are AI systems that can create new music. Traditionally, these models have been evaluated by having people listen to the generated music and give their opinions. However, the researchers think there may be more objective ways to assess how well the models are doing.
One idea they explore is using "music similarity metrics" - these are mathematical ways of measuring how similar two pieces of music sound. The researchers test out a few different metrics, like Demucs and Chroma, to see how well they can detect when a music generation model is just copying the original training data, versus actually creating new music.
The goal is to develop better evaluation methods that go beyond just relying on human listeners. This could help researchers improve the quality and originality of music generated by AI systems.
Technical Explanation
The paper examines the use of music similarity metrics on raw audio as a way to assess data replication in music generation models. The researchers test two popular metrics - Demucs, which measures general audio similarity, and Chroma, which focuses on harmonic content.
They set up experiments where they train music generation models on different datasets and then evaluate the generated samples using the similarity metrics. By analyzing the distribution of similarity scores between the generated music and the original training data, they can gain insights into whether the models are simply replicating the training data versus generating novel, diverse music.
The results suggest that the Demucs metric in particular is effective at identifying cases where the generation model is overfitting and producing highly similar output to the training data. This provides a more objective way to assess model performance beyond just human listening tests.
The authors discuss how these similarity-based evaluation methods could be integrated into the music generation research process to help drive the development of more original and diverse AI-composed music. They also note some limitations, such as the metrics not fully capturing all aspects of musical creativity.
Critical Analysis
The paper makes a valuable contribution by exploring more principled, data-driven evaluation methods for music generation models. Going beyond subjective human evaluations is an important step, as these can be prone to biases and inconsistencies.
That said, the authors acknowledge that the similarity metrics they test, while useful, do not capture the full spectrum of musical creativity and originality. There are likely other aspects of music, such as emotional expression or structural complexity, that are not well reflected in these low-level similarity measures.
Additionally, the experiments are limited to a few specific datasets and model architectures. More diverse testing would be needed to fully validate the generalizability of these evaluation techniques. The authors also don't explore how these metrics could be used to directly optimize music generation models during training.
Overall, this research is a promising step towards developing more robust and comprehensive evaluation frameworks for AI music systems. Continued work in this area, combined with a deeper understanding of human musical perception, could lead to major advancements in the field of computational creativity.
Conclusion
This paper presents a novel approach to assessing data replication in music generation models using music similarity metrics on raw audio data. By testing metrics like Demucs and Chroma, the researchers demonstrate a more objective way to evaluate whether models are simply copying their training data versus generating truly novel music.
The findings suggest that these similarity-based evaluation methods could be a valuable addition to the music generation research toolkit, complementing traditional human listening tests. Ultimately, this work represents an important step towards developing AI systems that can create original and expressive music, with potential applications in everything from digital entertainment to music therapy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Assessing Data Replication in Music Generation with Music Similarity Metrics on Raw Audio
Roser Batlle-Roca, Wei-Hisang Liao, Xavier Serra, Yuki Mitsufuji, Emilia G'omez
Recent advancements in music generation are raising multiple concerns about the implications of AI in creative music processes, current business models and impacts related to intellectual property management. A relevant discussion and related technical challenge is the potential replication and plagiarism of the training set in AI-generated music, which could lead to misuse of data and intellectual property rights violations. To tackle this issue, we present the Music Replication Assessment (MiRA) tool: a model-independent open evaluation method based on diverse audio music similarity metrics to assess data replication. We evaluate the ability of five metrics to identify exact replication by conducting a controlled replication experiment in different music genres using synthetic samples. Our results show that the proposed methodology can estimate exact data replication with a proportion higher than 10%. By introducing the MiRA tool, we intend to encourage the open evaluation of music-generative models by researchers, developers, and users concerning data replication, highlighting the importance of the ethical, social, legal, and economic consequences. Code and examples are available for reproducibility purposes.
Read more8/2/2024
0
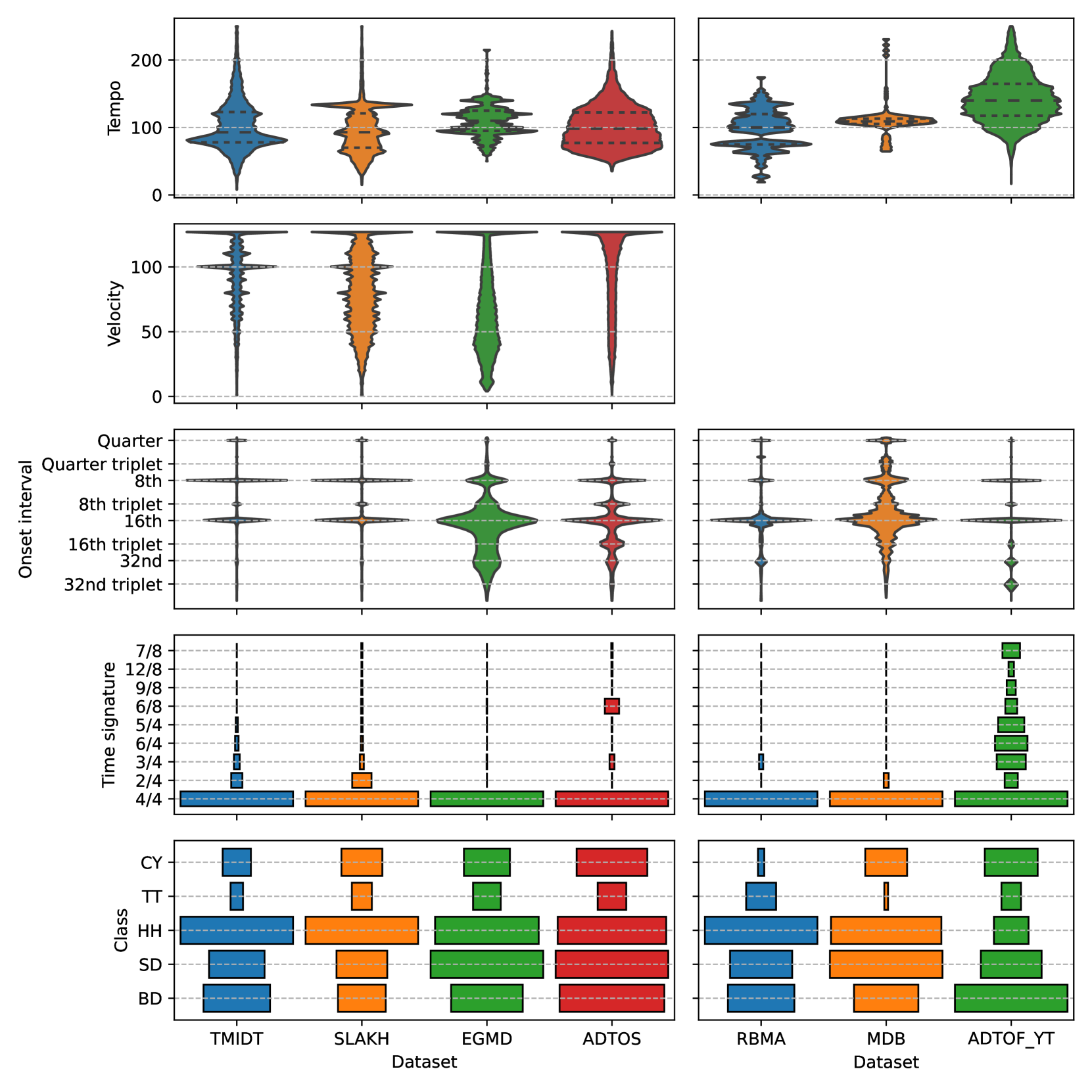
Analyzing and reducing the synthetic-to-real transfer gap in Music Information Retrieval: the task of automatic drum transcription
Mickael Zehren, Marco Alunno, Paolo Bientinesi
Automatic drum transcription is a critical tool in Music Information Retrieval for extracting and analyzing the rhythm of a music track, but it is limited by the size of the datasets available for training. A popular method used to increase the amount of data is by generating them synthetically from music scores rendered with virtual instruments. This method can produce a virtually infinite quantity of tracks, but empirical evidence shows that models trained on previously created synthetic datasets do not transfer well to real tracks. In this work, besides increasing the amount of data, we identify and evaluate three more strategies that practitioners can use to improve the realism of the generated data and, thus, narrow the synthetic-to-real transfer gap. To explore their efficacy, we used them to build a new synthetic dataset and then we measured how the performance of a model scales and, specifically, at what value it will stagnate when increasing the number of training tracks for different datasets. By doing this, we were able to prove that the aforementioned strategies contribute to make our dataset the one with the most realistic data distribution and the lowest synthetic-to-real transfer gap among the synthetic datasets we evaluated. We conclude by highlighting the limits of training with infinite data in drum transcription and we show how they can be overcome.
Read more7/30/2024
0
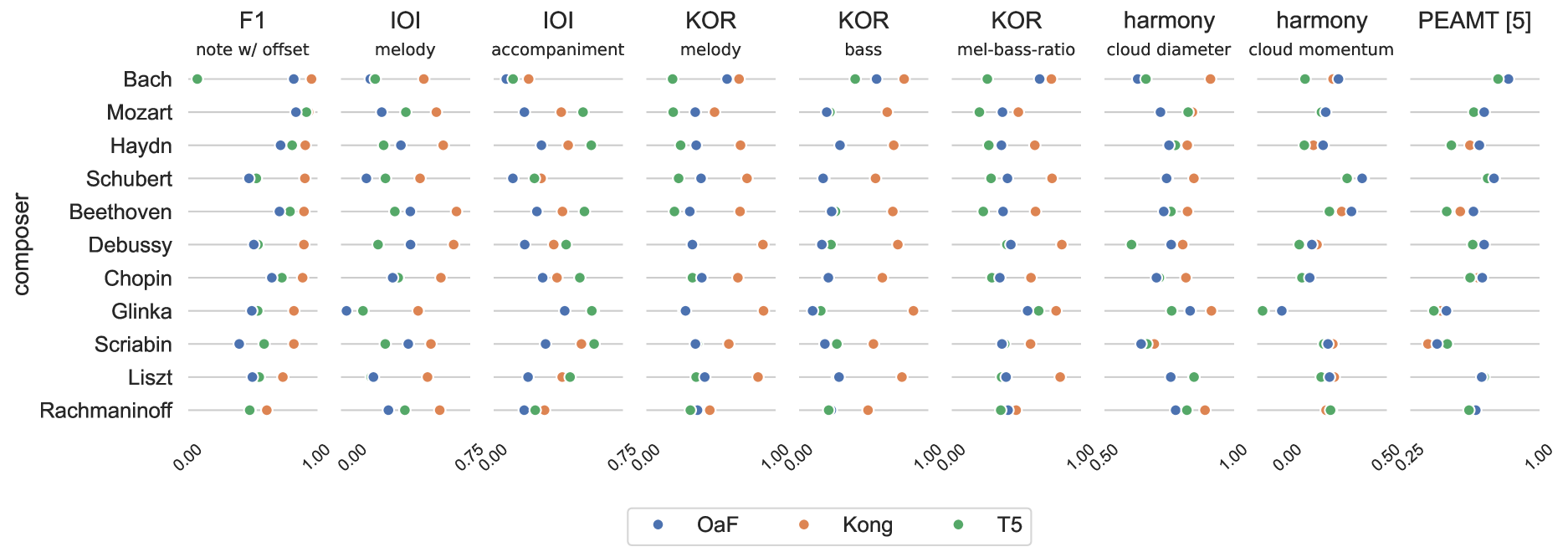
Towards Musically Informed Evaluation of Piano Transcription Models
Patricia Hu, Luk'av{s} Samuel Mart'ak, Carlos Cancino-Chac'on, Gerhard Widmer
Automatic piano transcription models are typically evaluated using simple frame- or note-wise information retrieval (IR) metrics. Such benchmark metrics do not provide insights into the transcription quality of specific musical aspects such as articulation, dynamics, or rhythmic precision of the output, which are essential in the context of expressive performance analysis. Furthermore, in recent years, MAESTRO has become the de-facto training and evaluation dataset for such models. However, inference performance has been observed to deteriorate substantially when applied on out-of-distribution data, thereby questioning the suitability and reliability of transcribed outputs from such models for specific MIR tasks. In this work, we investigate the performance of three state-of-the-art piano transcription models in two experiments. In the first one, we propose a variety of musically informed evaluation metrics which, in contrast to the IR metrics, offer more detailed insight into the musical quality of the transcriptions. In the second experiment, we compare inference performance on real-world and perturbed audio recordings, and highlight musical dimensions which our metrics can help explain. Our experimental results highlight the weaknesses of existing piano transcription metrics and contribute to a more musically sound error analysis of transcription outputs.
Read more7/30/2024

0
Applications and Advances of Artificial Intelligence in Music Generation:A Review
Yanxu Chen, Linshu Huang, Tian Gou
In recent years, artificial intelligence (AI) has made significant progress in the field of music generation, driving innovation in music creation and applications. This paper provides a systematic review of the latest research advancements in AI music generation, covering key technologies, models, datasets, evaluation methods, and their practical applications across various fields. The main contributions of this review include: (1) presenting a comprehensive summary framework that systematically categorizes and compares different technological approaches, including symbolic generation, audio generation, and hybrid models, helping readers better understand the full spectrum of technologies in the field; (2) offering an extensive survey of current literature, covering emerging topics such as multimodal datasets and emotion expression evaluation, providing a broad reference for related research; (3) conducting a detailed analysis of the practical impact of AI music generation in various application domains, particularly in real-time interaction and interdisciplinary applications, offering new perspectives and insights; (4) summarizing the existing challenges and limitations of music quality evaluation methods and proposing potential future research directions, aiming to promote the standardization and broader adoption of evaluation techniques. Through these innovative summaries and analyses, this paper serves as a comprehensive reference tool for researchers and practitioners in AI music generation, while also outlining future directions for the field.
Read more9/6/2024